糖尿病遗传风险检测挑战赛
任务1:报名比赛
- 步骤1:报名比赛http://challenge.xfyun.cn/topic/info?type=diabetes&ch=ds22-dw-zmt05
- 下载比赛数据(点击比赛页面的赛题数据)
- 解压比赛数据,并使用pandas进行读取;
- 步骤4:查看训练集和测试集字段类型,并将数据读取代码写到博客;
代码:
train=pd.read_csv(r'D:\桌面\科大讯飞赛事\糖尿病遗传风险预测挑战赛公开数据\train.csv',encoding='gbk')
test=pd.read_csv(r'D:\桌面\科大讯飞赛事\糖尿病遗传风险预测挑战赛公开数据\test.csv',encoding='gbk')
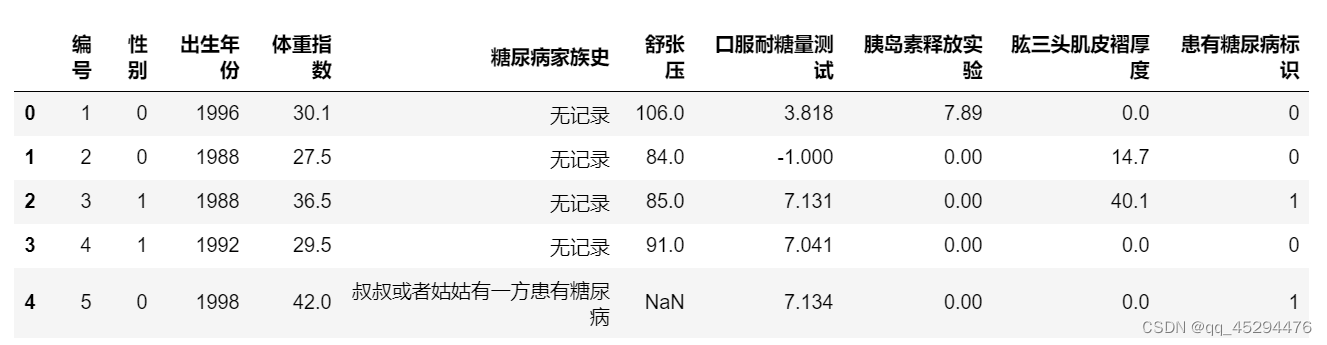
train.head()
任务2:比赛数据分析
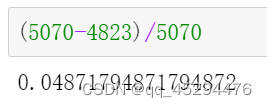
- 步骤1:统计字段的缺失值,计算缺失比例;
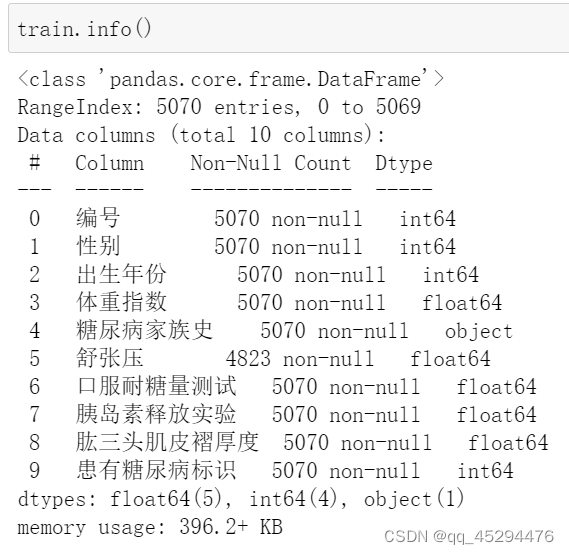
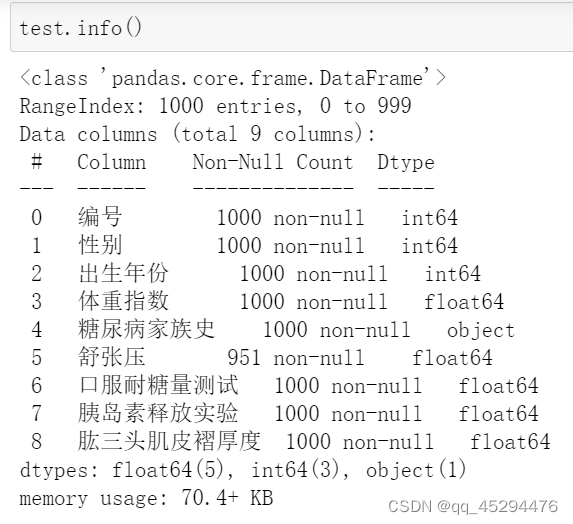
首先通过data.info()观察训练集和测试集字段信息,可以看到均只在舒张压字段存在缺失值,缺失比例大概在5%。
train.info()
test.info()
-
步骤2:分析字段的类型
‘编号’:一个标识个体身份的数字,没有实际意义。
‘性别’:1表示男性,0表示女性,共两类,为类别变量。
‘出生年份’:出生的年份,为类别变量。
‘体重指数’,:即BMI指数,为连续变量。
‘糖尿病家族史’:标识糖尿病的遗传特性,记录家族里面患有糖尿病的家属,分成三种标识,分别是父母有一方患有糖尿病、叔叔或者姑姑有一方患有糖尿病、无记录,共三类,为类别变量。
‘舒张压’:心脏舒张时,动脉血管弹性回缩时,产生的压力称为舒张压,单位mmHg,为连续变量。
‘口服耐糖量测试’:诊断糖尿病的一种实验室检查方法。比赛数据采用120分钟耐糖测试后的血糖值,单位mmol/L,为连续变量。
‘胰岛素释放实验’:空腹时定量口服葡萄糖刺激胰岛β细胞释放胰岛素。比赛数据采用服糖后120分钟的血浆胰岛素水平,单位pmol/L,为连续变量。
‘肱三头肌皮褶厚度’:在右上臂后面肩峰与鹰嘴连线的重点处,夹取与上肢长轴平行的皮褶,纵向测量,单位cm,为连续变量。
‘患有糖尿病标识’:数据标签,1表示患有糖尿病,0表示未患有糖尿病,共两类,为类别变量。 -
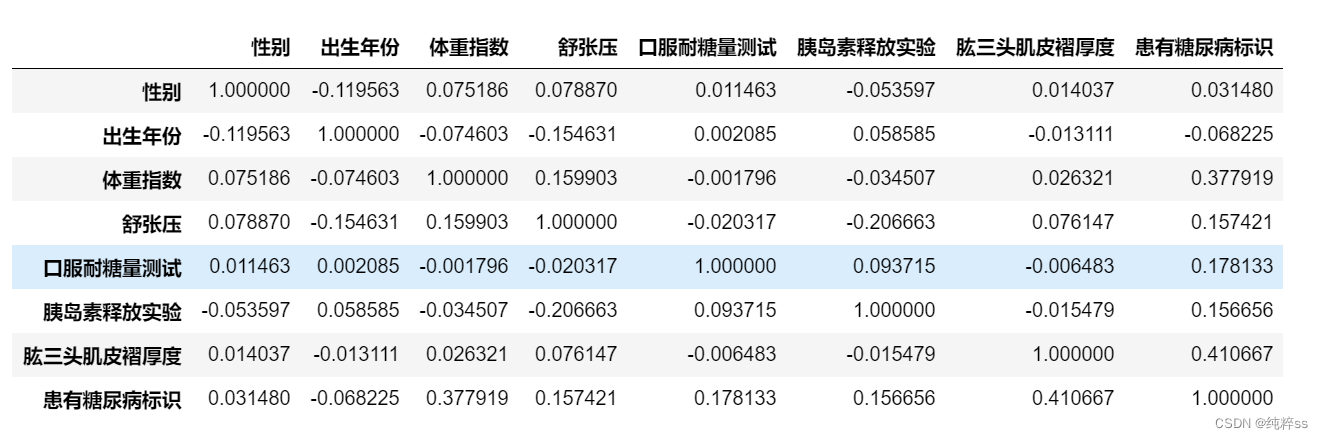
步骤3:计算字段相关性
#计算字段相关性
a = train.drop('编号',axis=1)
a.corr()
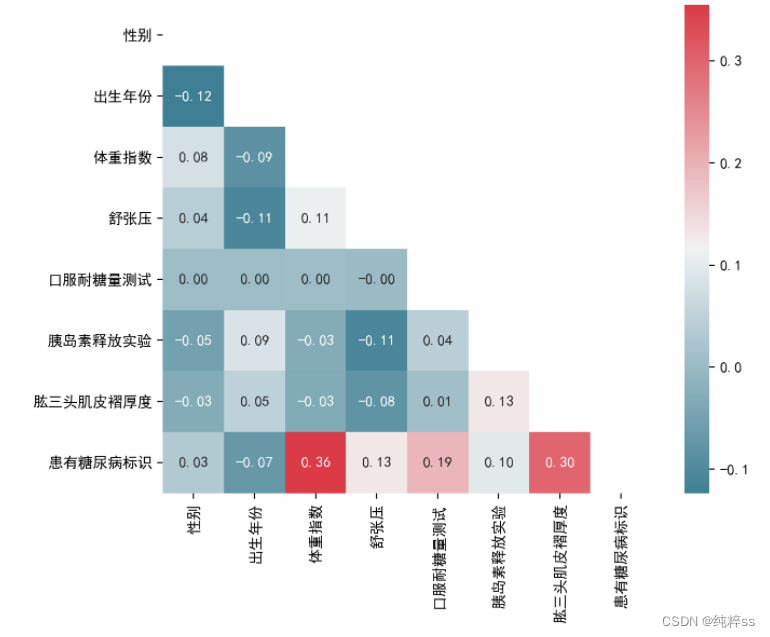
#绘制热力图进行可视化
plt.figure(figsize=(8, 6),dpi=200)
column = a.columns.tolist()
mcorr = a[column].corr(method="spearman")
mask = np.zeros_like(mcorr, dtype=np.bool)
mask[np.triu_indices_from(mask)] = True
cmap = sns.diverging_palette(220, 10, as_cmap=True)
g = sns.heatmap(mcorr, mask=mask, cmap=cmap, square=True, annot=True, fmt='0.2f')
plt.show()
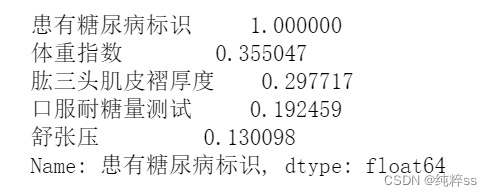
#输出与标签列相关性绝对值大于0.1的特征
mcorr=mcorr.abs()
numerical_corr=mcorr[mcorr['患有糖尿病标识']>0.1]['患有糖尿病标识']
print(numerical_corr.sort_values(ascending=False))