前面几期,为大家介绍了多目标跟踪任务及数据集资源,也梳理了无人机与AI 结合的相关应用。
其中,采用灵活轻便、视角开阔的无人机进行多目标跟踪任务已经成为一大研究热点,其可以广泛应用于智能交通、智能安防等场景。
在做无人机多目标跟踪相关模型训练时,我们经常会用到 Stanford Drone 数据集,这一期,就给大家详细解读一下。
目录

一、数据集简介
发布方:Stanford University Computational Vision and Geometry Lab (CVGL)
发布时间:2016
发布版本:08/01/2016
背景:
作者发现以往的数据集存在以下的问题:
- 只收集某个目标类别的移动轨迹;
- 只收集某些交互方式下的数据;
- 在人为的场景下收集。
因此作者收集这批数据用于研究多真实场景多目标类别下人们的轨迹模式。
简介:
Stanford Drone 数据集使用无人机在校园拥挤的时间段以俯视的方式收集了8个不同的场景下20k个物体的轨迹交互信息,每个物体的轨迹都标注唯一的 ID ,使得该数据集十分适合用于:
- 目标轨迹预测;
- 多目标跟踪。
(网站和文章在这个部分的描述会有所不同,文章里说收集了6个场景,后面应该扩展成8个,所以网站描述为8个场景,现在能下载到的数据集也是包含8个场景的数据)
二、数据集详细信息
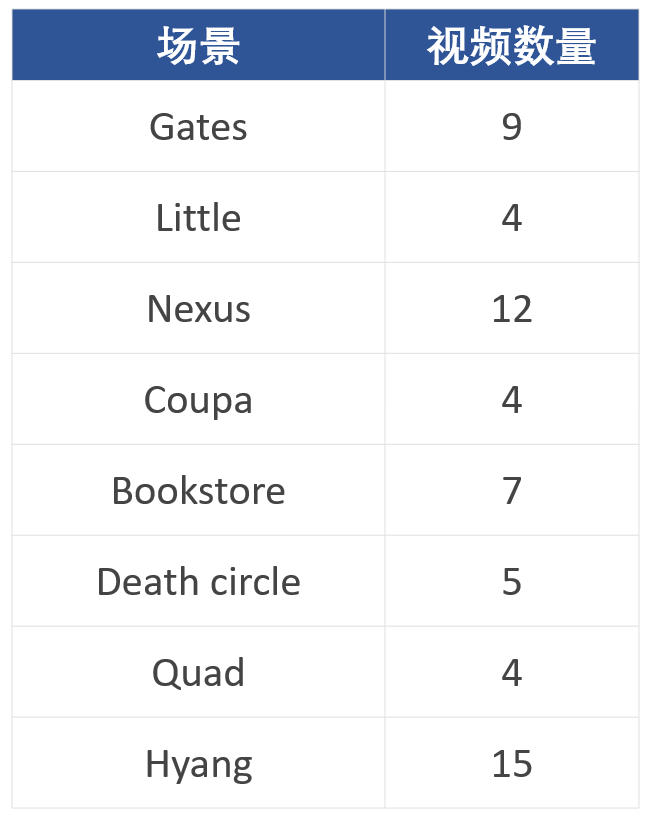
1. 数据量及标注情况
数据集的所有数据都是有标注的。
2. 标注类别
数据集的标注包含6个类别:
- Biker: 骑单车的人
- Pedestrian: 行人
- Skater: 用滑板的人
- Cart: 拉手推车的人
- Car: 汽车
- Bus: 巴士
3. 可视化
每个目标都会有一个 2D 框标注,并且带有该目标的类别和唯一 ID。在图中不同的类别用不同的颜色标识。
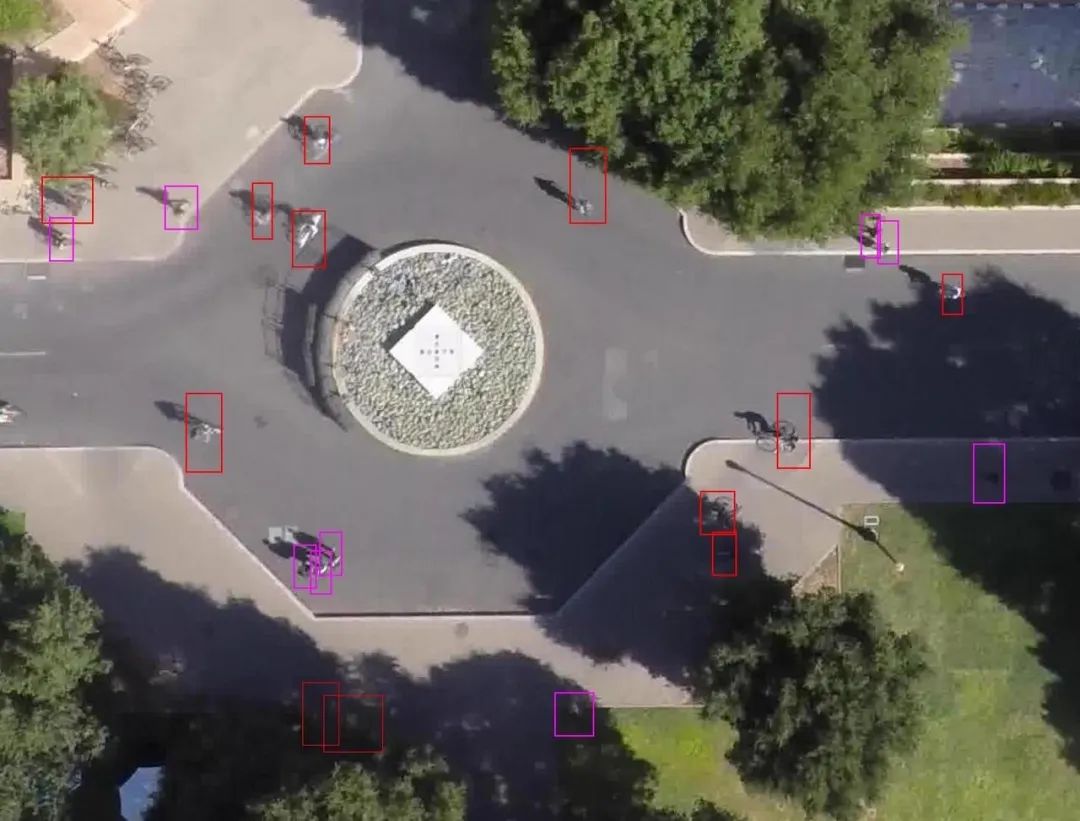
图1:场景为 Gates 下的样例图
三、数据集任务定义及介绍
1. 轨迹预测
● 轨迹预测定义
给定一段时间内目标已知的移动轨迹,预测未来一段时间内目标的位置。
● 轨迹预测评价指标,由以下三个指标构成
a. 整个预测轨迹的误差
b. 最后预测点的误差
c. 由于躲避碰撞而产生轨迹偏移的误差
2. 多目标跟踪
● 多目标跟踪定义
给定需要检测的目标一段时间内的视频数据,需要先逐帧检测出目标,然后将各个帧的目标检测结果连接形成轨迹。(具体介绍可见:多目标跟踪任务科普)
● 多目标跟踪评价指标构成
a. 多目标跟踪准确率(MOTA):
主要考量假阳性(False positives),目标丢失(Missed targets)和标识改变(Identity switches)的情况。
b. 多目标跟踪精确度(MOTP):
主要考量真实目标与预测目标的平均距离。
c. 主要跟踪和主要丢失(MT & ML):
计算主要(多于80%的帧里)跟踪的轨迹数量和主要(少于20%的帧里)已丢失的轨迹数量。
四、数据集文件结构解读
1. 目录结构
Stanford Drone dataset
├── README
├── annotations # annotations: 标注,标注文件与数据集的目录结构一一对应
│ ├── bookstore # bookstore: 以不同场景区分视频
│ │ ├── video0
│ │ │ ├── annotations.txt
│ │ │ └── reference.jpg # reference.jpg: 视频样例图片
│ │ ├── video1
│ │ │ ├── annotations.txt
│ │ │ └── reference.jpg
│ │ └── ...
│ ├── coupa
│ │ ├── video0
│ │ │ ├── annotations.txt
│ │ │ └── reference.jpg
│ │ ├── video1
│ │ │ ├── annotations.txt
│ │ │ └── reference.jpg
│ │ └── ...
│ └── ...
└── videos # videos: 数据集
├── bookstore
│ ├── video0
│ │ └── video.mov
│ ├── video1
│ │ └── video.mov
│ └── ...
├── coupa
│ ├── video0
│ │ └── video.mov
│ ├── video1
│ │ └── video.mov
│ └── ...
└── ...2. 标注文件内容样例及内容解析
0 211 1038 239 1072 10005 1 0 1 "Biker"
0 211 1038 239 1072 10006 1 0 1 "Biker"
0 211 1038 239 1072 10007 1 0 1 "Biker"
11 314 566 356 621 10336 1 0 1 "Pedestrian"
11 314 566 356 621 10337 1 0 1 "Pedestrian"
11 314 566 356 621 10338 1 0 1 "Pedestrian"
72 530 510 581 568 10000 0 0 0 "Cart"
72 528 510 579 568 10001 0 0 1 "Cart"
72 528 510 579 568 10002 0 0 1 "Cart"
72 528 510 579 568 10003 0 0 1 "Cart"标注文件内容从左到右的字段对应以下由上到下的字段:
Track ID: 目标 ID ,同一跟踪目标有唯一的目标 ID
xmin: 标注框左上的 x 坐标
ymin: 标注框左上的 y 坐标
xmax: 标注框右下的 x 坐标
ymax: 标注框右下的 y 坐标
frame: 该标注对应的帧号
lost: 是否丢失,如果为1则目标在视野范围外
occluded: 是否有遮挡,如果为1则目标有遮挡
generated: 是否生成的标注,如果为1则该标注是通过自动插值生成的
label: 该目标对应的类别五、数据集下载链接
1. 原数据集格式问题
数据为CSV格式,对于每个字段信息需要通过阅读README做对应的映射,不够直观。
在实际开发中与其他数据集之间缺乏统一组织结构标准和标注格式标准,会导致:
- 预处理脚本花样百出;
- 共享效率低,需要同时共享处理脚本;
- 难以跨数据集检索;
- 数据集合并成本较高;
- 难以开发统一的可视化工具。
2. 数据集下载
OpenDataHub平台为大家提供了完整的数据集信息、直观的数据分布统计、流畅的下载速度、便捷的可视化脚本,欢迎体验。
参考资料
[1]官网:https://cvgl.stanford.edu/projects/uav_data/
[2]论文:A Robicquet, A Sadeghian, A Alahi, et al. Learning social etiquette: Human trajectory understanding in crowded scenes. In ECCV, 2016
(PDF获取链接:https://link.springer.com/chapter/10.1007/978-3-319-46484-8_33)
更多数据集上架动态、更全面的数据集内容解读、最牛大佬在线答疑、最活跃的同行圈子……欢迎添加微信opendatalab_yunying 加入OpenDataLab官方交流群。