论文名称:
Deep High-Resolution Representation Learning for Visual Recognition
论文地址:
https://arxiv.org/pdf/1908.07919
官方代码下载:
https://github.com/HRNet
作者:
Jingdong Wang
发表时间:
最早发表在CVRP2019,后被顶刊TPAMI录用
HRNet简介
HighResolution Net(HRNet),顾名思义,它能够在整个过程中保持高分辨率表示,通过并行连接多分辨率,反复交换并行多分辨率子网络中的信息,通过跨分辨率的信息交互,实现高分辨率丰富语义的特征输出,实现多尺度融合。
关键特点:
1、多分辨率并行流的架构,实现了高分辨率的保持,保证了较为精确完整的空间位置信息,高分辨率和低分辨率并行连接,同步推进;
2、跨分辨率信息交互特征融合,高分辨率和低分辨率之间不断交换信息,实现语义融合,在原空间信息精确基础上,增加了丰富的语义;
HRNet网络架构

如上图所示,主要包括4个部分:
1、Stem: 处理输入图片尺寸,转换为能够输入主网络的特征图;
2、block: 指最小的特征提取单元(conv 单元) ,如图矩形框住的一个分支,由4个block组成;
3、stage: 一共有四个stage,第一个stage有一个分支(分辨率流),第n个stage有n个分支;
4、head: 决定HRNet的输出结构,对应三种输出;
主要模块:
Parallel Multi-Resolution Convolutions 并行多分辨率卷积

不同的多个分辨率feature map分支保持并行连接
分辨率拓展时机

每一个stage中的分支都包含四个block操作,运行结束后,在进入下一个stage的时候会进行分支拓展 —— 添加一个新的分辨率。
Repeated Multi-Resolution Fusions跨分辨率融合/聚合方式


上一个stage 的输出作为下一个stage前分支拓展与跨分辨率信息交互的输入。
如上图为stage3到stage4的变换图,但未包括分辨率分支拓展的部分:
1、假设输入从上到下可以定义为:H31,H32,H33,前一个3表示来自第三个stage,后一个为index
2、假设从stage3到stage4输出为:H41,H42,H43,H44,其中H44为分支拓展得到的新分辨率分支(图中并未画出来)
3、HRNet中,想得到stage4的分支,即H41,H42,H43,H44,需要利用stage3中的H31,H32,H33产生
4、HRNet的聚合方式,就是size匹配以及channel匹配后进行直接相加融合,
例如:H41 = f1(H31) + f2(H32) + f3(H33)
其中,对于H41,f1(H31) = H31 , f2和f3 则是通过1×1的卷积上采样,还原feature map大小和进行通道数变换,使得与f1(H31)一样,才能保证融合成功。
类似,H42 = f1(H31) + f2(H32) + f3(H33)
注意,此时,f1要进行3×3卷积的下采样,f2(H32) = H32 , f3要进行1×1的下采样,依旧是为了size和通道数的匹配(这里与之匹配的通道数是以H32为基准),然后融合。
Representation Head输出表示头
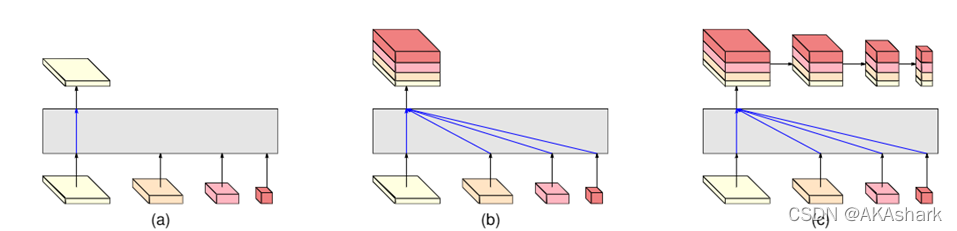
有三种表示头,如图所示,分别称为HRNetV1、HRNetV2和HRNetV2p。
a,HRNetV1,最后输出只是高分辨率特征,语义信息一般,用于人体姿态估计。
b,HRNetV2,是通过沿通道方向拼接的方式特征融合的,最后也进行了跨分辨率融合,再输出高分辨率特征。语义信息较丰富,用于语义分割。
c, HRNetV2p,先进行融合后输出高分辨的特征,再进行下采样得到多个sacle的输出,语义信息较丰富,且具有多个不同的分辨率尺度,它没有进行多次的跨分辨率的特征融合,而是只进行一次融合,然后进行下采样得到multi-scale的结果。
代码初步理解
HRnet由最基本的三种块构成。
第一种是普通的3x3的卷积它的结构如下:

def conv3x3(in_planes, out_planes, stride=1):
"""3x3 convolution with padding"""
return nn.Conv2d(in_planes, out_planes, kernel_size=3, stride=stride,
padding=1, bias=False)
第二种是BasicBlock,它的结构如下:

class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(BasicBlock, self).__init__()
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
第三种结构是三层的残差块,结构如下图。这个结构里面有一个参数叫做expansion的参数,这个参数用来控制卷积的输入输出通道数。

class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.conv1 = nn.Conv2d(inplanes, planes, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv2 = nn.Conv2d(planes, planes, kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(planes, momentum=BN_MOMENTUM)
self.conv3 = nn.Conv2d(planes, planes * self.expansion, kernel_size=1,
bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion,
momentum=BN_MOMENTUM)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
总结
初步阅读,自我感觉HRNet是个不错的backbone,未来想应用于目标检测领域,但又怕其计算量较大,消耗显存。代码比较长,阅读起来难懂,难懂的我也没写下来,未来等攻克代码,会再来修改,想了解的建议阅读官方代码。