目录
前言:
这可能是全网最深入浅出的dubbo文章,如果你会spring cloud,恭喜你,你可以在读这边博文的时候类比Spring Cloud,很快就能get到整个dubbo的关键点。如果你不会Spring Cloud也不要紧,这篇博文也能带你很快了解一下dubbo。
1.概述
dubbo,Alibaba推出的开源、高性能、轻量级的RPC框架。着力于提供两方面的能力:
-
超高性能的RPC
-
服务治理
超高性能的RPC:
首先dubbo兼容市面主流的通信协议,如HTTP等,其次dubbo自定义了通信协议,内置支持 Dubbo2、Triple 两款自定义的高性能通信协议,其高效率很重要的一部分就体现在自定义的通信协议上。
服务治理:
dubbo提供了一整套服务治理能力,涵盖:
-
服务发现
-
负载均衡
-
路由
-
链路追踪
等等
dubbo的架构:
在Dubbo中,dubbo会去接管服务的提供者和消费者,然后获取服务信息、调用服务都由dubbo来负责。正是因为负责了RPC过程,所以dubbo可以在通信过程种加入很多服务的治理能力进去。

2.服务发现
服务发现指的就是服务注册与发现的整个过程,dubbo支持常见的注册中心:
Nacos、Zookeeper、Consul、Redis
注册和服务提供者会将自己的服务注册到注册中心,而服务消费者会从注册中心获取服务提供者的信息。为了减轻注册中心的负载并提高调用性能,Dubbo客户端会缓存从注册中心获取的服务提供者的地址列表或元数据信息。这样,在后续的服务调用过程中,Dubbo客户端可以直接使用本地缓存的信息,而无需每次都去注册中心查询。
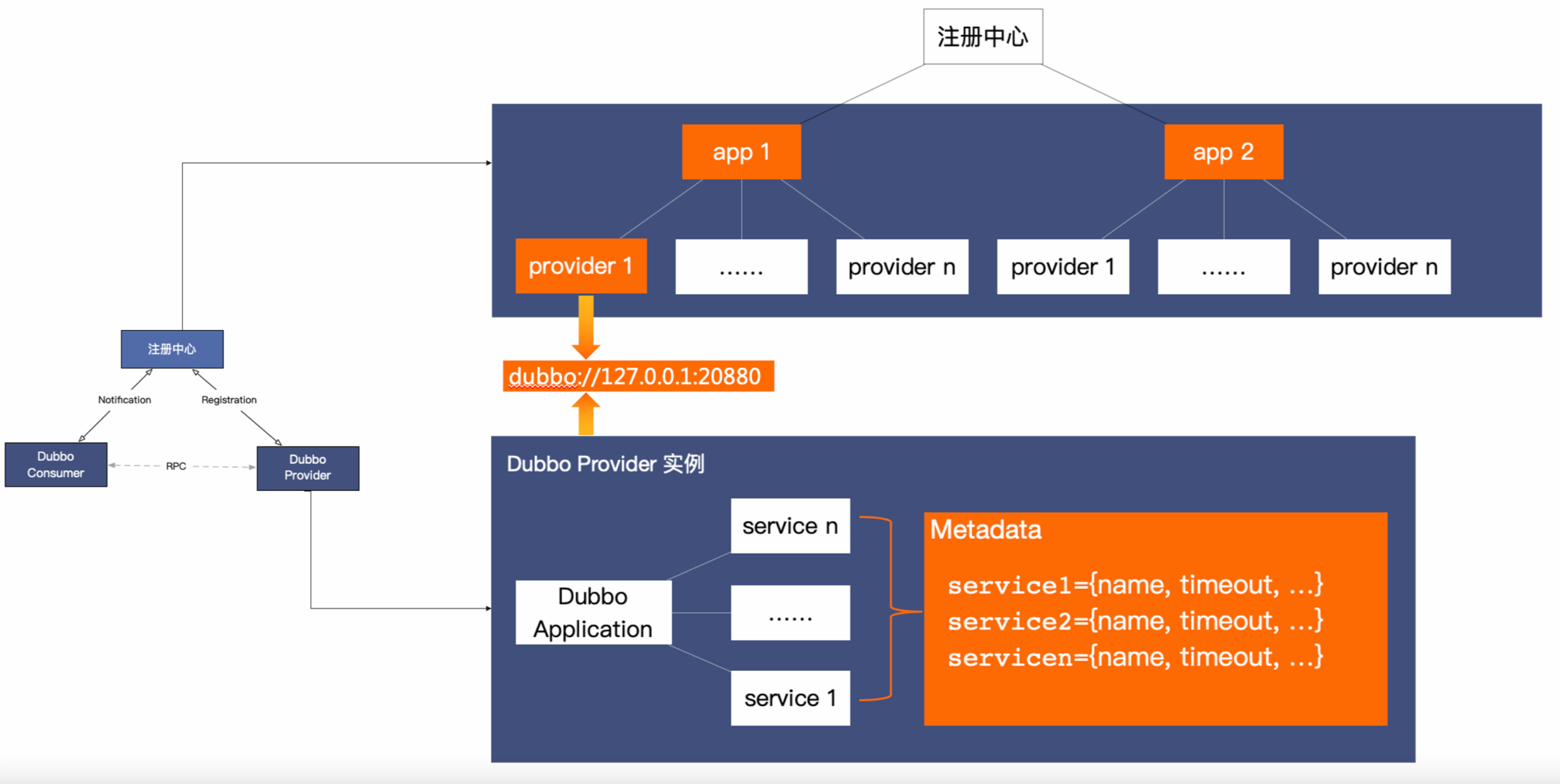
Dubbo的缓存机制是提了高性能,减少了对注册中心的依赖,但同时也可能导致一些问题,例如服务提供者的地址发生变化时,如果缓存的信息没有及时更新,可能会导致调用失败或访问旧的服务提供者。因此,在使用Dubbo时,需要合理配置和管理缓存机制,以确保系统的可用性和一致性。
在Dubbo框架中,本地缓存和注册中心同步数据的时机是在以下情况下:
-
首次访问:当服务消费者首次访问某个服务时,Dubbo客户端会从注册中心获取服务提供者的地址列表或元数据信息,并将其缓存在本地。
-
缓存过期:Dubbo客户端可以配置缓存的过期时间。当缓存中的数据过期时,Dubbo会自动触发与注册中心的同步操作,更新本地缓存的服务注册信息。
-
强制刷新:在某些情况下,你可以通过配置选项或编程方式强制刷新本地缓存。例如,当服务提供者的地址发生变化,或者你希望立即获取最新的注册信息时,可以手动触发刷新操作。
dubbo种支持通过配置或者编码的方式来强制刷新缓存。此处不做代码或者配置上的展示,因为任何开源组件,其API或者配置属性都会随着版本的迭代改变,用的时候去官网查官方文档是最为稳妥的。
当然这里只聊了基础发布,dubbo其实还支持诸如灰度发布之类的高级的服务发布方式的,详见官方手册即可。
3.容错
3.1.注册中心宕机
dubbo存在本地缓存,注册中心宕机后,服务调用会走缓存,仍然不会影响使用。
3.2.负载均衡
Dubbo 提供的是客户端负载均衡,即由 Consumer 通过负载均衡算法得出需要将请求提交到哪个 Provider 实例。
提供了多种均衡策略:
默认为 weighted random基于权重的随机负载均衡策略。
| 算法 | 特性 | 备注 |
|---|---|---|
| Weighted Random LoadBalance | 加权随机 | 默认算法,默认权重相同 |
| RoundRobin LoadBalance | 加权轮询 | 借鉴于 Nginx 的平滑加权轮询算法,默认权重相同, |
| LeastActive LoadBalance | 最少活跃优先 + 加权随机 | 背后是能者多劳的思想 |
| Shortest-Response LoadBalance | 最短响应优先 + 加权随机 | 更加关注响应速度 |
| ConsistentHash LoadBalance | 一致性哈希 | 确定的入参,确定的提供者,适用于有状态请求 |
| P2C LoadBalance | Power of Two Choice | 随机选择两个节点后,继续选择“连接数”较小的那个节点。 |
| Adaptive LoadBalance | 自适应负载均衡 | 在 P2C 算法基础上,选择二者中 load 最小的那个节点 |
以上所有负载均衡的具体代码、如何切换负载均衡策略等示例dubbo官网上的官方手册上都有详细说明,此处不做赘述。
3.3.限流、熔断
dubbo的限流和熔断通过集成第三方的组件来实现,如hystrix、Sentinel。要是又不会这两种流控组件的同学,正好博主之前有两篇优质的关于他们的文章,保证读一遍就懂:
详解Hystrix_hystrix版本__BugMan的博客-CSDN博客
详解sentinel使用_sentinel配置__BugMan的博客-CSDN博客
4.通信协议
4.1.HTTP
dubbo虽然自定义了应用层的通信协议,但是其还是支持HTTP的,具体的配置使用方法官方文档上有详细描述,此处不赘述。
4.2.dubbo
这里就是dubbo的重中之重,dubbo为什么被称为“高性能RPC框架”,很大一部分原因就是其自定义了一种高效的应用层通信协议——dubbo。
这里同学们可以先回想一下HTTP的报文结构,如果有不清楚的同学,可以移步博主的另一篇博客了解一下:
dubbo协议相比于HTTP来,其报文更加紧凑、简洁,具有更高的网络传输效率。
报文结构:

-
报文头部(Header):报文头部包含了一些元数据信息,例如魔数(Magic Number)、版本号、消息类型(请求或响应)、请求/响应ID等。这些信息用于Dubbo框架进行协议解析和消息处理。
-
报文体(Body):报文体包含了具体的请求或响应数据。对于请求消息,报文体中包含了调用的接口名称、方法名称、方法参数等。对于响应消息,报文体中包含了方法执行的结果、异常信息等。
-
序列化方式(Serialization):Dubbo报文的报文体中的数据需要进行序列化和反序列化操作。序列化方式定义了如何将Java对象转换为字节流以便在网络上传输,以及如何将字节流还原为Java对象。Dubbo框架支持多种序列化方式,例如Java自带的序列化、Hessian、JSON、Protobuf等。
-
消息编码(Codec):Dubbo报文在网络上传输时需要进行编码和解码操作。编码将报文数据转换为字节流,而解码将字节流还原为报文数据。Dubbo框架提供了多种编码方式,例如Dubbo协议的默认编码方式和其他自定义的编码方式。
-
扩展字段(Extensions):Dubbo报文还可以包含一些扩展字段,用于实现一些特定的功能或特性。例如,Dubbo报文可以通过扩展字段传递路由规则、负载均衡策略等信息。
5.总结
dubbo作为一款与spring cloud对标的产品,两者大的区别无非在两个方面:
- 生态
- 性能
1.生态:
生态上spring cloud是更加完善的,一套spring cloud全家桶,依赖引进来,啥组件都有了,而ribbon则需要自己去拼积木,对接第三方组件,拿组装电脑来类比的话,前者是水桶机,而后者是组装机,前者更方便开袋即食,后者更方便个性化定制。
2.性能:
在能上dubbo是要优于spring cloud的,这也是dubbo立足的根本。Dubbo的高性能主要体现在两点:
-
选用netty作为容器
-
自定义了报文结构
选用netty作为容器:
Dubbo底层其实是用netty来进行通信,netty的非阻塞式IO具有很高的性能。
自定义了报文结构:
netty自定义了通信协议,自定义了报文结构,比起http报文来,dubbo报文更加紧凑、简洁。其次,http报文的数据内容是文本格式的,而dubbo的数据内容是经过序列化的,dubbo报文的体积明显要小于http报文,解析速度、带宽利用率、吞吐量等指标上,dubbo明显都要由于http。