官网
github
简介
统计机器智能和学习引擎,或者简称 Smile,是一个有前途的现代机器学习系统,在某些方面类似于 Python 的 scikit-learn。它是用 Java 开发的,也提供了 Scala API。该库将以其快速而广泛的应用程序、高效的内存使用以及大量用于分类、回归、最近邻搜索、特征选择等的机器学习算法让您惊叹不已。(截止2023-07-07,该项目在更新中)
支持算法:

使用:
还在研究,英文水平一般
其他科学领域的库介绍
2018 年数据科学领域排名前 15 的 Scala 库

在之前的文章中,我们讨论了数据科学的顶级 Python 库。这次我们将重点关注 Scala,它最近已成为数据科学家的另一种重要语言。它之所以受欢迎,主要是由于 Spark 的兴起,Spark 是一种首选的大数据处理引擎,它是用 Scala 编写的,因此在 Scala 中提供了本机 API。
我们不会在这里深入比较 Scala 与 Python,但需要注意的是,与 Python 不同,Scala 是一种编译语言。因此,用它编写的代码执行速度要快得多(与纯 Python 相比,而不是像 NumPy 这样的专用库)。
与 Java 相比,用 Scala 编写要愉快得多,因为通常可以用更少的行数来表达相同的逻辑。Scala的功能丝毫不逊色于Java,甚至有一些更高级的属性。Java 老手可能会在这里提出很多反驳意见,但毫无疑问,Scala 更适合数据科学任务。
目前,Python 和 R 仍然是快速数据分析以及构建、探索和操作强大模型的领先语言,而 Scala 正在成为开发大数据功能产品的关键语言,因为后者需要稳定性、灵活性、高速、可扩展性等。通常,在研究阶段,分析和模型是用Python完成的,然后在生产过程中用Scala实现。
为了您的方便,我们准备了用于在 Scala 中执行机器学习和数据科学任务的最重要库的全面概述。我们将使用相应的 Python 工具进行类比,以便更好地理解一些重要方面。事实上,只有一个顶级的综合工具可以构成 Scala 中数据科学和大数据解决方案开发的基础,即 Apache Spark,并辅以大量用 Scala 和 Scala 编写的库和工具。爪哇。让我们仔细看看它。
数据分析和数学
1. Breeze(提交数:3316,贡献者:84)
Breeze 被认为是 Scala 的主要科学计算库。它从 MATLAB 的数据结构和 Python 的 NumPy 类中汲取灵感。Breeze 提供快速高效的数据数组操作,并支持许多其他操作的实现,包括:
-
用于创建、转置、填充数字、进行元素运算、求逆、计算行列式以及更多其他选项的矩阵和向量运算,可以满足几乎所有需求。
-
概率和统计函数,从统计分布和计算描述性统计(例如均值、方差和标准差)到马尔可夫链模型。用于统计的主要软件包是
breeze.stats和breeze.stats.distributions -
优化,意味着研究函数的局部或全局最小值。优化方法存储在
breeze.optimize package. -
线性代数:所有基本运算都依赖于netlib-java库,使得Breeze的代数计算速度极快。
-
信号处理操作,是处理数字信号所必需的。Breeze 中重要运算的示例是卷积和傅里叶变换,它将给定函数分解为正弦和余弦分量的和。
Breeze 还提供了绘图的可能性,我们将在下面讨论。
2. Saddle(提交数:184,贡献者:10)
Scala 的另一个数据操作工具包是 Saddle。它是 R 和 Python 的 pandas 库的 Scala 类似物。与 pandas 或 R 中的数据帧一样,Saddle 基于 Frame 结构(2D 索引矩阵)。
总共有五种主要的数据结构,分别是:
-
Vec(一维向量)
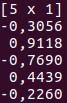
-
Mat(二维矩阵)
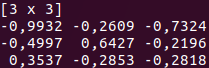
-
系列(一维索引矩阵)
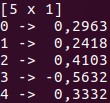
-
帧(二维索引矩阵)
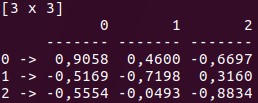
-
索引(类似哈希图)

Vec 和 Mat 类位于 Series 和 Frame 的基础上。您可以对这些数据结构实施不同的操作,并将它们用于基本的数据分析。Saddle 的另一个优点是它对缺失值的鲁棒性。/跨度>
3.Scalalab(提交数:23,贡献者:1)
ScalaLab 是 Scala 对 MATLAB 计算功能的解释。而且,ScalaLab可以直接调用和访问MATLAB脚本的结果。
与以前的计算库的主要区别在于 ScalaLab 使用自己的领域特定语言,称为 ScalaSci。Scalalab 可以方便地访问各种科学 Java 和 Scala 库,因此您可以轻松导入数据,然后使用不同的方法进行操作和计算。大多数技术与 Breeze 和 Saddle 类似。此外,与微风一样,还有绘图机会可以进一步解释结果数据。
自然语言处理
4. Epic(提交数:1790,贡献者:15)& 5. Puck(提交数:536,贡献者:1)
Scala 有一些很棒的自然语言处理库作为 ScalaNLP 的一部分,包括 Epic 和 Puck。这些库主要用作文本解析器,如果您需要解析数千个句子,由于其高速和 GPU 使用,Puck 会更方便。此外,Epic 还被称为预测框架,它采用结构化预测来构建复杂的系统。
数据科学虚拟机

可视化
6. Breeze-vis(提交数:29,贡献者:3)
顾名思义,Breeze-viz 是 Breeze 为 Scala 开发的绘图库。它基于著名的 Java 图表库 JFreeChart,并具有类似 MATLAB 的语法。尽管 Breeze-viz 的机会比 MATLAB、Python 中的 matplotlib 或 R 少得多,但它在开发和建立新模型的过程中仍然非常有帮助。
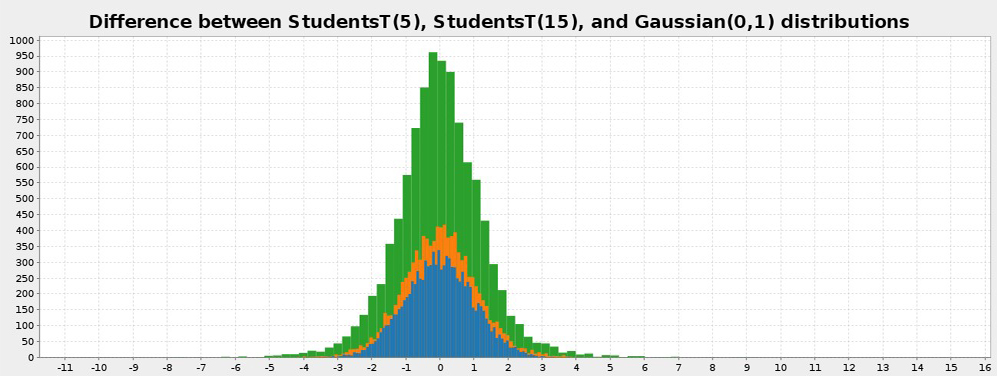
7. Vegas(提交数:210,贡献者:14)
另一个用于数据可视化的 Scala 库是 Vegas。它比 Breeze-viz 功能强大得多,并且允许制定一些绘图规范,例如过滤、转换和聚合。它在结构上与Python的Bokeh和Plotly类似。
Vegas 提供声明性可视化,使您可以主要关注指定需要对数据执行的操作并对可视化进行进一步分析,而不必担心代码实现。
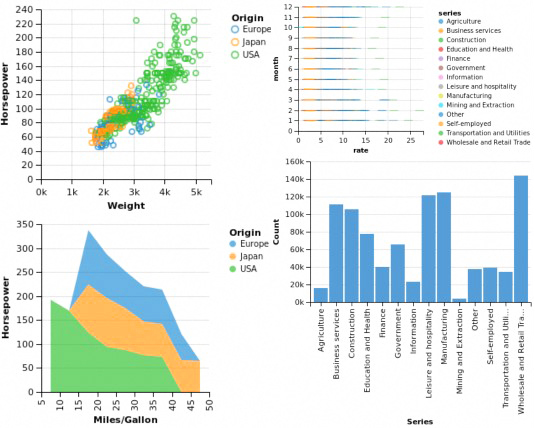
机器学习
8. Smile(提交数:1019,贡献者:21)
统计机器智能和学习引擎,或者简称 Smile,是一个有前途的现代机器学习系统,在某些方面类似于 Python 的 scikit-learn。它是用 Java 开发的,也提供了 Scala API。该库将以其快速而广泛的应用程序、高效的内存使用以及大量用于分类、回归、最近邻搜索、特征选择等的机器学习算法让您惊叹不已。

9. Apache Spark MLlib 和 ML
MLlib 库构建在 Spark 之上,提供了多种机器学习算法。它是用 Scala 编写的,还为 Java、Python 和 R 提供了功能强大的 API,但 Scala 的机会更加灵活。该库由两个独立的包组成:MLlib 和 ML。让我们一一更详细地看看它们。
-
MLlib 是一个基于 RDD 的库,包含用于分类、聚类、无监督学习技术的核心机器学习算法,并由用于实现相关性、假设检验和随机数据生成等基本统计数据的工具支持。
-
ML 是一个较新的库,与 MLlib 不同,它在数据帧和数据集上运行。该库的主要目的是提供对数据构建不同转换的管道的能力。管道可以被视为一系列阶段,其中每个阶段要么是一个 Transformer(将一个数据帧转换为另一个数据帧),要么是一个 Estimator(一种可以适应数据帧以生成 Transformer 的算法)。
每个包都有其优点和缺点,在实践中,事实证明同时应用两者通常更有效。
10.DeepLearning.scala(提交数:1647,贡献者:14)
DeepLearning.scala 是一种替代机器学习工具包,为深度学习提供高效的解决方案。它利用数学公式通过面向对象和函数式编程的组合来创建复杂的动态神经网络。该库使用广泛的类型以及应用类型类。后者允许同时开始多个计算,我们认为这对于数据科学家的处理至关重要。值得一提的是,该库的神经网络是程序,支持所有 Scala 功能。
11. Summing Bird(提交数:1772,贡献者:31)
Summingbird 是一个特定领域的数据处理框架,它允许集成批处理和在线 MapReduce 计算以及混合批处理/在线处理模式。设计该语言的主要催化剂来自 Twitter 开发人员,他们经常需要编写两次相同的代码:第一次用于批处理,然后再次用于在线处理。
Summingbird 消耗并生成两种类型的数据:流(元组的无限序列)和被视为数据集在某个时间点的完整状态的快照。最后,Summingbird 提供了 Storm、Scalding 的平台实现以及用于测试目的的内存执行引擎。
12. PredictionIO(提交数:4343,贡献者:125)
当然,我们不能忽视一个用于构建和部署预测引擎的机器学习服务器,称为PredictionIO。它基于 Apache Spark、MLlib 和 HBase 构建,甚至在 Github 上被评为最受欢迎的基于 Apache Spark 的机器学习产品。它使您能够轻松高效地构建、评估和部署引擎,实现您自己的机器学习模型,并将其合并到您的引擎中。
额外的
13.Akka(提交数:21430,贡献者:467)
Akka 由 Scala 的创建者公司开发,是一个用于在 JVM 上构建分布式应用程序的并发框架。它使用基于参与者的模型,其中参与者代表接收消息并采取适当操作的对象。Akka 取代了以前 Scala 版本中提供的 Actor 类的功能。
主要区别(也被认为是最重要的改进)是参与者和底层系统之间的附加层,它只需要参与者处理消息,而框架处理所有其他复杂情况。所有参与者都是分层排列的,从而创建一个参与者系统,帮助参与者更有效地相互交互,并通过将它们划分为更小的任务来解决复杂的问题。
14. Spray(提交数:2663,贡献者:74)
现在让我们看一下 Spray - 一套 Scala 库,用于构建基于 Akka 的 REST/HTTP Web 服务。它确保异步、非阻塞的基于 Actor 的高性能请求处理,而内部 Scala DSL 提供定义的 Web 服务行为以及高效、便捷的测试功能。
UPD:Spray 不再维护,并已被 Akka HTTP 暂停。虽然大部分库功能仍然存在,但与此位移相关的流、模块结构、路由 DSL 等方面发生了一些变化和改进。迁移指南将帮助您了解所有进展。
15. Slick(提交数:1940,贡献者:92)
我们列表中最后但并非最不重要的是 Slick,它代表 Scala 语言集成连接工具包。它是一个用于创建和执行数据库查询的库,提供各种受支持的数据库,例如 H2、MySQL、PostgreSQL 等。某些数据库可通过 slick-extensions 获得。
为了构建查询,Slick 提供了强大的 DSL,这使得代码看起来就像您在使用 Scala 集合一样。Slick 支持简单的 SQL 查询和多个表的强类型连接。此外,简单的子查询可用于构造更复杂的子查询。
结论
在本文中,我们概述了一些在执行主要数据科学任务时非常有用的 Scala 库。事实证明,它们对于实现最佳结果非常有帮助和有效。您还可以查看从 GitHub 获取的每个提供的库的活动统计信息。
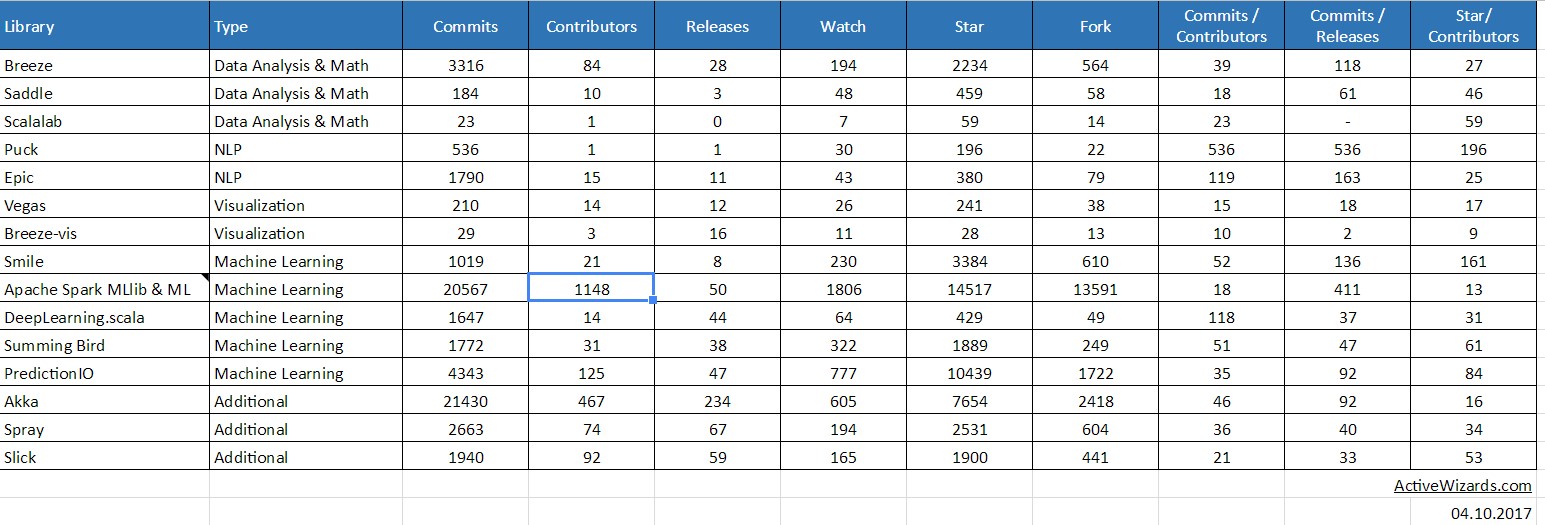
资料来源:谷歌电子表格
请注意,上面提到的列表并不全面,市场上还有许多适合不同用例的其他工具。如果您对任何其他有用的 Scala 库或框架有一些值得添加到此列表中的积极经验,请随时在下面的评论部分分享。
非常感谢您的关注与配合!