目录
进程创建
fork()函数
这个函数我在上一个文章已经把用法讲的很详细了,所以本文章主要是从一个更加深入的角度来看待fork().
在linux中fork函数时非常重要的函数,它从已存在进程中创建一个新进程。新进程为子进程,而原进程为父进程。
#include <unistd.h>
pid_t fork(void);
返回值:子进程中返回0,父进程返回子进程id,出错返回-1
现在我们将从一个更加系统的角度来讲解:
请描述一下,fork()创建子进程,操作系统都做了什么?
1.首先这个问题的切入点是:fork()创建子进程,系统里就会多了一个进程!
2.然后回答什么是进程:
进程 = 内核数据结构(OS) + 进程代码和数据(一般从磁盘来,也就是C/C++程序加载后的结果)
3.之后,对子进程会有以下操作:
a.分配新的内存块和数据结构给子进程
b.将父进程部分数据结构内容拷贝至子进程
c.添加子进程到系统进程列表当中
d.fork()返回,开始调度器调用.
子进程如何继承父进程的数据
创建子进程,给子进程分配对应的内核结构,必须是子进程独有,因为进程具有独立性。理论上,子进程也要有自己的代码和数据!
可以是一般而言,子进程没有加载的过程,也就是说子进程没有自己的代码和数据,所以子进程只能使用“父进程代码和数据”
这不对啊,不是说进程具有独立性吗,怎么可以使用父进程的代码和数据呢
这里也要分情况讨论:
代码:都是不可被改写的,只能读取,所以父子共享,没有问题!
数据:可能被修改,所以必须分离!
那么对于数据而言,该如何分离呢?
1.创建时拷贝分离
先来看第一种方法:创建子进程的时候,就直接拷贝分离,那这样会有什么问题呢?
1.当我们创建子进程后,我们能立马运行它吗?这是其一.
2.即便可以立马运行,你会访问所有的数据吗?这是其二.
3.即使你会访问所有的数据,那么你对所有数据的访问都是写入吗?不是写入就根本没必要拷贝.
所以这个问题是可能拷贝子进程根本就不会用到的数据空间,即便用到了,也可能只是读取!
这种情况也很好的说明了:
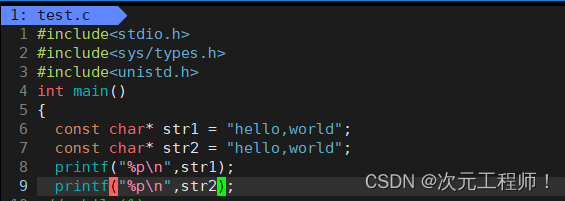
两个不同的字符串常量,当我们打印地址的时候,会发现它们的地址是一样的!
因为编译器知道这个const修饰变量里面的内容不可以被修改了,所以后面和它内容相同的变量都会直接指向它.
这个只是想告诉大家:编译器编译程序的时候,尚且知道节省空间。更何况这种直接使用内存的系统接口,会更加注重.
所以创建子进程,不需要将不会被访问或者只会读取的数据拷贝一份.
但是问题来了,什么样的数据值得拷贝,什么样的数据必须被拷贝?
一定是将来会可以被父进程或子进程写入的数据.
但是,一般而言即便是OS,也无法提前知道哪些空间可能会被写入.
但是即便知道,提前拷贝了,你会立马使用吗?
答案是那么多可被写入的数据,肯定不会,但是空间已经给你了,却不用,所以这就造成了空间的浪费.
所以OS选择了一种技术:写时拷贝.来进行父子进程的数据进行分离.
2.写时拷贝★
所以结合以上所说的,写时拷贝就是当你需要可被写入的数据时,OS再给你对应的空间.
为什么OS采用写时拷贝技术,进行父子进程数据的分离:
1.用的时候,再进行分配,是高效使用内存的一种表现.
2.OS无法在代码执行前预知哪些空间会被访问.

这里还有一个问题:
那么父进程fork()之前的代码,子进程共享吗?
答案是共享的,子进程共享父进程fork()之前所有的代码.
下面将一张图来解释.这张图我在进程概念与状态中的并发执行中也很详细的说过了.
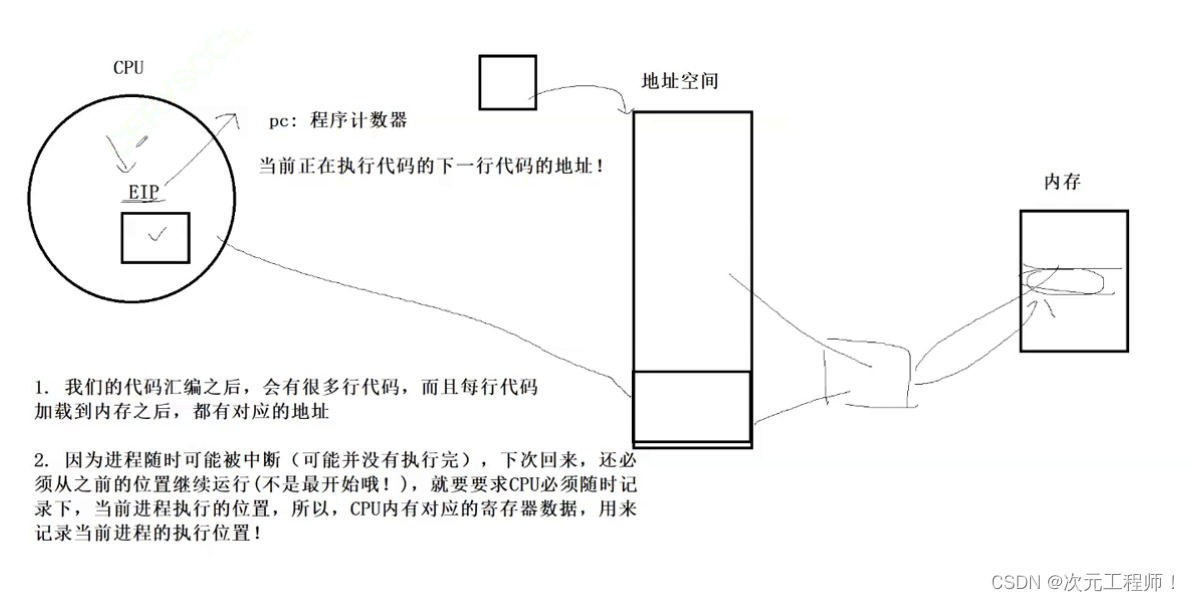
即EIP里有下一行代码的地址,这些存储的数据叫做上下文数据.
当子进程继承父进程时,发生写时拷贝,将父进程的上下文数据拷贝给了子进程.
后面父子进程虽然各自调度,代码不同,各自会修改EIP,但是已经不重要了,因为子进程已经认为自己的EIP代码起始值,就是fork()之后的代码.
所以子进程虽然是从fork()之后运行,但是不代表fork()之前的代码子进程看不到!
进程终止
进程终止时,操作系统做了什么?
我们知道一个程序运行起来变成一个进程,一个进程又有进程代码和数据 + 内核数据结构组成.
所以进程终止是要释放进程申请的内核数据结构和对应的数据和代码.本质是释放系统资源.
进程终止的常见方式
代码运行完毕,结果正确
这个情况很常见,当我们写算法题的时候,比如力扣,一个题如果结果正确,最后提交后会显示通过.
或者自己在编译器下写的,最后输出也符合我们的预期结果等等.
那不知道我们有没有注意过,main函数会有返回值,return 0,它返回值的意义是什么,为什么总会返回0?
其实main函数返回值并不总是0,只是我们平常写的时候经常写0而已.
main函数最后return的值叫做进程的退出码.
一般0代表success,表示进程运行的结果正确.
非0标识的运行结果不正确,后面会细说.
例如我们返回一个10.
然后我们利用$?来输出最近一个进程的退出码.
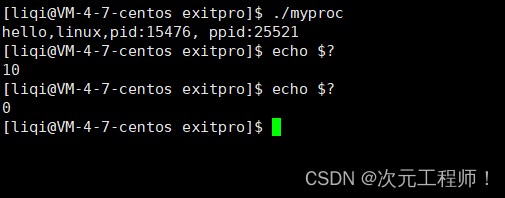
可以发现第一次运行,得到的退出码是最近返回的10.
第二次之所以是0,是因为上一次的echo $?也是一个进程,它成功执行了,所以返回0.
那么main函数返回的意义是什么呢?
用来返回给上一级进程,用来评判该进程的执行结果,可以忽略.
例如我们写一个加法求和的程序,如果答案正确就返回0,答案错误就返回1.

此时我们的sum是正确的流程,所以结果应该返回0
而当我们将sum的计算逻辑写错得不到正确结果时,便会返回1,标识程序最后的结果不正确,这也是main函数返回值的意义.
退出码★
回到刚才所说的非0退出码,非零值有无数个,可以用来标识不同的错误原因.
给我们的程序运行结束之后,方便定位错误的原因细节.
这些原因linux也定义了,我们可以打印来看一下,这里需要用到一个函数strerror()
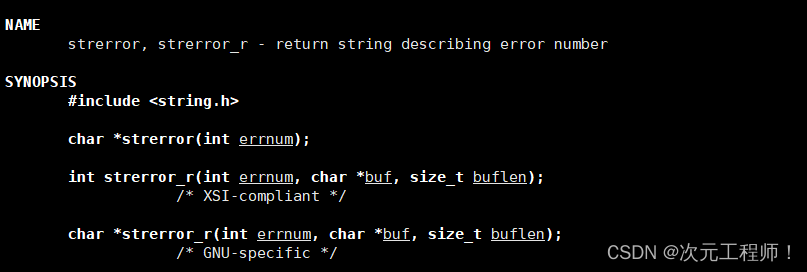
它的作用是返回错误码的字符串描述.
我们输入代码:

然后输出结果:

直至100,我们发现有很多错误类型.
当然,我们可以自己使用这些退出码和含义,但是你如果想自己定义,也可以自己设计出一套退出方案.
代码运行完毕,结果不正确
同上。
代码异常终止
程序异常终止时,退出码便在没有意义,一般而言退出码对应的return语句没有被执行!
那么程序为什么会崩溃呢?
用代码如何终止一个进程
return
首先我们知道,return 退出码 就是终止进程的,当然只有main函数内的return语句才是终止进程的.
exit和_exit★
先来man看一下介绍

看到它的作用是让进程正常终止。
然后函数参数是status,这个就是用来标识退出码的.
它与main函数不同的是:exit函数在任何地方调用,都是直接终止进程!
看下面例子:
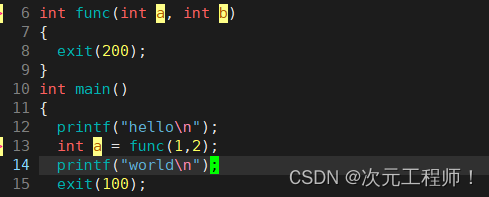
如果是return 200的话,它只会将200返回给a,程序并不会结束.
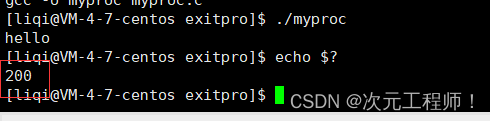
可以看到func()后面输出world语句没有被执行,而且退出码是第一次的200.
那么_exit是什么呢,又有什么区别呢?

描述了一大堆,也挺抽象的,我下面用一个例子和图片来解释它和exit的区别.
首先还是刚才的例子,我们把exit改为_exit.
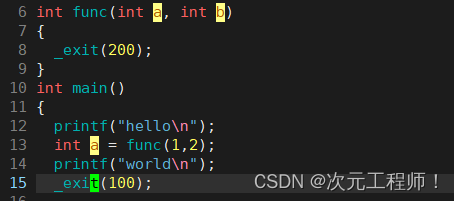
可以发现结果和exit并没有区别:
但是我们把程序换成如下这样:
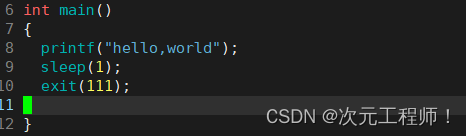
这个时候我们预期的是由于printf没有'\n'换行符进行缓冲区刷新,此时内容存储在缓冲区,所以程序运行1s后才会将内容输出到屏幕上,然后退出码返回111.

由于是静态图无法演示效果,但是是1秒后才出的结果.
但如果此时我们把exit改成_exit.

却发现什么都没有输出出来.
这里就直接说结论了,exit在程序结束时会刷新缓冲区的内容到屏幕上,而_exit是直接结束,而不会刷新缓冲区的内容.
就如如下这张图所表示的
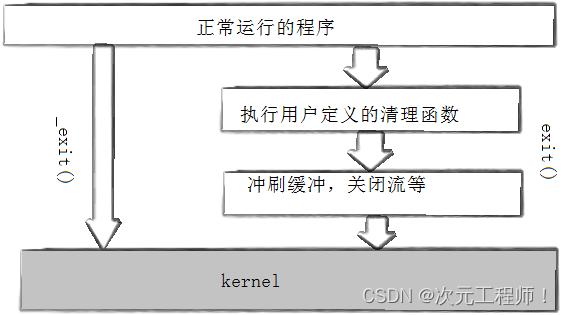
但我们平常还是推荐用exit。
我们知道库函数是封装的系统接口,而这里面的库函数其实是exit,而系统接口是_exit .
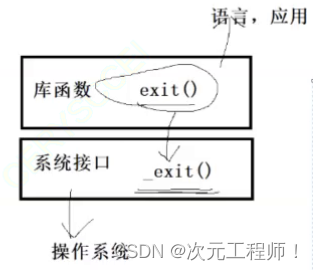
而我们平常所说的缓冲区在哪里呢,这个后面再讲,但是一定不在操作系统内部!
如果在操作系统内部,是由操作系统维护的,那么_exit也照样可以刷新出来,而它刷新不出来,说明一定不在操作系统内部,而是C语言库给我们提供的.
关于进程的创建与终止也就到此为止了.