除了多目标跟踪任务外,研究经典的、通用的单目标跟踪任务对于整个跟踪领域的发展有重要意义。
本期给大家介绍一个包含包含超过3万个视频,共有27个目标类别,视频数量和标注数量比以往的跟踪数据集更大的数据集——TrackingNet。该数据集进行了训练集和测试集的划分,提供的大规模训练视频能够有效地缓解当前跟踪领域的训练数据不足的问题。
一、数据集简介
发布方:King Abdullah University of Science and Technology
发布时间:2018
背景:
作者发现当前的目标跟踪社区缺少一个大规模的自然场景下专门用于训练目标跟踪模型的数据集;现有的数据集很多没有明确的训练集/测试集的划分。
简介:
TrackingNet是一个大规模的目标跟踪数据集,包含了30643个视频片段,平均每个视频片段时长16.6s。从140个小时提取的14431266帧图像都使用了bounding box进行标注。
TrackingNet比之前的最大的同类型数据集大两个数量级以上。该数据集囊括了自然场景下的各种情形,包含了各种帧率,分辨率,上下文场景以及目标类别。与之前的目标跟踪数据集不同,TrackingNet分为训练集和测试集两部分,作者仔细地从Youtube-BoundingBoxes中选择了30132个训练视频,并且自己构建了511个与训练集分布相似的视频构成测试集。
二、数据集详细信息
1. 标注数据量
与其他数据集的对比情况如下图,图中横坐标为数据集中视频数量,纵坐标为视频的平均帧数,圆形的尺寸与数据集中标注的bounding box数量成正比:

2. 标注类别
尽管数据集中被标注的目标包含了多个类别,但是在TrackingNet的标注文件中只提供了矩形框标注,并没有提供每个目标的类别。
3. 数据集的构建方式
● 从YT-BB中构建训练集
Youtube-BoundingBoxes(YT-BB)是一个用于目标检测的大规模数据集,其中包含了大约380000个视频片段,每一帧都标注了bounding box,这些视频直接从YouTube上采集,涵盖了各种分辨率,帧率和时长。
YT-BB中包含了23个目标类别,为了构建目标跟踪数据集,作者将其中不会运动类别(盆栽、厕所)排除。由于person类别占了所有标注数量的25%,作者根据其上下文场景,将person类别细分为了7个不同的类别,最终,TrackingNet的目标类别统计情况如下图所示:

为了保证数据集中视频的质量,作者按照下述步骤过滤掉了90%的视频,具体步骤为:
1. 过滤掉时长小于15秒的视频;
2. 只保留覆盖图像范围不超过50%的bounding box;
3. 只保留包含的的bounding box有合理移动量的视频片段。
经过上述过滤后,最终训练集中共有320132个视频片段,这些片段被分到了12个训练子集当中,每个子集包含了2511个视频,每个子集都保留了原始的YT-BB的类别分布。
原始的YT-BB的标注是粗粒度的,只有1fps,为了提高标注密度,作者使用DCF tracker将视频每秒间的前向跟踪结果和后向跟踪结果进行加权平均得到最终的细粒度标注结果。
● 从YT-CC中构建测试集
出来训练集,作者还构建了一个全新的数据集用来测试,其中包含了511个视频,这些视频是从YouTube上采集的,能够反映出训练集目标类别的分布情况,每个视频都遵循了Creative Commons licence,所以作者将该数据集简写为 YT-CC。
然后作者使用了 Amazon Mechanical Turk workers 和 VATIC 工具,将 YT-CC 进行细粒度的标注,最终构建出了 TrackingNet 测试集。
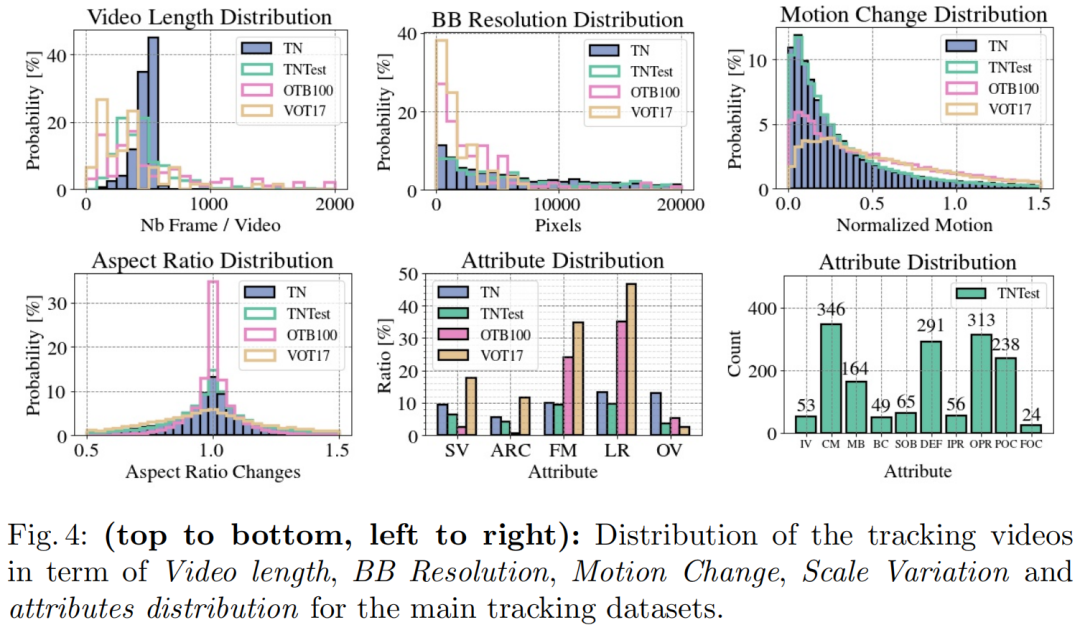
TrackingNet 测试集中,每个视频都被标注了一些属性,属性列表如下:

其中前5个属性是通过分析视频中的bounding box的变化自动标注的,后10个属性则是通过人工标注的。测试集的属性标注方便研究者更好地分析模型在不同场景下的效果。数据集中这15个属性的分布情况如下图所示:
4. 可视化
每段视频都在每一帧用矩形框标注一个单目标:

三、数据集任务定义及介绍
1. 单目标跟踪
● 任务定义
在单目标跟踪(Single Object Tracking, SOT)任务中,在视频的第一帧中会给出目标的bounding box,模型的目标则是在视频的后续所有帧中定位该指定目标,因此单目标跟踪任务属于detection-free 跟踪任务。
● 评价指标
success(S),该分数通过计算ground truth和prediction bounding box的IoU得到,计算公式如下:
其中 为模型预测的bounding box,
为ground truth bounding box。在验证模型时,会根据不同的IoU阈值(在文中称为Overlap threshold),计算出对应阈值的success rate,并画出横坐标为阈值,纵坐标为success rate的曲线,最终通过该曲线的AUC来对模型的性能进行排序。
precision(P),该分数通过计算ground truth和prediction bounding box中心点之间的距离得到,计算公式如下:
其中 为模型预测的bounding box的中心坐标,
为ground truth bounding box的中心坐标。在验证模型时,会根据不同的距离阈值(在文中称为Location error threshold),计算出对应阈值的precision,并画出横坐标为阈值,纵坐标为precision的曲线,最终通过阈值为20的precision来对模型的性能进行排序。
normalized precision( ),该分数使用ground truth bounding box的尺寸对precision
进行标准化,计算公式如下:
其中 表示构建对角矩阵,
,
分别是ground truth bounding box的横坐标和纵坐标。在验证模型时,会根据不同的normalized precision阈值(在文中称为Normalized distance error threshold,范围限制在0到0.5之间),计算出对应阈值的precision,并画出横坐标为阈值,纵坐标为precision的曲线,最终通过该曲线的AUC来对模型的性能进行排序。
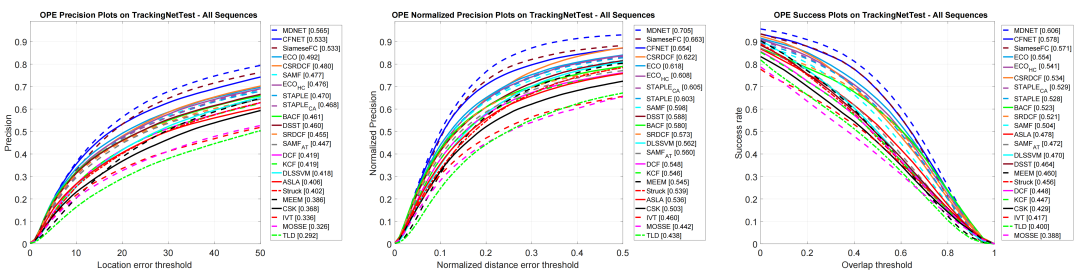
各模型在TrackingNet上的表现:
四、数据集文件结构解读
1. 数据集存在的问题
● 只提供了目标的矩形框,未提供目标的类别,视频的属性等信息;
● 测试集未提供全部帧的标注,只提供了每个测试视频的第一帧的矩形框标注信息,如果要在测试集上测试,需要将模型在测试集上的推理结果上传到http://eval.tracking-net.org/featured-challenges/39/participate才能查看验证结果。
2. 数据集目录结构
首先需要对初始的数据集压缩文件进行解压,解压脚本如下:
#!/bin/bash
data_dir=$1
for chunk in $(ls "${data_dir}"); do
# unzip chunk zip
if [ ${chunk##*.} == "zip" ]; then
chunk_name=${chunk%.zip}
unzip_dir=$data_dir/$chunk_name
if [ ! -d $unzip_dir ]; then
mkdir $unzip_dir
fi
unzip -n $data_dir/$chunk -d $unzip_dir
# unzip zips in every chunk
for zips in $(ls "${unzip_dir}/zips"); do
if [ ${zips##*.} == "zip" ]; then
vid_name=${zips%.zip}
if [ ! -d $unzip_dir/frames/$vid_name ]; then
mkdir -p $unzip_dir/frames/$vid_name
fi
unzip -n $unzip_dir/zips/$zips -d $unzip_dir/frames/$vid_name
fi
done
fi
done(左右滑动查看)
解压后的数据集目录结构如下:
dataset_root/ # 数据集中包含了TEST,TRAIN_0,TRAIN_1,...,TRAIN_11,一共13个目录,代表了一个测试集和12个训练子集
├── TEST/ # 每个目录中都包含了 anno 和 frames两个子目录
│ ├── anno/ # anno中放了若干个 .txt 文件,
│ │ ├── 0-6LB4FqxoE_0.txt # 每个 .txt 文件都标注了一段视频,被标注的视频与该 .txt 文件名称相同,存储在frames目录当中
│ │ ├── 07Ysk1C0ZX0_0.txt
│ │ └── ...
│ └── frames/ # frames中放了若干个 子目录,每个子目录代表一段视频,存储了该视频的每一帧图像
│ ├── 0-6LB4FqxoE_0/
│ │ ├── 0.jpg # 每帧图像的命名形如:0.jpg,1.jpg
│ │ ├── 1.jpg
│ │ └── ...
│ ├── 07Ysk1C0ZX0_0/
│ │ └── ...
│ └── ...
├── TRAIN_0/
│ ├── anno/
│ │ └── ...
│ └── frames/
│ └── ...
├── TRAIN_1/
│ └── ...
└── ...(左右滑动查看)
3. 标注文件格式
● 训练集标注文件格式
在 TRAIN_0 到 TRAIN_11 的12个训练集目录中,每个标注 .txt 文件都提供了其对应视频的每一帧的矩形框标注,具体格式如下:
308.00, 1.00,173.00,275.00
307.97, 1.10,172.60,274.92
307.94, 1.20,172.20,274.84
307.91, 1.30,171.80,274.76
309.12, 1.00,171.88,275.48
309.40, 1.00,171.60,275.60
309.68, 1.00,171.32,275.72
306.27,-1.16,173.20,280.16
309.22,-1.04,172.80,280.04
315.11,-2.00,173.48,282.08
313.81,-3.50,175.60,285.20
314.45,-2.08,173.84,282.48
314.49,-1.86,173.28,282.16
314.53,-1.64,172.72,281.84
...
...每一行为视频的对应帧中目标的矩形框的 [x,y,w,h],即矩形框左上角的横坐标,纵坐标与矩形框的宽和高。
● 测试集标注文件格式
在测试集TEST目录中,每个标注 .txt 文件只提供了对应视频的第一帧的矩形框的标注,具体格式如下:
1,79,307,186表示视频第一帧中的目标的矩形框的 [x,y,w,h] ,即矩形框左上角的横坐标,纵坐标与矩形框的宽和高。
五、数据集下载链接
OpenDataLab平台为大家提供了TrackingNet数据集完整的数据集信息、直观的数据分布统计、流畅的下载速度、便捷的可视化脚本,欢迎体验。点击链接查看:
https://opendatalab.com/TrackingNet/download
参考资料
[1]官网:https://tracking-net.org/
[2]论文:M Muller, A Bibi, S Giancola, et al. Trackingnet: A large-scale dataset and benchmark for object tracking in the wild, in ECCV, 2018: 300-317.
(PDF下载链接:https://arxiv.org/abs/1803.10794)
[3]下载:https://drive.google.com/drive/folders/1gJOR-r-jPFFFCzKKlMOW80WFtuaMiaf6
更多数据集上架动态、更全面的数据集内容解读、最牛大佬在线答疑、最活跃的同行圈子……欢迎添加微信opendatalab_yunying 加入OpenDataLab官方交流群。