资源监控系统是容器编排系统必不可少的组件,也是服务治理的核心之一。而 Prometheus 本质上是一个开源的服务监控系统和时序数据库,是 CNCF 起家的第二个项目,目前已经成为 Kubernetes 生态圈中的监控系统的核心。

Prometheus 的核心组件 Prometheus 服务器定期从静态配置的监控对象或基于服务发现自动配置的目标中拉取监控指标数据(Metrics),然后持久化到 TSDB 中。
每个被监控的目标都可以通过专用的 exporter 程序提供输出监控指标数据的接口,并等待 Prometheus 服务器定期拉取。
- 宿主机的监控数据,由 node_exporter 收集单节点平均负载、CPU、内存、磁盘、网络等信息。
- kubelet(cAdvisor):收集容器的指标数据,CPU 使用率及限额、内存使用率及限额、网络报文发送/接收/丢弃速率等。
- API server:收集 API server 的性能指标数据,包括 Controller 工作队列长度、请求的 QPS 和延迟时长、etcd 缓存工作队列及缓存性能。
- etcd:收集 etcd 存储集群的相关指标数据,包括 leader 节点及领域变动速率、提交/应用/挂起/错误的提案次数、磁盘写入性能、网络和 grpc 计数器等。
Metrics Server 部署
Kubernetes 的核心监控数据,需要通过 API server 的 /apis/metrics.k8s.io/ 路径获取,只有部署了 Metrics Server 应用程序后这个 API 才可用。
Metrics Server 是集群级别的资源利用率数据的聚合器,直接取代了 Heapster 项目。Metrics Server 并不是 API server 的一部分,而是通过 Aggregator 插件机制注册到主 API server 之上,然后基于 kubelet 的 Summary API 收集每个节点的指标数据,并存在内存里以指标 API 格式提供。

首先克隆 https://github.com/kubernetes-sigs/metrics-server 这个仓库:
$ git clone https://github.com/kubernetes-sigs/metrics-server.git
$ cd ./metrics-server
$ ll ./deploy/1.8+/
total 28
-rw-r--r--. 1 root root 397 Jan 29 19:09 aggregated-metrics-reader.yaml
-rw-r--r--. 1 root root 303 Jan 29 19:09 auth-delegator.yaml
-rw-r--r--. 1 root root 324 Jan 29 19:09 auth-reader.yaml
-rw-r--r--. 1 root root 298 Jan 29 19:09 metrics-apiservice.yaml
-rw-r--r--. 1 root root 1183 Jan 29 19:09 metrics-server-deployment.yaml
-rw-r--r--. 1 root root 297 Jan 29 19:09 metrics-server-service.yaml
-rw-r--r--. 1 root root 532 Jan 29 19:09 resource-reader.yaml
metrics-server 应用程序默认会从 kubelet 的 10250 端口基于 HTTP API 获取指标数据,如果不修改可能会导致其部署完成后无法正常获取数据。所以我们要手动修改 deploy/1.8+/metrics-server-deployment.yaml 文件的容器启动参数内容:
args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-insecure-tls
- --kubelet-preferred-address-types=InternalIP
加上 --kubelet-insecure-tls
接着创建相关资源:
$ kubectl apply -f ./deploy/1.8+/
clusterrole.rbac.authorization.k8s.io/system:aggregated-metrics-reader created
clusterrolebinding.rbac.authorization.k8s.io/metrics-server:system:auth-delegator created
rolebinding.rbac.authorization.k8s.io/metrics-server-auth-reader created
apiservice.apiregistration.k8s.io/v1beta1.metrics.k8s.io created
serviceaccount/metrics-server created
deployment.apps/metrics-server created
service/metrics-server created
clusterrole.rbac.authorization.k8s.io/system:metrics-server created
clusterrolebinding.rbac.authorization.k8s.io/system:metrics-server created
然后确认相关 Pod 运行正常:
$ kubectl get po -n kube-system | grep metrics
metrics-server-694db48df9-6vmn2 1/1 Running 0 3m57s
$ kubectl logs metrics-server-789c77976-w7dzh -n kube-system
I0129 12:33:27.461161 1 serving.go:312] Generated self-signed cert (/tmp/apiserver.crt, /tmp/apiserver.key)
I0129 12:33:27.793251 1 secure_serving.go:116] Serving securely on [::]:4443
验证相关 API 群组 metrics.k8s.io 出现在 API 群组列表中:
$ kubectl api-versions | grep metrics
metrics.k8s.io/v1beta1
最后检查资源指标 API 的可用性:
$ kubectl get --raw "/apis/metrics.k8s.io/v1beta1/nodes" | jq .
{
"kind": "NodeMetricsList",
"apiVersion": "metrics.k8s.io/v1beta1",
"metadata": {
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes"
},
"items": [
{
"metadata": {
"name": "kube",
"selfLink": "/apis/metrics.k8s.io/v1beta1/nodes/kube",
"creationTimestamp": "2020-01-29T12:42:08Z"
},
"timestamp": "2020-01-29T12:41:25Z",
"window": "30s",
"usage": {
"cpu": "256439678n",
"memory": "2220652Ki"
}
}
]
}
kubectl get --raw命令可以直接指定 API 也就是 URL 路径。
Prometheus 手动部署
因为最新的版本官方将https://github.com/coreos/prometheus-operator/tree/master/contrib/kube-prometheus独立成kube-prometheus项目,所以部署流程分成两步:
prometheus-operator 部署
克隆 https://github.com/coreos/prometheus-operator 仓库:
$ git clone https://github.com/coreos/prometheus-operator.git
$ cd ./prometheus-operator
$ git checkout release-0.35
$ kubectl apply -f bundle.yaml
clusterrolebinding.rbac.authorization.k8s.io/prometheus-operator created
clusterrole.rbac.authorization.k8s.io/prometheus-operator created
deployment.apps/prometheus-operator created
serviceaccount/prometheus-operator created
service/prometheus-operator created
然后确认相关 Pod 运行正常:
$ kubectl get po | grep prometheus-operator
prometheus-operator-79fb6fb57d-hs7hk 1/1 Running 0 104s
检查相关 CRD 资源:
$ kubectl get crd | grep monitoring
alertmanagers.monitoring.coreos.com 2020-01-29T14:55:41Z
podmonitors.monitoring.coreos.com 2020-01-29T14:55:41Z
prometheuses.monitoring.coreos.com 2020-01-29T14:55:41Z
prometheusrules.monitoring.coreos.com 2020-01-29T14:55:41Z
servicemonitors.monitoring.coreos.com 2020-01-29T14:55:41Z
监控套装部署
$ git clone https://github.com/coreos/kube-prometheus.git
$ cd ./kube-prometheus
$ ll manifests/
total 1620
-rw-r--r--. 1 root root 384 Jan 29 18:52 alertmanager-alertmanager.yaml
-rw-r--r--. 1 root root 792 Jan 29 18:52 alertmanager-secret.yaml
-rw-r--r--. 1 root root 96 Jan 29 18:52 alertmanager-serviceAccount.yaml
# ...
在部署之前我们需要创建一个名为 monitoring 的命名空间 kubectl create ns monitoring。
接着创建相关资源:
$ kubectl apply -f manifests/
alertmanager.monitoring.coreos.com/main created
secret/alertmanager-main created
service/alertmanager-main created
# ...
我们可以看到创建了很多对象,其中包括 kube-state-metrics、node-exporter、alertmanager、grafana、prometheus。
然后确认相关 Pod 运行正常:
$ kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-main-0 2/2 Running 0 3m29s
alertmanager-main-1 2/2 Running 0 3m29s
alertmanager-main-2 2/2 Running 0 3m29s
grafana-76b8d59b9b-2zkfr 1/1 Running 0 3m29s
kube-state-metrics-959876458-kxbwp 3/3 Running 0 3m28s
node-exporter-kt59s 2/2 Running 0 3m28s
prometheus-adapter-5cd5798d96-xblsg 1/1 Running 0 3m29s
prometheus-k8s-0 3/3 Running 1 3m29s
prometheus-k8s-1 3/3 Running 1 3m29s
$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-main ClusterIP 10.103.188.104 <none> 9093/TCP 8m10s
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 8m10s
grafana ClusterIP 10.103.137.213 <none> 3000/TCP 8m9s
kube-state-metrics ClusterIP None <none> 8443/TCP,9443/TCP 8m9s
node-exporter ClusterIP None <none> 9100/TCP 8m9s
prometheus-adapter ClusterIP 10.100.219.119 <none> 443/TCP 8m9s
prometheus-k8s ClusterIP 10.105.64.90 <none> 9090/TCP 8m9s
prometheus-operated ClusterIP None <none> 9090/TCP 8m9s
要想在集群外访问 prometheus 和 grafana,最简单的方法是通过 NodePort 类型的服务对外暴露:
$ kubectl patch svc prometheus-k8s -n monitoring --patch '{"spec": {"type": "NodePort"}}'
$ kubectl patch svc grafana -n monitoring --patch '{"spec": {"type": "NodePort"}}'
$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
grafana NodePort 10.103.137.213 <none> 3000:31959/TCP 17m
prometheus-k8s NodePort 10.105.64.90 <none> 9090:31228/TCP 17m
查看 prometheus 的 target 页面:
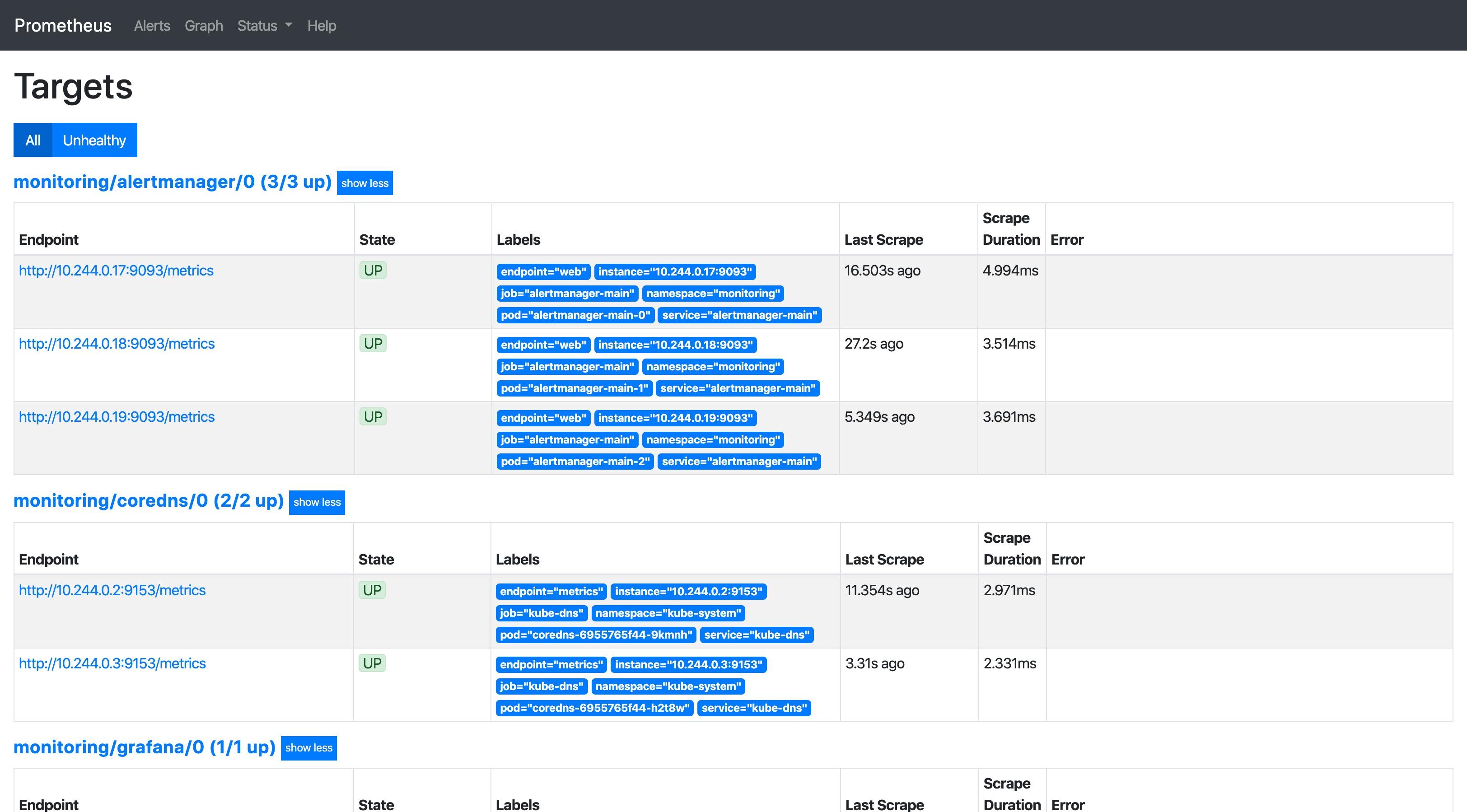
PromQL(Prometheus Query Language)是 Prometheus 专有的数据查询语言(DSL),其提供了简洁且贴近自然语言的语法实现了时序数据的分析计算能力。
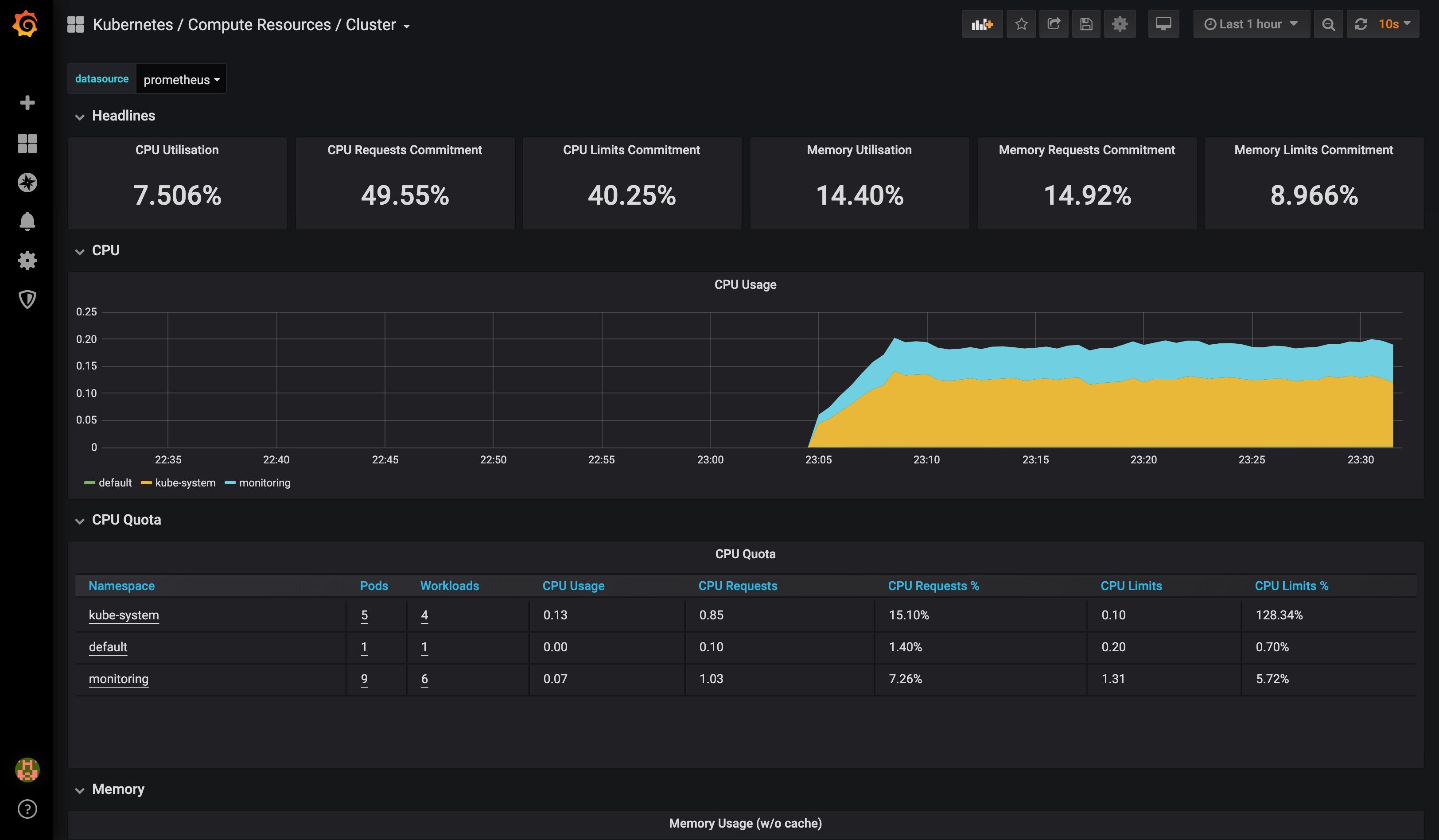
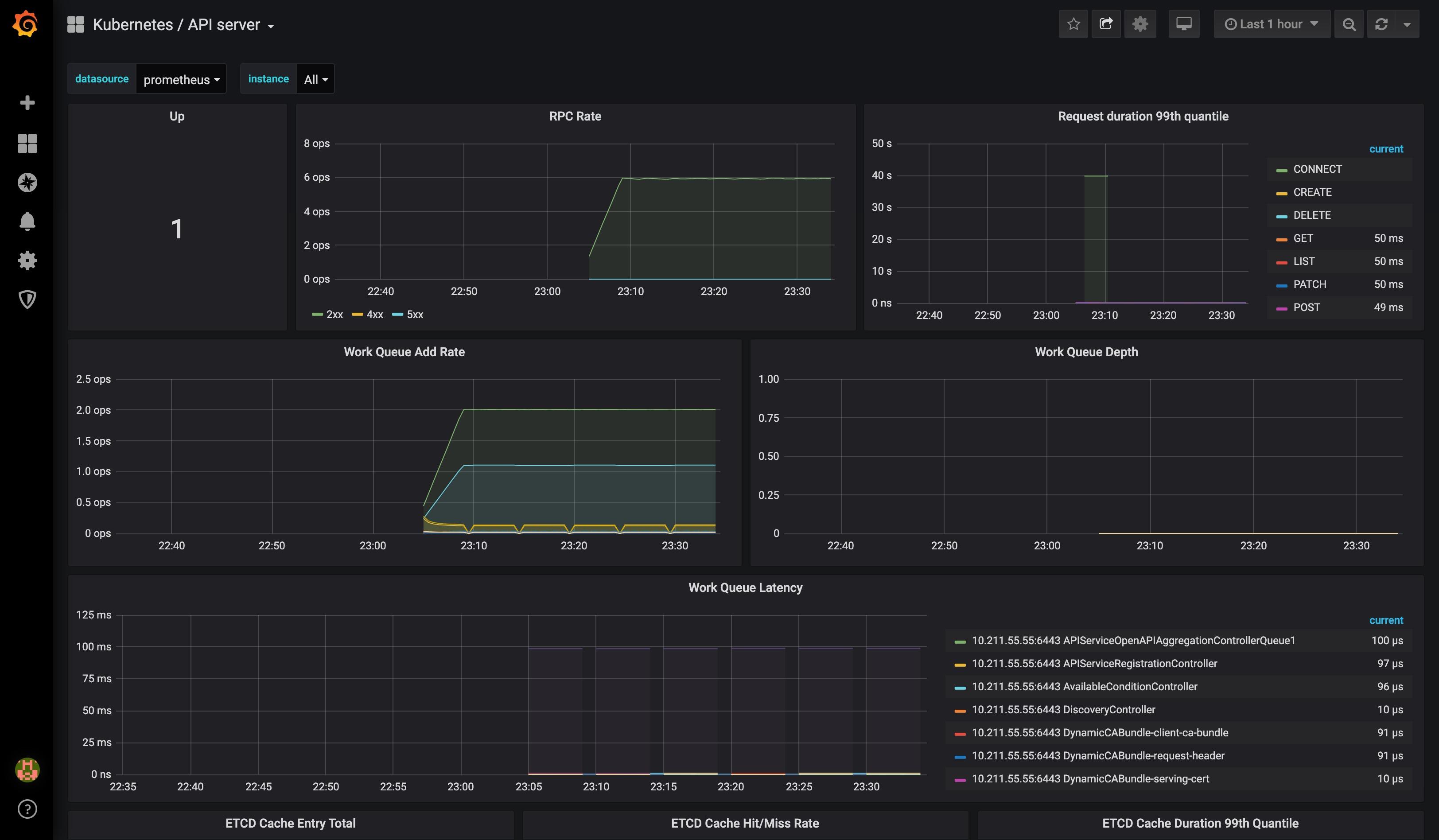
查看 grafana 相关页面:

首次登陆 grafana 使用 admin:admin。
Prometheus Helm 部署
安装 Helm
- 根据操作系统选择目标版本:https://github.com/helm/helm/releases
- 解压
tar -zxvf helm-v3.0.0-linux-amd64.tar.gz - 将 helm 二进制执行文件移动至 /usr/local/bin/ 路径下
mv linux-amd64/helm /usr/local/bin/helm - 初始化 Chart 仓库
helm repo add stable https://kubernetes-charts.storage.googleapis.com/
$ helm search repo stable
NAME CHART VERSION APP VERSION DESCRIPTION
stable/acs-engine-autoscaler 2.2.2 2.1.1 DEPRECATED Scales worker nodes within agent pools
stable/aerospike 0.3.2 v4.5.0.5 A Helm chart for Aerospike in Kubernetes
stable/airflow 5.2.5 1.10.4 Airflow is a platform to programmatically autho...
stable/ambassador 5.3.0 0.86.1 A Helm chart for Datawire Ambassador
# ...
监控套装部署
与手动部署一样,我们将在 monitoring 命名空间下部署监控套装:
$ kubectl create ns monitoring
namespace/monitoring created
$ helm install prometheus-operator stable/prometheus-operator -n monitoring
manifest_sorter.go:175: info: skipping unknown hook: "crd-install"
manifest_sorter.go:175: info: skipping unknown hook: "crd-install"
manifest_sorter.go:175: info: skipping unknown hook: "crd-install"
manifest_sorter.go:175: info: skipping unknown hook: "crd-install"
manifest_sorter.go:175: info: skipping unknown hook: "crd-install"
NAME: prometheus-operator
LAST DEPLOYED: Thu Jan 30 13:44:20 2020
NAMESPACE: default
STATUS: deployed
REVISION: 1
NOTES:
The Prometheus Operator has been installed. Check its status by running:
kubectl --namespace default get pods -l "release=prometheus-operator"
Visit https://github.com/coreos/prometheus-operator for instructions on how
to create & configure Alertmanager and Prometheus instances using the Operator.
检查相关 CRD 资源:
$ kubectl get crd
NAME CREATED AT
alertmanagers.monitoring.coreos.com 2020-01-30T05:44:17Z
podmonitors.monitoring.coreos.com 2020-01-30T05:44:17Z
prometheuses.monitoring.coreos.com 2020-01-30T05:44:17Z
prometheusrules.monitoring.coreos.com 2020-01-30T05:44:17Z
servicemonitors.monitoring.coreos.com 2020-01-30T05:44:17Z
然后确认相关 Pod 运行正常:
$ kubectl get po -n monitoring
NAME READY STATUS RESTARTS AGE
alertmanager-prometheus-operator-alertmanager-0 2/2 Running 0 32s
prometheus-operator-grafana-65dc66c89d-ch5h9 2/2 Running 0 36s
prometheus-operator-kube-state-metrics-5d4b95c886-s4l7l 1/1 Running 0 36s
prometheus-operator-operator-6748799449-ssz4h 2/2 Running 0 36s
prometheus-operator-prometheus-node-exporter-krx7d 1/1 Running 0 36s
prometheus-prometheus-operator-prometheus-0 3/3 Running 1 22s
kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
alertmanager-operated ClusterIP None <none> 9093/TCP,9094/TCP,9094/UDP 82s
prometheus-operated ClusterIP None <none> 9090/TCP 72s
prometheus-operator-alertmanager ClusterIP 10.107.102.113 <none> 9093/TCP 86s
prometheus-operator-grafana ClusterIP 10.99.155.180 <none> 80/TCP 86s
prometheus-operator-kube-state-metrics ClusterIP 10.102.159.81 <none> 8080/TCP 86s
prometheus-operator-operator ClusterIP 10.110.182.186 <none> 8080/TCP,443/TCP 86s
prometheus-operator-prometheus ClusterIP 10.103.25.36 <none> 9090/TCP 86s
prometheus-operator-prometheus-node-exporter ClusterIP 10.104.41.87 <none> 9100/TCP 86s
同样我们通过 NodePort 类型的服务将 prometheus 和 grafana 对外暴露:
$ kubectl patch svc prometheus-operator-prometheus -n monitoring --patch '{"spec": {"type": "NodePort"}}'
$ kubectl patch svc prometheus-operator-grafana -n monitoring --patch '{"spec": {"type": "NodePort"}}'
$ kubectl get svc -n monitoring
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-operator-grafana NodePort 10.99.155.180 <none> 80:32055/TCP 5m26s
prometheus-operator-prometheus NodePort 10.103.25.36 <none> 9090:32640/TCP 5m26s
通过 Helm 部署的 grafana 首次登陆使用 admin:prom-operator。