目录
前言
当今,深度学习在各个领域展现出了惊人的应用潜力,而游戏开发领域也不例外。俄罗斯方块作为经典的益智游戏,一直以来深受玩家喜爱。在这个项目中,我将深度学习与游戏开发相结合,通过使用PyTorch,为俄罗斯方块赋予了智能化的能力。
这个深度学习项目的目标是训练一个模型,使其能够自动玩俄罗斯方块,并且在游戏中取得高分。通过使用神经网络,我以游戏的状态作为输入,然后模型将预测最佳的移动策略,从而使方块能够正确地落下并消除行。通过反复训练和优化,我希望能够让模型达到专业玩家的水平,并且掌握一些高级策略。
本博客将详细介绍我在这个项目中所采用的深度学习方法和技术。我将分享我的代码实现,并解释我在训练过程中所遇到的挑战和解决方案。无论你是对深度学习感兴趣还是对俄罗斯方块情有独钟,这个项目都能够给你带来一些启发和思考。
我相信通过将深度学习和游戏开发相结合,我们能够为游戏带来全新的可能性。让我们一起探索这个项目,看看深度学习如何在俄罗斯方块这个经典游戏中展现其强大的应用能力吧!
模型成果演示
Pytorch个人学习记录总结 俄罗斯方块の深度学习小项目
训练过程演示
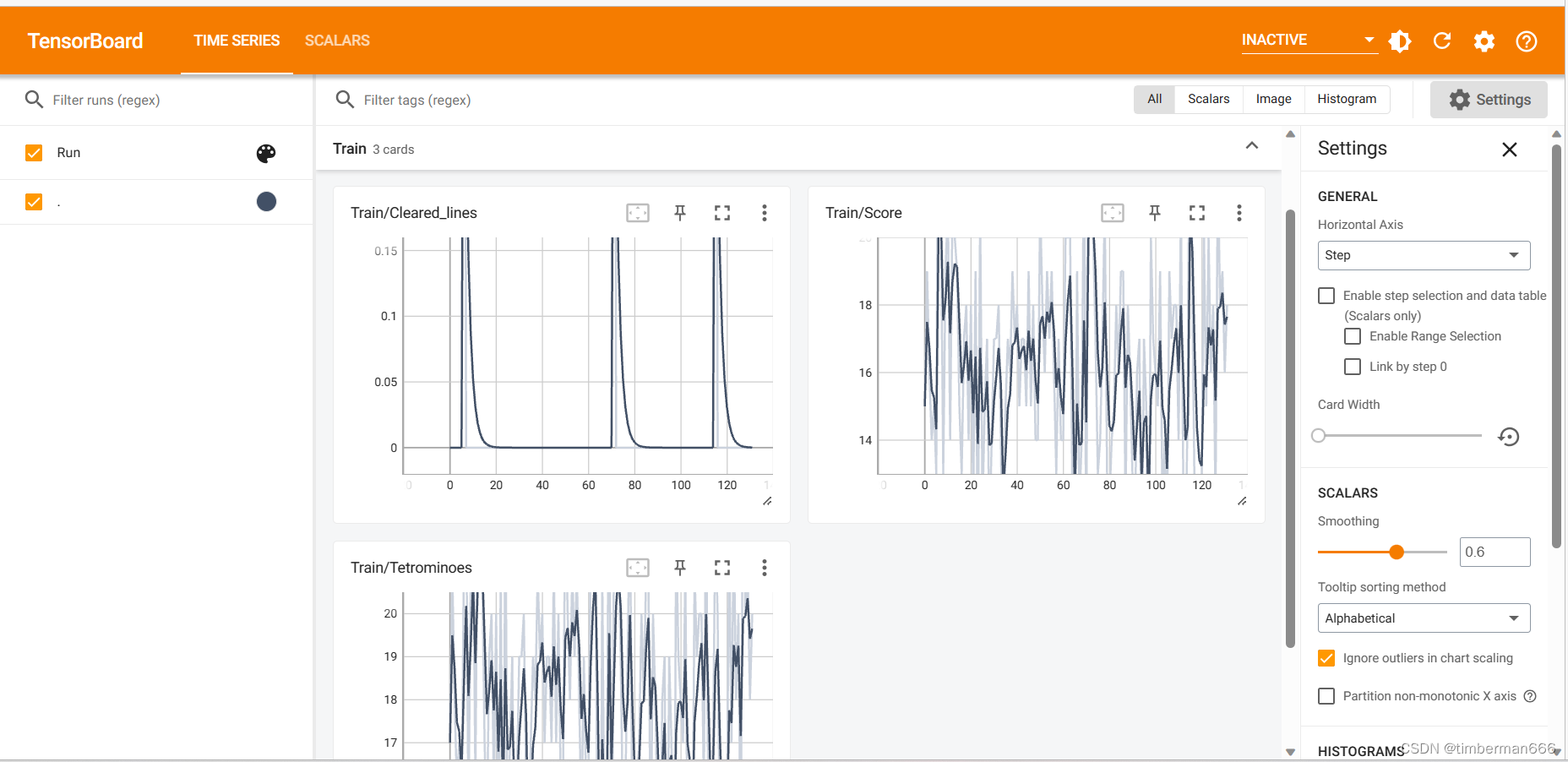
Pytorch个人学习记录总结 俄罗斯方块の深度学习小项目
代码实现
deep_network
import torch.nn as nn
class DeepQNetwork(nn.Module):
def __init__(self):
super(DeepQNetwork, self).__init__()
self.conv1 = nn.Sequential(nn.Linear(4, 64), nn.ReLU(inplace=True))
self.conv2 = nn.Sequential(nn.Linear(64, 64), nn.ReLU(inplace=True))
self.conv3 = nn.Sequential(nn.Linear(64, 1))
self._create_weights()
def _create_weights(self):
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
return x
tetris
import numpy as np
from PIL import Image
import cv2
from matplotlib import style
import torch
import random
style.use("ggplot")
class Tetris:
piece_colors = [
(0, 0, 0),
(255, 255, 0),
(147, 88, 254),
(54, 175, 144),
(255, 0, 0),
(102, 217, 238),
(254, 151, 32),
(0, 0, 255)
]
pieces = [
[[1, 1],
[1, 1]],
[[0, 2, 0],
[2, 2, 2]],
[[0, 3, 3],
[3, 3, 0]],
[[4, 4, 0],
[0, 4, 4]],
[[5, 5, 5, 5]],
[[0, 0, 6],
[6, 6, 6]],
[[7, 0, 0],
[7, 7, 7]]
]
def __init__(self, height=20, width=10, block_size=20):
self.height = height
self.width = width
self.block_size = block_size
self.extra_board = np.ones((self.height * self.block_size, self.width * int(self.block_size / 2), 3),
dtype=np.uint8) * np.array([204, 204, 255], dtype=np.uint8)
self.text_color = (200, 20, 220)
self.reset()
def reset(self):
self.board = [[0] * self.width for _ in range(self.height)]
self.score = 0
self.tetrominoes = 0
self.cleared_lines = 0
self.bag = list(range(len(self.pieces)))
random.shuffle(self.bag)
self.ind = self.bag.pop()
self.piece = [row[:] for row in self.pieces[self.ind]]
self.current_pos = {"x": self.width // 2 - len(self.piece[0]) // 2, "y": 0}
self.gameover = False
return self.get_state_properties(self.board)
def rotate(self, piece):
num_rows_orig = num_cols_new = len(piece)
num_rows_new = len(piece[0])
rotated_array = []
for i in range(num_rows_new):
new_row = [0] * num_cols_new
for j in range(num_cols_new):
new_row[j] = piece[(num_rows_orig - 1) - j][i]
rotated_array.append(new_row)
return rotated_array
def get_state_properties(self, board):
lines_cleared, board = self.check_cleared_rows(board)
holes = self.get_holes(board)
bumpiness, height = self.get_bumpiness_and_height(board)
return torch.FloatTensor([lines_cleared, holes, bumpiness, height])
def get_holes(self, board):
num_holes = 0
for col in zip(*board):
row = 0
while row < self.height and col[row] == 0:
row += 1
num_holes += len([x for x in col[row + 1:] if x == 0])
return num_holes
def get_bumpiness_and_height(self, board):
board = np.array(board)
mask = board != 0
invert_heights = np.where(mask.any(axis=0), np.argmax(mask, axis=0), self.height)
heights = self.height - invert_heights
total_height = np.sum(heights)
currs = heights[:-1]
nexts = heights[1:]
diffs = np.abs(currs - nexts)
total_bumpiness = np.sum(diffs)
return total_bumpiness, total_height
def get_next_states(self):
states = {}
piece_id = self.ind
curr_piece = [row[:] for row in self.piece]
if piece_id == 0: # O piece
num_rotations = 1
elif piece_id == 2 or piece_id == 3 or piece_id == 4:
num_rotations = 2
else:
num_rotations = 4
for i in range(num_rotations):
valid_xs = self.width - len(curr_piece[0])
for x in range(valid_xs + 1):
piece = [row[:] for row in curr_piece]
pos = {"x": x, "y": 0}
while not self.check_collision(piece, pos):
pos["y"] += 1
self.truncate(piece, pos)
board = self.store(piece, pos)
states[(x, i)] = self.get_state_properties(board)
curr_piece = self.rotate(curr_piece)
return states
def get_current_board_state(self):
board = [x[:] for x in self.board]
for y in range(len(self.piece)):
for x in range(len(self.piece[y])):
board[y + self.current_pos["y"]][x + self.current_pos["x"]] = self.piece[y][x]
return board
def new_piece(self):
if not len(self.bag):
self.bag = list(range(len(self.pieces)))
random.shuffle(self.bag)
self.ind = self.bag.pop()
self.piece = [row[:] for row in self.pieces[self.ind]]
self.current_pos = {"x": self.width // 2 - len(self.piece[0]) // 2,
"y": 0
}
if self.check_collision(self.piece, self.current_pos):
self.gameover = True
def check_collision(self, piece, pos):
future_y = pos["y"] + 1
for y in range(len(piece)):
for x in range(len(piece[y])):
if future_y + y > self.height - 1 or self.board[future_y + y][pos["x"] + x] and piece[y][x]:
return True
return False
def truncate(self, piece, pos):
gameover = False
last_collision_row = -1
for y in range(len(piece)):
for x in range(len(piece[y])):
if self.board[pos["y"] + y][pos["x"] + x] and piece[y][x]:
if y > last_collision_row:
last_collision_row = y
if pos["y"] - (len(piece) - last_collision_row) < 0 and last_collision_row > -1:
while last_collision_row >= 0 and len(piece) > 1:
gameover = True
last_collision_row = -1
del piece[0]
for y in range(len(piece)):
for x in range(len(piece[y])):
if self.board[pos["y"] + y][pos["x"] + x] and piece[y][x] and y > last_collision_row:
last_collision_row = y
return gameover
def store(self, piece, pos):
board = [x[:] for x in self.board]
for y in range(len(piece)):
for x in range(len(piece[y])):
if piece[y][x] and not board[y + pos["y"]][x + pos["x"]]:
board[y + pos["y"]][x + pos["x"]] = piece[y][x]
return board
def check_cleared_rows(self, board):
to_delete = []
for i, row in enumerate(board[::-1]):
if 0 not in row:
to_delete.append(len(board) - 1 - i)
if len(to_delete) > 0:
board = self.remove_row(board, to_delete)
return len(to_delete), board
def remove_row(self, board, indices):
for i in indices[::-1]:
del board[i]
board = [[0 for _ in range(self.width)]] + board
return board
def step(self, action, render=True, video=None):
x, num_rotations = action
self.current_pos = {"x": x, "y": 0}
for _ in range(num_rotations):
self.piece = self.rotate(self.piece)
while not self.check_collision(self.piece, self.current_pos):
self.current_pos["y"] += 1
if render:
self.render(video)
overflow = self.truncate(self.piece, self.current_pos)
if overflow:
self.gameover = True
self.board = self.store(self.piece, self.current_pos)
lines_cleared, self.board = self.check_cleared_rows(self.board)
score = 1 + (lines_cleared ** 2) * self.width
self.score += score
self.tetrominoes += 1
self.cleared_lines += lines_cleared
if not self.gameover:
self.new_piece()
if self.gameover:
self.score -= 2
return score, self.gameover
def render(self, video=None):
if not self.gameover:
img = [self.piece_colors[p] for row in self.get_current_board_state() for p in row]
else:
img = [self.piece_colors[p] for row in self.board for p in row]
img = np.array(img).reshape((self.height, self.width, 3)).astype(np.uint8)
img = img[..., ::-1]
img = Image.fromarray(img, "RGB")
img = img.resize((self.width * self.block_size, self.height * self.block_size), 0)
img = np.array(img)
img[[i * self.block_size for i in range(self.height)], :, :] = 0
img[:, [i * self.block_size for i in range(self.width)], :] = 0
img = np.concatenate((img, self.extra_board), axis=1)
cv2.putText(img, "Score:", (self.width * self.block_size + int(self.block_size / 2), self.block_size),
fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)
cv2.putText(img, str(self.score),
(self.width * self.block_size + int(self.block_size / 2), 2 * self.block_size),
fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)
cv2.putText(img, "Pieces:", (self.width * self.block_size + int(self.block_size / 2), 4 * self.block_size),
fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)
cv2.putText(img, str(self.tetrominoes),
(self.width * self.block_size + int(self.block_size / 2), 5 * self.block_size),
fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)
cv2.putText(img, "Lines:", (self.width * self.block_size + int(self.block_size / 2), 7 * self.block_size),
fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)
cv2.putText(img, str(self.cleared_lines),
(self.width * self.block_size + int(self.block_size / 2), 8 * self.block_size),
fontFace=cv2.FONT_HERSHEY_DUPLEX, fontScale=1.0, color=self.text_color)
if video:
video.write(img)
cv2.imshow("Deep Q-Learning Tetris", img)
cv2.waitKey(1)
test
import argparse
import torch
import cv2
from src.tetris import Tetris
def get_args():
parser = argparse.ArgumentParser(
"""Implementation of Deep Q Network to play Tetris""")
parser.add_argument("--width", type=int, default=10, help="The common width for all images")
parser.add_argument("--height", type=int, default=20, help="The common height for all images")
parser.add_argument("--block_size", type=int, default=30, help="Size of a block")
parser.add_argument("--fps", type=int, default=300, help="frames per second")
parser.add_argument("--saved_path", type=str, default="trained_models")
parser.add_argument("--output", type=str, default="output.mp4")
args = parser.parse_args()
return args
def run_test(opt):
if torch.cuda.is_available():
torch.cuda.manual_seed(123)
else:
torch.manual_seed(123)
if torch.cuda.is_available():
model = torch.load("{}/tetris".format(opt.saved_path))
else:
model = torch.load("{}/tetris".format(opt.saved_path), map_location=lambda storage, loc: storage)
model.eval()
env = Tetris(width=opt.width, height=opt.height, block_size=opt.block_size)
env.reset()
if torch.cuda.is_available():
model.cuda()
out = cv2.VideoWriter(opt.output, cv2.VideoWriter_fourcc(*"MJPG"), opt.fps,
(int(1.5*opt.width*opt.block_size), opt.height*opt.block_size))
while True:
next_steps = env.get_next_states()
next_actions, next_states = zip(*next_steps.items())
next_states = torch.stack(next_states)
if torch.cuda.is_available():
next_states = next_states.cuda()
predictions = model(next_states)[:, 0]
index = torch.argmax(predictions).item()
action = next_actions[index]
_, done = env.step(action, render=True, video=out)
if done:
out.release()
break
if __name__ == "__main__":
opt = get_args()
run_test(opt)
train
import argparse
import os
import shutil
from random import random, randint, sample
import numpy as np
import torch
import torch.nn as nn
from tensorboardX import SummaryWriter
from src.deep_q_network import DeepQNetwork
from src.tetris import Tetris
from collections import deque
def get_args():
parser = argparse.ArgumentParser(
"""Implementation of Deep Q Network to play Tetris""")
parser.add_argument("--width", type=int, default=10, help="The common width for all images")
parser.add_argument("--height", type=int, default=20, help="The common height for all images")
parser.add_argument("--block_size", type=int, default=30, help="Size of a block")
parser.add_argument("--batch_size", type=int, default=512, help="The number of images per batch")
parser.add_argument("--lr", type=float, default=1e-3)
parser.add_argument("--gamma", type=float, default=0.99)
parser.add_argument("--initial_epsilon", type=float, default=1)
parser.add_argument("--final_epsilon", type=float, default=1e-3)
parser.add_argument("--num_decay_epochs", type=float, default=2000)
parser.add_argument("--num_epochs", type=int, default=3000)
parser.add_argument("--save_interval", type=int, default=1000)
parser.add_argument("--replay_memory_size", type=int, default=30000,
help="Number of epoches between testing phases")
parser.add_argument("--log_path", type=str, default="tensorboard")
parser.add_argument("--saved_path", type=str, default="trained_models")
args = parser.parse_args()
return args
def train(opt):
if torch.cuda.is_available():
torch.cuda.manual_seed(123)
else:
torch.manual_seed(123)
if os.path.isdir(opt.log_path):
shutil.rmtree(opt.log_path)
os.makedirs(opt.log_path)
writer = SummaryWriter(opt.log_path)
env = Tetris(width=opt.width, height=opt.height, block_size=opt.block_size)
model = DeepQNetwork()
optimizer = torch.optim.Adam(model.parameters(), lr=opt.lr)
criterion = nn.MSELoss()
state = env.reset()
if torch.cuda.is_available():
model.cuda()
state = state.cuda()
replay_memory = deque(maxlen=opt.replay_memory_size)
epoch = 0
while epoch < opt.num_epochs:
next_steps = env.get_next_states()
# Exploration or exploitation
epsilon = opt.final_epsilon + (max(opt.num_decay_epochs - epoch, 0) * (
opt.initial_epsilon - opt.final_epsilon) / opt.num_decay_epochs)
u = random()
random_action = u <= epsilon
next_actions, next_states = zip(*next_steps.items())
next_states = torch.stack(next_states)
if torch.cuda.is_available():
next_states = next_states.cuda()
model.eval()
with torch.no_grad():
predictions = model(next_states)[:, 0]
model.train()
if random_action:
index = randint(0, len(next_steps) - 1)
else:
index = torch.argmax(predictions).item()
next_state = next_states[index, :]
action = next_actions[index]
reward, done = env.step(action, render=True)
if torch.cuda.is_available():
next_state = next_state.cuda()
replay_memory.append([state, reward, next_state, done])
if done:
final_score = env.score
final_tetrominoes = env.tetrominoes
final_cleared_lines = env.cleared_lines
state = env.reset()
if torch.cuda.is_available():
state = state.cuda()
else:
state = next_state
continue
if len(replay_memory) < opt.replay_memory_size / 10:
continue
epoch += 1
batch = sample(replay_memory, min(len(replay_memory), opt.batch_size))
state_batch, reward_batch, next_state_batch, done_batch = zip(*batch)
state_batch = torch.stack(tuple(state for state in state_batch))
reward_batch = torch.from_numpy(np.array(reward_batch, dtype=np.float32)[:, None])
next_state_batch = torch.stack(tuple(state for state in next_state_batch))
if torch.cuda.is_available():
state_batch = state_batch.cuda()
reward_batch = reward_batch.cuda()
next_state_batch = next_state_batch.cuda()
q_values = model(state_batch)
model.eval()
with torch.no_grad():
next_prediction_batch = model(next_state_batch)
model.train()
y_batch = torch.cat(
tuple(reward if done else reward + opt.gamma * prediction for reward, done, prediction in
zip(reward_batch, done_batch, next_prediction_batch)))[:, None]
optimizer.zero_grad()
loss = criterion(q_values, y_batch)
loss.backward()
optimizer.step()
print("Epoch: {}/{}, Action: {}, Score: {}, Tetrominoes {}, Cleared lines: {}".format(
epoch,
opt.num_epochs,
action,
final_score,
final_tetrominoes,
final_cleared_lines))
writer.add_scalar('Train/Score', final_score, epoch - 1)
writer.add_scalar('Train/Tetrominoes', final_tetrominoes, epoch - 1)
writer.add_scalar('Train/Cleared lines', final_cleared_lines, epoch - 1)
if epoch > 0 and epoch % opt.save_interval == 0:
torch.save(model, "{}/tetris_{}".format(opt.saved_path, epoch))
torch.save(model, "{}/tetris".format(opt.saved_path))
if __name__ == "__main__":
opt = get_args()
train(opt)