目录
一. 软件开发栈
Jetson的软件开发栈拥有对AI应用从底层到应用层的完整支持,包括模型的训练,转化,操作系统,音视频流等。
二. JetPack
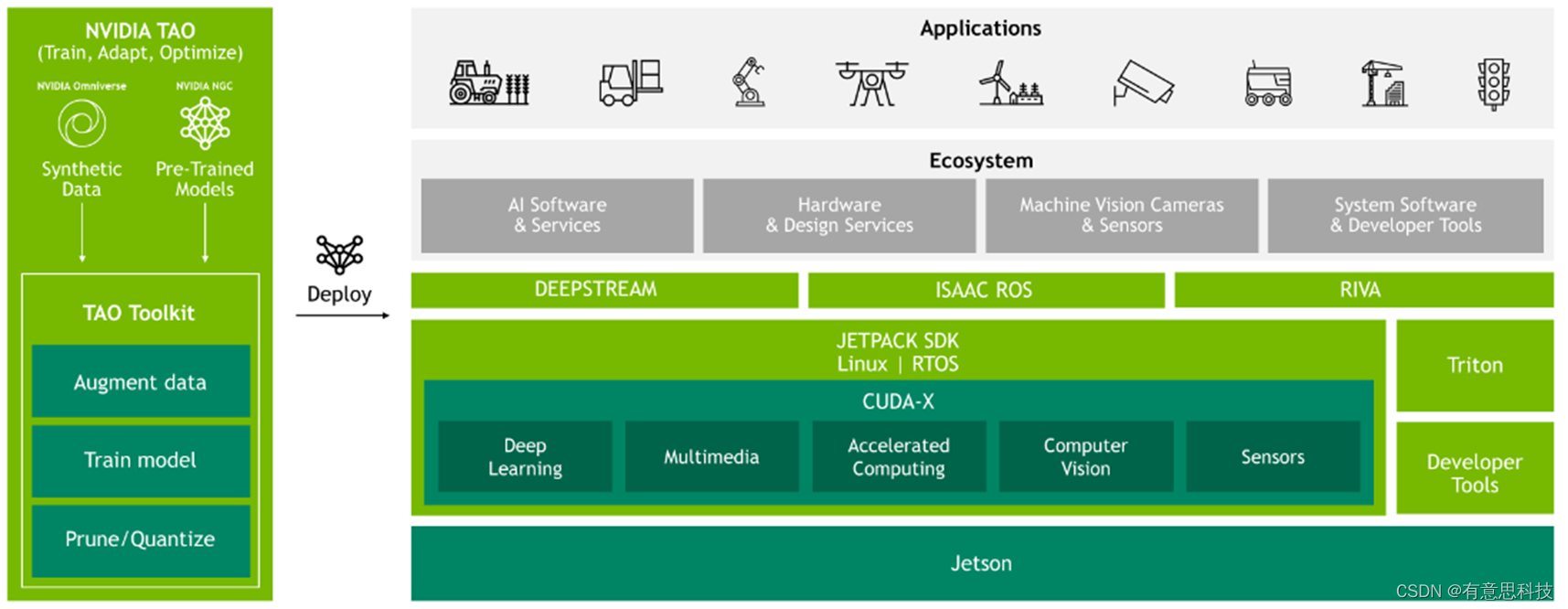
NVIDIA JetPack SDK 是构建端到端加速 AI 应用的全面解决方案。JetPack 为硬件加速的边缘 AI 开发提供了完整的开发环境。JetPack 支持所有 Jetson 模组和开发者套件。
JetPack 包括带有引导加载程序的 Jetson Linux、Linux 内核、Ubuntu 桌面环境,以及一整套用来为 GPU 计算、多媒体、图形和计算机视觉加速的库。它还包含用于主机和开发者套件的示例、文档和开发者工具,并支持更高级别的 SDK,例如用于流媒体视频分析的 DeepStream、用于机器人开发的 Isaac 以及用于对话式 AI 的 Riva。
三. Jetson Linux
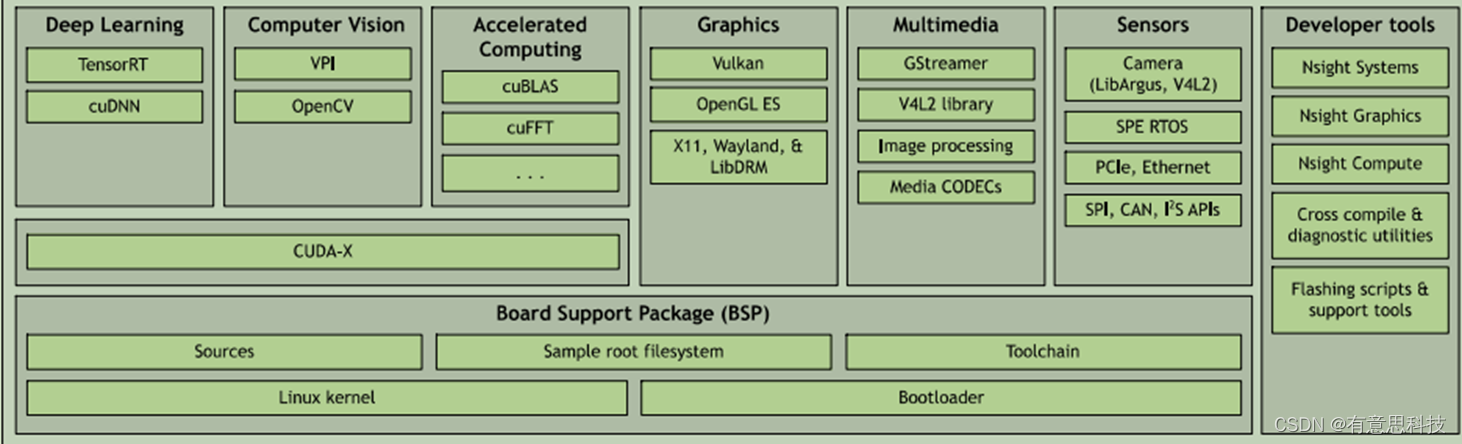
NVIDIA Jetson Linux 提供 Linux 内核、基于 UEFI 的引导加载程序、基于 Ubuntu 的根文件系统、NVIDIA 驱动、必要的固件、工具链等。
同时也提供Linux内核源码,可根据需要定制不同硬件的Linux系统。

四. CUDA
CUDA™是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。 CUDA 工具套件为 C 和 C++ 开发者构建 GPU 加速应用提供了全面的开发环境。该工具包中包括一个针对 NVIDIA GPU 的编译器、多个数学库,以及多款用于调试和优化应用性能的工具。
支持C/C++/Python开发,使用Python开发需要额外安装库(Pycuda)来支持。同时也提供了两个数学计算库,cuFFT(离散快速傅立叶变换)和cuBLAS(离散基本线性计算)。
4.1 CUDA工作流
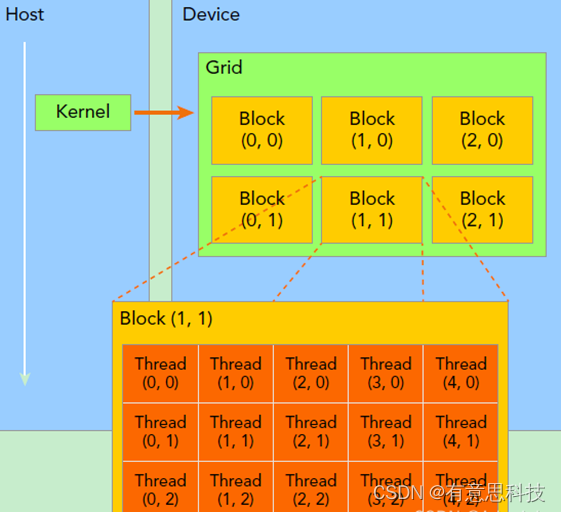
kernel:在device上线程中并行执行的函数,核函数用__global__符号声明。
kernel在device上执行时实际上是启动很多线程,一个kernel所启动的所有线程称为一个网格(grid),同一个网格上的线程共享相同的全局内存空间,grid是线程结构的第一层次,而网格又可以分为很多线程块(block),一个线程块里面包含很多线程,这是第二个层次。

五. cuDNN
NVIDIA CUDA® 深度神经网络库 (cuDNN) 是一个 GPU 加速的深度神经网络基元库,能够以高度优化的方式实现标准例程(如前向和反向卷积、池化层、归一化和激活层)。
cuDNN 可加速广泛应用的深度学习框架,包括 Caffe2、Chainer、Keras、MATLAB、MxNet、PaddlePaddle、PyTorch 和 TensorFlow。

六. TensorRT
TensorRT 是用于图像分类、分割和物体检测神经网络的高性能深度学习推理运行时。TensorRT 依托于 CUDA 而构建,是 NVIDIA 的并行编程模型,支持优化各种深度学习框架的推理过程。它包含深度学习推理优化器和运行环境,让深度学习推理应用实现低延迟和高吞吐量。

TensorRT 针对多种深度学习推理应用的生产部署提供 INT8 和 FP16 优化,例如视频流式传输、语音识别、推荐和自然语言处理。
通过TensorRT 能显著提高NVIDIA GPU 上的深度学习推理性能。

七. 主要框架集成
NVIDIA 与深度学习框架开发者紧密合作,使用 TensorRT 在 AI 平台上实现优化的推理性能。如果您的训练模型采用 ONNX 格式或其他热门框架(例如 TensorFlow 和 MATLAB),您可以通过一些简单的方法将模型导入到 TensorRT 以进行推理。
![]() TensorRT 和 TensorFlow 已紧密集成,因此您可以同时尽享 TensorFlow 的灵活性和 TensorRT 的超强优化性能。
TensorRT 和 TensorFlow 已紧密集成,因此您可以同时尽享 TensorFlow 的灵活性和 TensorRT 的超强优化性能。
![]() TensorRT 提供了一个 caffemodel解析器,因此您可以轻松地将Caffe模型导入到 TensorRT。
TensorRT 提供了一个 caffemodel解析器,因此您可以轻松地将Caffe模型导入到 TensorRT。
![]() TensorRT 提供了一个 ONNX 解析器,因此您可以轻松地从框架(例如 Caffe 2、Chainer、Microsoft Cognitive Toolkit、MxNet 和 PyTorch)中将 ONNX 模型导入到 TensorRT。
TensorRT 提供了一个 ONNX 解析器,因此您可以轻松地从框架(例如 Caffe 2、Chainer、Microsoft Cognitive Toolkit、MxNet 和 PyTorch)中将 ONNX 模型导入到 TensorRT。
![]() TensorRT 提供了一个 ONNX 解析器,因此您可以轻松地从框架(例如 Caffe 2、Chainer、Microsoft Cognitive Toolkit、MxNet 和 PyTorch)中将 ONNX 模型导入到 TensorRT。
TensorRT 提供了一个 ONNX 解析器,因此您可以轻松地从框架(例如 Caffe 2、Chainer、Microsoft Cognitive Toolkit、MxNet 和 PyTorch)中将 ONNX 模型导入到 TensorRT。
![]() Torch-TensorRT对PyTorch有很好的支持,但目前版本还不能支持jetson平台。
Torch-TensorRT对PyTorch有很好的支持,但目前版本还不能支持jetson平台。
八. 模型导入
不同的框架可采用不同的方式将对应的模型导入到TensorRT中进行解析,主要有TensorFlow的模型,Caffe模型,ONNX模型。
1.TensorFlow:
2.Caffe:
3.ONNX:
九. Multimedia
Nvidia Multimedia API是支持灵活的应用程序开发的底层API的集合。底层API通过提供对底层硬件模块的更好控制来实现灵活性。
Multimedia API接口与GStreamer框架分开,后者提供了高级API。Multimedia API提供了用于开发Jetson平台嵌入式应用程序的库,头文件,API文档和示例源代码。
主要提供的API有:1. Libargus API:提供摄像头帧处理,多摄像头支持等API
2. V4L2 API:提供视频加解码,格式转换,缩放等API。


十. VPI
VPI 是一个软件库,提供了一系列计算机视觉和图像处理算法,可以在各种硬件加速器中无缝执行。VPI 的目标是为计算后端提供统一的接口,同时保持高性能。
VPI也提供接口能够与OpenCV对接,可以轻松地将 VPI 与OpenCV捕获的工作流集成,或者扩展现有的数据管道,以便更好地使用 VPI 提供的硬件加速。
VPI的核心组件包括:
1.CV算法:表示不可分割的计算操作。
2.后端:代表负责实际计算的硬件引擎。
3.流:充当向其提交算法的异步队列,最终在给定的后端按顺序执行,流和事件是计算流程的构建块。
4.缓冲区:存储输入和输出数据。
5.事件:提供对流和/或应用程序线程进行操作的同步原语。
6.上下文:保存 VPI 和已创建对象的状态。

10.1 VPI工作流
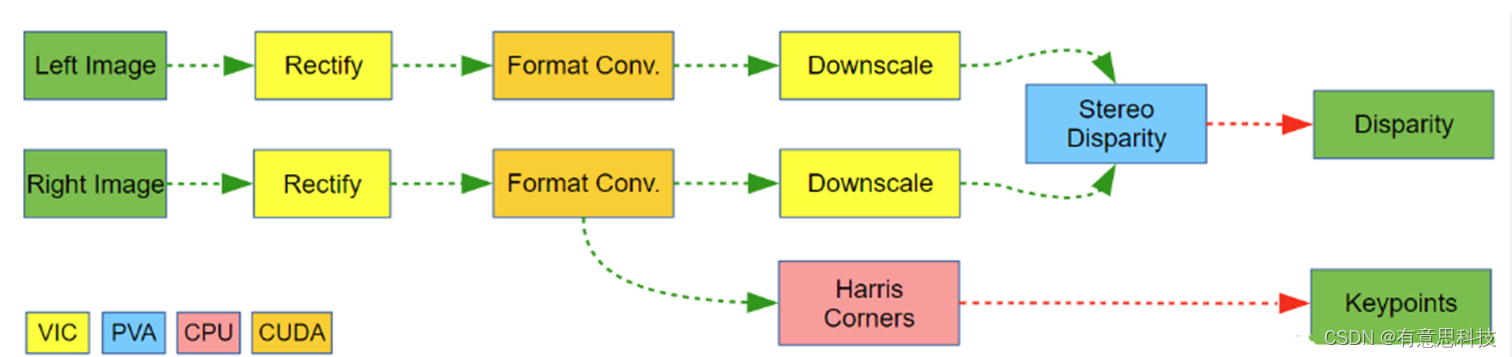
复杂的场景可能会利用设备上的不同加速处理器,并创建一个最能利用其全部计算能力的流程。独立的左右图像预处理和Harris 角点提取。 流程对每个处理阶段使用不同的后端,具体取决于每个后端的处理速度、功率要求、输入和输出限制以及可用性。
在此示例中,处理在以下后端之间进行拆分:
VIC:进行图像校正和缩小。
CUDA:进行图像格式转换。
PVA:进行立体视差计算。
CPU:处理哈里斯角的一些预处理和提取
10.2 VPI VS OpenCV
VPI对比OpenCV而言,分别在基于CPU和GPU进行对比测试,基于CPU,VPI的处理速度是OpenCV的7倍,基于GPU,VPI的处理速度是OpenCV的11倍。

十一. DeepStream
DeepStream 是使用开源 GStreamer 框架构建的优化图形架构,用于构建具有AI能力的应用程序的流分析工具包。它以流作为输入,即从USB/CSI/RTSP相机中获取流数据,DeepStream SDK 可以作为许多视频分析解决方案的基础层。
DeepStream 建立在 CUDA-X 堆栈的多个 NVIDIA 库的基础上,例如:CUDA,tensorRT,Triton Inference服务器,多媒体库。

11.1 GStreamer
Gstreamer是一个支持Windows,Linux,Android, iOS的跨平台的多媒体框架,应用程序可以通过管道(Pipeline)的方式,将多媒体处理的各个步骤串联起来,达到预期的效果。每个步骤通过元素(Element)基于GObject对象系统通过插件(plugins)的方式实现,方便了各项功能的扩展。


11.2 应用架构
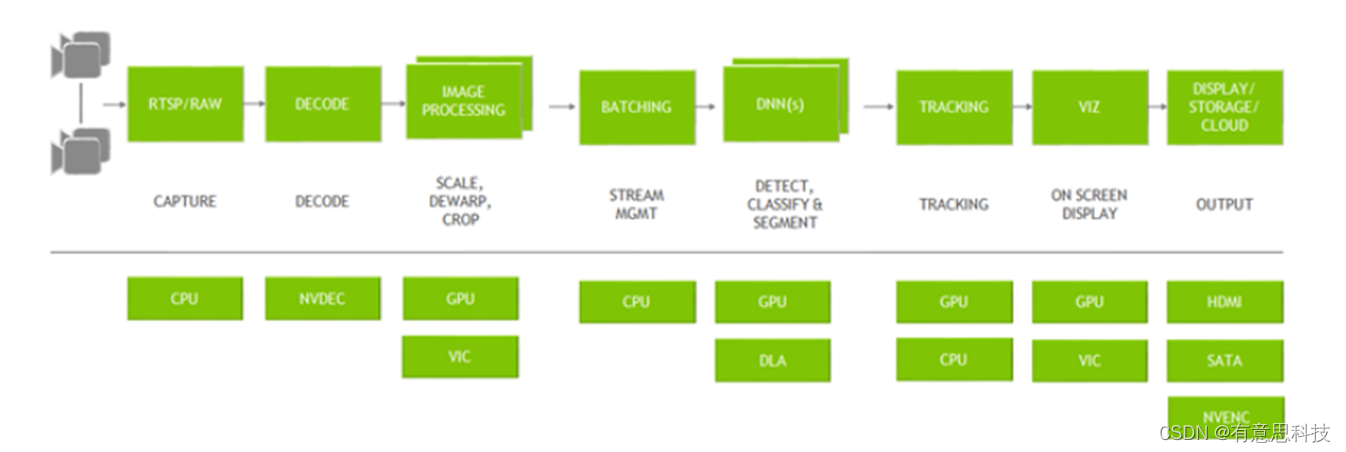
DeepStream提供丰富的插件供开发者使用,从输入都最终输出的一整套流程中,都有相应的插件使用。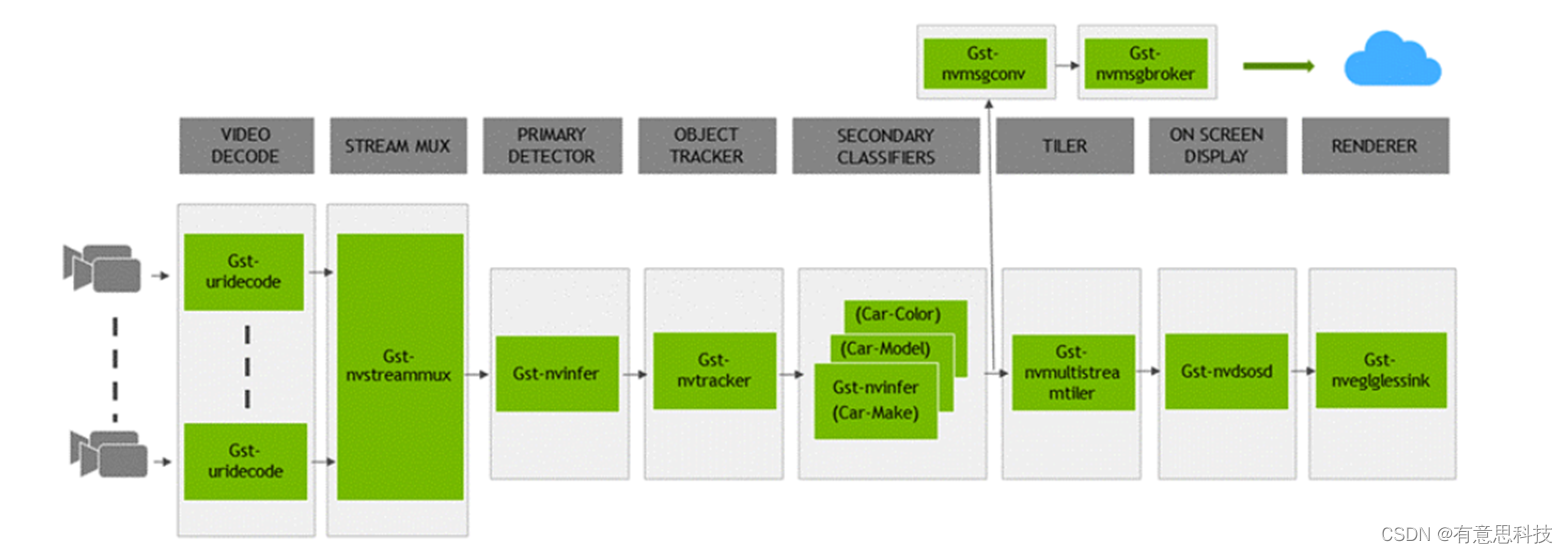
一个典型的视频分析应用程序,从输入视频到输出见解。所有单独的块都是使用的各种插件。底部是在整个应用程序中使用的不同硬件引擎。最佳的内存管理以及插件之间的零内存复制以及各种加速器的使用确保了最高的性能。