目录
进程创建
fork原理
在Linux中fork函数非常重要,它从已经存在的进程中创建一个新的子进程。
新进程为子进程,原进程为父进程。(以父进程为模板来创建子进程)
(pcb,内存指针,程序计数器,上下文数据)从下一句代码开始执行
每个进程都有自己的虚拟地址空间,子进程复制的只是数据,虚拟地址空间父子进程各一份
,因此父子进程数据的是独有的,但是代码共享。
#include<unistd.h>
pid_t fork(void);
//返回值:子进程中返回0,父进程返回子进程的id,出错返回-1进程调用fork,当控制转移到内核中的fork代码之后,内核做:
- 分配新的内存块和内核数据结构给子进程
- 将父进程部分数据结构内容拷贝至子进程
- 添加子进程到系统进程列表中
- fork返回,开始调度器调度

当一个进程调用fork之后,就有两个二进制代码相同的进程,而且运行到相同的地方
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<errno.h>
4 int main()
5 {
6 pid_t pid;
7 printf("before:pid : %d\n",getpid());
8 pid = fork();
9 if(pid == -1)
10 {
11 perror("fork");
12 }
13 printf("after:pid :%d and fork return %d\n",getpid(),pid);
14 sleep(1);
15 return 0;
16 }

- 有三行输出,一行before,两行after进程3545先打印before还有after,另一个只有after
- 因为子进程是从fork创建之后开始运行,而不是从main函数开始运行,所以不会打印before
- fork之后父子进程两个执行流分别执行,谁先完全由调度器决定

fork函数返回值
- 子进程返回0
- 父进程返回子进程的id
为什么不能反过来?
系统提供了getpid()和getppid()可以获取当前进程和的、当前进程的父进程的id,但是无法获得子进程的id,所以父进程必须返回子进程id(才能知道子进程id)
写时拷贝:通常,父子代码共享,父子不在写入时,数据也是共享的,当任意一方试图写入时,便以写时拷贝的方式各自有一份副本
(修改时更新页表,指向新的内存区域)
fork用法和调用失败的原因
用法
- 一个父进程希望复制自己,使父子进程实现不同的代码段(例如:父进程等待客户端请求,生成子进程取处理请求)
- 一个进程要执行一个不同的程序(例如:子进程从fork返回后,调用exec函数)
调用失败原因
- 系统中有太多进程
- 实际用户的进程超过了限制
vfork函数
同样用来创建子进程,但是
- vfork用于创建一个子进程,而子进程和父进程共享地址空间(fork的子进程有独立的地址空间)
- vfork保证子进程先运行,在它调用exec或exit之后父进程才可能被调度运行
1 #include<stdio.h>
2 #include<unistd.h>
3 #include<errno.h>
4 #include<stdlib.h>
5 int i = 100;
6 int main()
7 {
8 pid_t pid = vfork();
9 if(pid == -1)
10 {
11 perror("vfork");
12 return -1;
13 }
14 else if(pid == 0)
15 {
16 i = 200;
17 printf("child: i = %d pid:%d\n",i,getpid());
18 exit(0);
19 }
20 else
21 {
22 printf("parent: i = %d pid:%d\n",i,getpid());
23 }
24
25 return 0;
26 }

- 父子进程输出都是200,可见子进程改变了父进程的变量值,因为子进程在父进程的地址空间中运行
- 子进程没有运行其他程序或者退出之前,父进程阻塞在vfork处不返回(vfork创建子进程先运行,直到exit(0)退出,父进程接着后面代码运行)
- 如果不加exit(0),则子进程一直跑完代码,return返回,但是由于父子进程共享所以资源以及释放,导致父进程死循环(调用栈以及混乱)

总结
1. fork ():子进程拷贝父进程的数据段,代码段 ,子进程有自己的虚拟地址空间,父子进程数据独有(写时拷贝)代码共享
vfork ( ):子进程与父进程共享数据段 (共享虚拟地址空间)
2. fork ()父子进程的执行次序不确定
vfork ()保证子进程先运行,在调用exec 或exit 之前与父进程数据是共享的,在它调用exec
或exit 之后父进程才可能被调度运行。
3. vfork ()保证子进程先运行,在它调用exec 或exit 之后父进程才可能被调度运行。如果在
调用这两个函数之前子进程依赖于父进程的进一步动作,则会导致死锁。
进程终止
进程退出场景:
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确
- 代码异常终止
进程常见退出方法
- 从main返回
- 调用exit
- _exit
- 异常退出(ctrl + c)
return退出
return 是一种最常见的退出方式,执行return n 相当于exit(n),因为调用main函数时将会调用main的返回值当exit的参数
_exit函数
#include<unistd.h>
void _exit(int status);
//参数:status 定义了进程的终止状态,父进程通过wait来获取该值直接释放资源(粗暴)
说明:虽然status是int,但是仅有低8位可以被父进程使用,所以_exit(-1),在终端执行时返回255
echo $? 可以获取状态返回码(0--255)仅有低8位!
exit函数
#include<unistd.h>
void exit(int status);
- exit(逐步释放资源)最后也会调用_exit,但在这之前,会做其他工作
- 先执行用户通过atexit或on_exit定义的清理函数
- 关闭所有打开的流,所有缓存数据均被写入
- 调用_exit

具体区别如下:逐步释放和粗暴释放

总结:
return:只有在main中执行还会退出进程,在main中return跟调用exit效果一样
exit:在任意位置都可以退出进程,退出前会刷新缓冲,关闭文件,做很多操作
_exit:粗暴的退出进程,什么也不干,直接释放资源
进程等待
进程等待的重要性
- 子进程退出,父进程不管不顾可能会造成僵尸进程的问题,而造成内存泄漏
- 一旦变成僵尸状态,就很难杀死,kill -9也不行,因为谁也不能杀死一个死去的进程
- 父进程给子进程的任务完成的如何,我们需要指定
- 父进程通过等待的方式,回收子进程资源,获取子进程信息
- 为什么要等待:一个是因为进程之间有竞争性!,另一个是避免产生僵尸进程
进程等待的方法
阻塞:为了完成一个功能发起函数调用,然后没有完成这个功能则一直挂起等待,直到完成才返回。
非阻塞:为了完成一个功能发起一个函数,如果现在不具备完成的条件,则立即返回不等待。
wait方法
#include<sys/types.h>
#include<sys/wait.h>
pid_t wait(int *status);
// 返回值:成功返回被等待进程pid,失败返回-1
//参数:输出型参数,获取子进程的退出状态,不关心则设置为NULL
功能:等待子进程退出(阻塞式调用:如果没有子进程退出,就一直等待不返回,直到子进程退出)
waitpid方法
pid_t waitpid(pit_t pid,int *status,int options);
//返回值:
正常时候waitpid返回子进程的进程id
如果设置了选择WNOHANG,而调用waitpid发现没有已退出的子进程可收集,则返回0
如果调用出错,则返回-1,这时候errno会被设置成相应的值以只是错误
//参数:
pid:
pid = -1,等待一个子进程,与wait等效
pid > 0, 等待进程id == pid 的子进程退出
status:
用于获取子进程退出状态码,不关心则设置为NULL
options:
选项参数(WNOHANG:如果没有子进程退出,则立即报错返回(非阻塞式调用),
如果有则回收资源)
功能:默认等待子进程退出
- 如果子进程已经退出,调用wait或waitpid时,wait或waitpid会立即返回,并且释放资源,获得子进程退出状态
- 如果任意时刻调用wait或waitpid,子进程存在其正常运行,则父进程可能阻塞
- 如果不存在该子进程,立即出错返回

总结
wait:等待任意一个进程,若没有子进程退出则一直等待(阻塞式,必须等到一个子进程退出后获取退出状态释放资源才返回)
waitpid:可以等待指定的子进程退出,也可以等待一个任意的子进程退出(可以设置为非阻塞WNOHNAG)
获取子进程status
- wait和waitpid,都有一个status参数,该参数是一个输出型参数,由系统填充
- 如果传递NULL,表示不关心子进程的退出状态信息
- 否则,操作系统会根据该参数,将子进程的退出信息反馈给父进程
- status不能当做整形来看待,可以当做位图来看待(只研究低16位)

测试代码:
1 #include<stdio.h>
2 #include<stdlib.h>
3 #include<errno.h>
4 #include<string.h>
5 #include<sys/wait.h>
6 int main()
7 {
8 pid_t pid;
9 pid = fork();
10 if(pid == -1)
11 {
12 perror("fork");
13 exit(1);
14 }
15 else if(pid = 0)
16 {
17 sleep(20);
18 exit(10);
19 }
20 else
21 {
22 sleep(20);
23 int st;
24 int ret = wait(&st);
25 if(ret > 0 && (st & 0x7F) == 0)//st&0x7F:与0x7F相当于取后7位,其余值0
26 {
27 //正常退出:高8位代表退出状态
28 printf("child exit code:%d\n",(st>>8)&0x7F);
29 }
30 else if(ret >0)
31 {
32 //异常退出:低8位代表异常退出信号
33 printf("sig code:%d\n",st&0x7F);
34 }
35 }
36 return 0;
37 }重开一个终端kill这个进程,就会产生假的异常退出。

kil -l 可以查看信号种类
总结:
- 虽然退出状态用了4个字节来获取,但是实际只用了低16位的2个字节储存有用的信息
- 在低16位中,高8位储存子进程的退出码,只有子进程运行完毕正常退出才有,低8位为0
- 低8位储存引起异常退出的信号值(第8位存储core dump标志),只有子进程异常退出是才有,这时高8位为0
- statu & 0x7 判断是否正常退出,并获取退出信号
- statu >> 8 获取退出码
- WIFEXIT(是否正常退出,如果是返回ture)
- WEXITSTATUS可以来获取WIFEXIT的退出码
进程程序替换
替换原理
替换的是代码段所指向的代码物理内存区域
创建一个子进程大多时候,并不希望子进程做跟父进程相同的事情,而是希望运行一些其他的代码程序,这时候就用到了进程替换,程序替换只是替换了代码段,初始化了数据区域,因此程序替换不会重新创建虚拟地址空间和页表,只是替换了其中的内容,并且替换后子进程这个进程将从入口函数开始运行。
因为代码段被替换,因此在替换之后的源代码不会再被执行,因为代码段中已经没有这些代码
用fork创建子进程后执行的是和父进程相同的程序(但有可能是不同的代码分支),子进程往往调用一种exec函数以执行另一个程序,
当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。调用exec不创建新的进程,
所以前后进程的id并未改变。
替换函数
- 有6种以exec开头的函数,统称为exec函数
- execl
- execlp
- execle
- execv
- execvp
- execve
函数解释与命名原理
- l(list):表示参数采用列表
- v(vector):参数用数组
- p(path):有p自动搜索环境变量PATH(不需要告诉路径,只需要告诉文件名)
- e(env):表示自己维护环境变量
- 这些函数如果调用成功则加载新的程序从启动代码开始执行,不在返回
- 如果调用出错则返回-1
- 所以exec函数只有出错的返回值而没有成功的返回值
- 头文件:<unistd.h>
总结
execl与execv区别:参数如何赋予(参数平铺,指针数组)
execl与execlp区别:
excl需要告诉操作系统这个程序的文件全路径
exclp不需要告诉路径,只需要告诉文件名,会自动到PATH寻找
execl与excle区别:
execl继承于父进程的环境变量
execle自己由我们用户来组织环境变量
1 #include<unistd.h>
2
3 int main()
4 {
5 char *const argv[] = {"ps","-ef",NULL};
6 char *const envp[] = {"PATH=/bin:/usr/bin","TERM=console",NULL};
7
8 execl("/bin/ps","ps","-ef",NULL);
9
10 execlp("ps","ps","-ef",NULL,envp);
11
12 execv("/bin/ps",argv);
13
14 execvp("ps",argv);
15
16 execve("/bin/ps",argv,envp);
17 return 0;
18 }

事实上,只有execve值真正的系统调用,其他五个函数最终都调用execve,所以execve在man手册第2节,其他函数在man第3节
关系如下图所示:

简单的shell
代码:
shell代码非常简单只能完成最基本的命令
优化代码:
实现一个简单的shell - W_J_F_的博客 - CSDN博客 https://blog.csdn.net/W_J_F_/article/details/83618383
实现了
1:解决的无法识别多空格的问题(ls -l)
2:解决的无任何输入时回车死循环的问题
shell代码非常简单只能完成最基本的命令
1 //自己实现一个简单的shell
2 #include<stdio.h>
3 #include<unistd.h>
4 #include<stdlib.h>
5 #include<errno.h>
6 #include<string.h>
7 //1:获取终端输入
8 //2:解析输入(按空格解析到一个一个的命令参数)
9 //3:创建一个子进程:在子进程中级进行程序替换,让子进程运行命令
10 //4:等待子进程运行完毕,收尸,获取退出状态码
11
12 int argc;
13 char *argv[32];
14 int param_parse(char *buff)
15 {
16 if(buff == NULL)
17 return -1;
18 char *ptr = buff;
19 char *tmp = ptr;
20
21 argc = 0;
22 while((*ptr) != '\0')
23 {
24 if((*ptr) == ' '&& *(ptr + 1) != ' ')
25 {
26 //当遇见空格且下一个位置不是空格
27 //将空格置为‘\0’
28 //但是我们使用argv[argc]来保存这个字符串位置
29 *ptr = '\0';
30 argv[argc] = tmp;
31 tmp = ptr + 1;
32 argc++;
33 }
34 ptr++;
35 }
36 argv[argc++] = tmp;
37 argv[argc] = NULL;
38 return 0;
39 }
40 int do_exec()
41 {
42 int pid = 0;
43 pid = fork();
44 if(pid < 0)
45 {
46 perror("fork");
47 return -1;
48 }
49 else if (pid == 0)
50 {
51 execvp(argv[0],argv);
52 exit(0);
53 }
54 //父进程在这里必须等待子进程退出,来观察子进程为什么会退出
55 //是否出现了什么错误,通过获取状态码,并且转换退出码所对应
56 //的错误信息进行打印
57 int statu;
58 wait(&statu);
59 //判断子进程是否代码运行完毕退出
60 if(WIFEXITED(statu))
61 {
62 //获取到子进程的退出码,转换为文本信息
63 printf("%s",strerror(WEXITSTATUS(statu)));
64 }
65 return 0;
66 }
67
68 int main()
69 {
70 while(1)
71 {
72 printf("shell> ");
73 char buff[1024] = {0};
74 scanf("%[^\n]%*c",buff);
75 //%[^\n] 获取数据直到遇见\n为止
76 //%*c 清空缓冲区,数据都不要(不然还存有是上一个\n)
77 printf("%s\n",buff);
78 param_parse(buff);
79 do_exec();
80 }
81 return 0;
82 }

图解

时间轴表示发生次序,shell从用户读入字符串‘ls’,shell建立一个新的进程,然后在那个进程中运行ls并等待那个进程结束
然后shell读取新的一行输入,建立一个新的进程,在这个进程中运行程序,并等待这个程序结束
所以写一个shell,需要循环一下过程
- 获取命令
- 解析命令
- 建立一个子进程fork,并进行进程替换execvp
- 父进程等待子进程的退出wait
总结
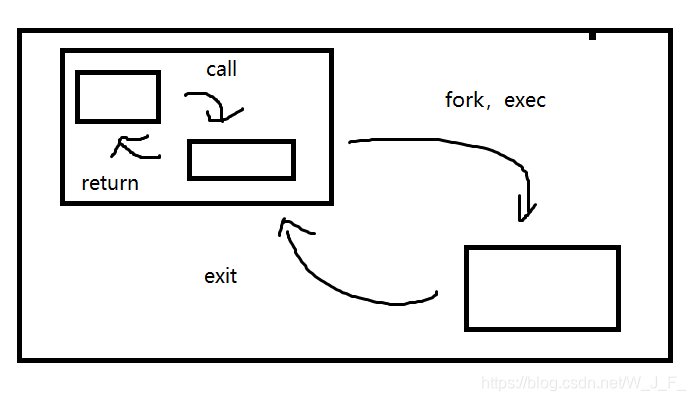
一个从程序有很多函数组成,一个函数具有调用另一个函数,同时传递给它一些参数。
被调用的函数执行一定的操作,然后返回一个值,每个函数都有他的局部变量,不同的是
函数通过call/return系统进行通信,这种通过参数和返回值在拥有私有数据的函数之间通信的模式
是结构化程序设计的基础。如下图:
一个c程序可以fork/exec另一个程序,并给它传一些参数,这个被调用的程序执行一定的操作
然后通过exit(n)产生返回值,调用它的进程可以通过wait(&ret)来获取exit的返回值