导出onnx,int8量化,评估,推理
pt转onnx
from ultralytics import YOLO
model = YOLO("./runs/segment/train6/weights/best.pt") # load a pretrained YOLOv8n model
model.export(format="onnx",opset=12) # export the model to ONNX forma
这里我们直接导出的话,默认的batch数量是1,也就是13640*640的输入。如果需要进行多batch的onnx导出,需要去ultralytics/yolo/engine/model.py里进行修改,第269行,将1改为你想要的batch数量:
self._check_is_pytorch_model()
overrides = self.overrides.copy()
overrides.update(kwargs)
args = get_cfg(cfg=DEFAULT_CFG, overrides=overrides)
args.task = self.task
if args.imgsz == DEFAULT_CFG.imgsz:
args.imgsz = self.model.args['imgsz'] # use trained imgsz unless custom value is passed
if args.batch == DEFAULT_CFG.batch:
args.batch = 10 # default to 1 if not modified
exporter = Exporter(overrides=args)
return exporter(model=self.model)
这样再导出的话,我们可以通过netron来查看:
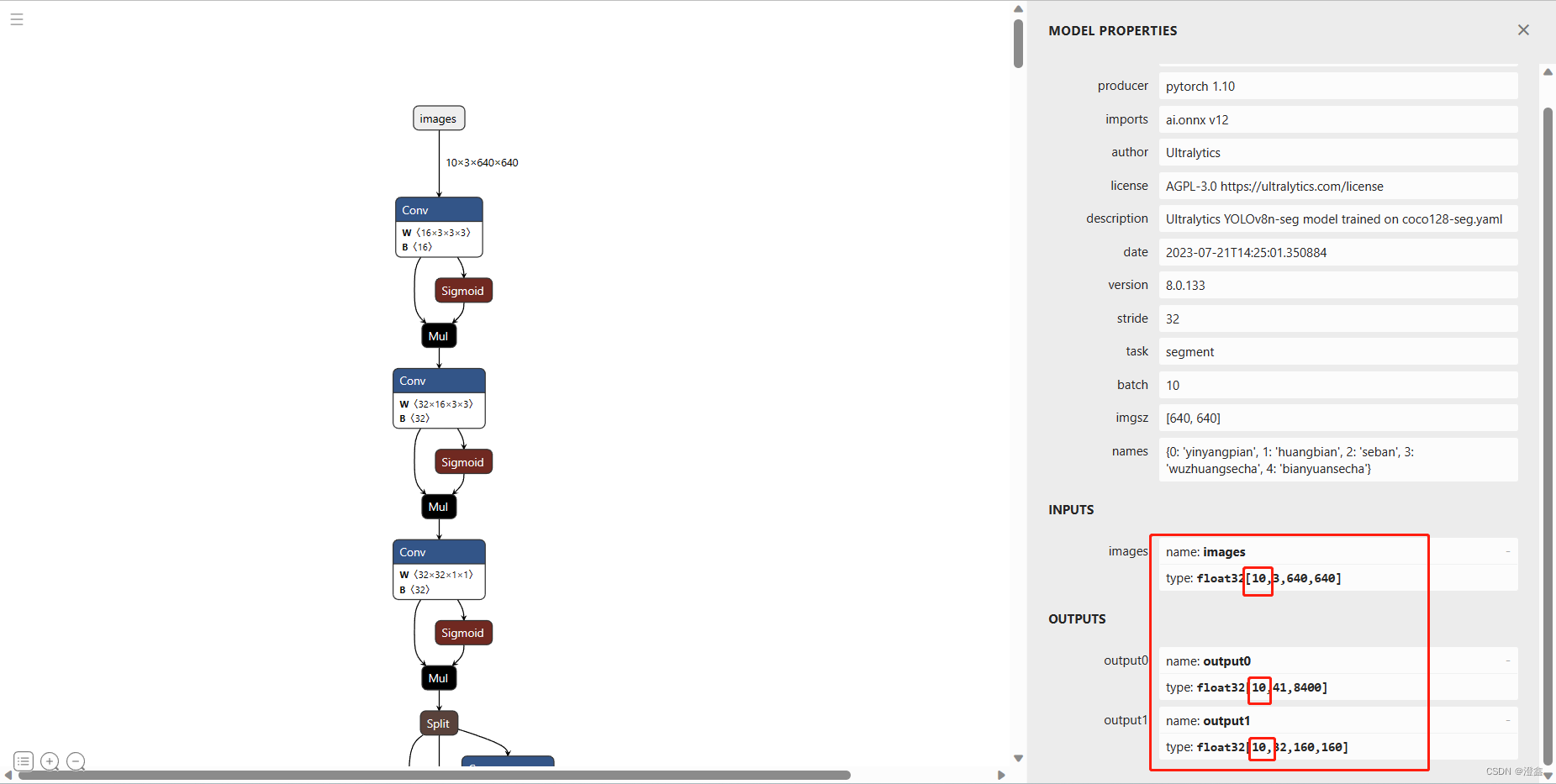
此时可以发现,我们的batch已经从1变成了10了。目前我在我的openvino专栏中已经发布了基于batch=1时的推理,后续会跟进在c++中的openvino的batch推理。
1. 量化
import nncf
from openvino.tools import mo
from openvino.runtime import serialize
import torch
from pathlib import Path
import logging
import os
from zipfile import ZipFile
from multiprocessing.pool import ThreadPool
import yaml
from itertools import repeat
import time
import platform
from tqdm.notebook import tqdm
from ultralytics.yolo.utils.metrics import ConfusionMatrix
import torch
import numpy as np
def my_test(model, core, data_loader:torch.utils.data.DataLoader, validator, num_samples:int = None):
"""
OpenVINO YOLOv8 model accuracy validation function. Runs model validation on dataset and returns metrics
Parameters:
model (Model): OpenVINO model
data_loader (torch.utils.data.DataLoader): dataset loader
validato: instalce of validator class
num_samples (int, *optional*, None): validate model only on specified number samples, if provided
Returns:
stats: (Dict[str, float]) - dictionary with aggregated accuracy metrics statistics, key is metric name, value is metric value
"""
validator.seen = 0
validator.jdict = []
validator.stats = []
validator.batch_i = 1
validator.confusion_matrix = ConfusionMatrix(nc=validator.nc)
model.reshape({
0: [1, 3, -1, -1]})
num_outputs = len(model.outputs)
compiled_model = core.compile_model(model)
for batch_i, batch in enumerate(tqdm(data_loader, total=num_samples)):
if num_samples is not None and batch_i == num_samples:
break
batch = validator.preprocess(batch)
results = compiled_model(batch["img"])
if num_outputs == 1:
preds = torch.from_numpy(results[compiled_model.output(0)])
else:
preds = [torch.from_numpy(results[compiled_model.output(0)]), torch.from_numpy(results[compiled_model.output(1)])]
preds = validator.postprocess(preds)
validator.update_metrics(preds, batch)
stats = validator.get_stats()
return stats
def print_stats(stats:np.ndarray, total_images:int, total_objects:int):
"""
Helper function for printing accuracy statistic
Parameters:
stats: (Dict[str, float]) - dictionary with aggregated accuracy metrics statistics, key is metric name, value is metric value
total_images (int) - number of evaluated images
total objects (int)
Returns:
None
"""
# print("Boxes:")
mp, mr, map50, mean_ap = stats['metrics/precision(B)'], stats['metrics/recall(B)'], stats['metrics/mAP50(B)'], stats['metrics/mAP50-95(B)']
# Print results
s = ('%20s' + '%12s' * 6) % ('Class', 'Images', 'Labels', 'Precision', 'Recall', '[email protected]', '[email protected]:.95')
print('Boxes:',s)
pf = '%20s' + '%12i' * 2 + '%12.3g' * 4 # print format
print(pf % ('\t\t\tall', total_images, total_objects, mp, mr, map50, mean_ap))
if 'metrics/precision(M)' in stats:
# print("Masks:")
s_mp, s_mr, s_map50, s_mean_ap = stats['metrics/precision(M)'], stats['metrics/recall(M)'], stats['metrics/mAP50(M)'], stats['metrics/mAP50-95(M)']
# Print results
s = ('%20s' + '%12s' * 6) % ('Class', 'Images', 'Labels', 'Precision', 'Recall', '[email protected]', '[email protected]:.95')
print("Masks:",s)
pf = '%20s' + '%12i' * 2 + '%12.3g' * 4 # print format
print(pf % ('\t\t\tall', total_images, total_objects, s_mp, s_mr, s_map50, s_mean_ap))
if __name__ == "__main__":
#定义需要量化的onnx模型的路径以及量化后保存的名称
MODEL_NAME = "best.onnx"
MODEL_PATH = f"runs/segment/train6/weights"
IR_MODEL_NAME = "v8_seg"
#将需要量化的onnx模型路径串起来
onnx_path = f"{
MODEL_PATH}/{
MODEL_NAME}"
#定义量化后的模型的路径名称
FP32_path = f"{
MODEL_PATH}/FP32_openvino_model/{
IR_MODEL_NAME}_FP32.xml"
FP16_path = f"{
MODEL_PATH}/FP16_openvino_model/{
IR_MODEL_NAME}_FP16.xml"
Int8_path = f"{
MODEL_PATH}/Int8_openvino_model/{
IR_MODEL_NAME}_Int8.xml"
#FP32 model
model = mo.convert_model(onnx_path)
serialize(model, FP32_path)
print(f"export ONNX to Openvino FP32 IR to:{
FP32_path}")
#FP16 model
model = mo.convert_model(onnx_path, compress_to_fp16=True)
serialize(model, FP16_path)
print(f"export ONNX to Openvino FP16 IR to:{
FP16_path}")
#Int8 model
from ultralytics.yolo.data.utils import check_det_dataset
from ultralytics.yolo.data.dataloaders.v5loader import create_dataloader
#
def create_data_source():
data = check_det_dataset('ultralytics/datasets/coco128-seg.yaml')
val_dataloader = create_dataloader(data['val'], imgsz=640, batch_size=1, stride=32, pad=0.5, workers=1)[0]
return val_dataloader
def transform_fn(data_item):
images = data_item['img']
images = images.float()
images = images / 255.0
images = images.cpu().detach().numpy()
return images
#加载数据
data_source = create_data_source()
#实例化校准数据集
nncf_calibration_dataset = nncf.Dataset(data_source, transform_fn)
#配置量化管道
subset_size = 40
preset = nncf.QuantizationPreset.MIXED
#执行模型量化
from openvino.runtime import Core
from openvino.runtime import serialize
core = Core()
ov_model = core.read_model(FP16_path)
quantized_model = nncf.quantize(
ov_model, nncf_calibration_dataset, preset=preset, subset_size=subset_size
)
serialize(quantized_model, Int8_path)
print(f"export ONNX to Openvino Int8 IR to:{
Int8_path}")
2. 评估
import nncf
from openvino.tools import mo
from openvino.runtime import serialize
import torch
from pathlib import Path
import logging
import os
from zipfile import ZipFile
from multiprocessing.pool import ThreadPool
import yaml
from itertools import repeat
import time
import platform
from tqdm.notebook import tqdm
from ultralytics.yolo.utils.metrics import ConfusionMatrix
import torch
import numpy as np
def my_test(model, core, data_loader:torch.utils.data.DataLoader, validator, num_samples:int = None):
"""
OpenVINO YOLOv8 model accuracy validation function. Runs model validation on dataset and returns metrics
Parameters:
model (Model): OpenVINO model
data_loader (torch.utils.data.DataLoader): dataset loader
validato: instalce of validator class
num_samples (int, *optional*, None): validate model only on specified number samples, if provided
Returns:
stats: (Dict[str, float]) - dictionary with aggregated accuracy metrics statistics, key is metric name, value is metric value
"""
validator.seen = 0
validator.jdict = []
validator.stats = []
validator.batch_i = 1
validator.confusion_matrix = ConfusionMatrix(nc=validator.nc)
model.reshape({
0: [1, 3, -1, -1]})
num_outputs = len(model.outputs)
compiled_model = core.compile_model(model)
for batch_i, batch in enumerate(tqdm(data_loader, total=num_samples)):
if num_samples is not None and batch_i == num_samples:
break
batch = validator.preprocess(batch)
results = compiled_model(batch["img"])
if num_outputs == 1:
preds = torch.from_numpy(results[compiled_model.output(0)])
else:
preds = [torch.from_numpy(results[compiled_model.output(0)]), torch.from_numpy(results[compiled_model.output(1)])]
preds = validator.postprocess(preds)
validator.update_metrics(preds, batch)
stats = validator.get_stats()
return stats
def print_stats(stats:np.ndarray, total_images:int, total_objects:int):
"""
Helper function for printing accuracy statistic
Parameters:
stats: (Dict[str, float]) - dictionary with aggregated accuracy metrics statistics, key is metric name, value is metric value
total_images (int) - number of evaluated images
total objects (int)
Returns:
None
"""
# print("Boxes:")
mp, mr, map50, mean_ap = stats['metrics/precision(B)'], stats['metrics/recall(B)'], stats['metrics/mAP50(B)'], stats['metrics/mAP50-95(B)']
# Print results
s = ('%20s' + '%12s' * 6) % ('Class', 'Images', 'Labels', 'Precision', 'Recall', '[email protected]', '[email protected]:.95')
print('Boxes:',s)
pf = '%20s' + '%12i' * 2 + '%12.3g' * 4 # print format
print(pf % ('\t\t\tall', total_images, total_objects, mp, mr, map50, mean_ap))
if 'metrics/precision(M)' in stats:
# print("Masks:")
s_mp, s_mr, s_map50, s_mean_ap = stats['metrics/precision(M)'], stats['metrics/recall(M)'], stats['metrics/mAP50(M)'], stats['metrics/mAP50-95(M)']
# Print results
s = ('%20s' + '%12s' * 6) % ('Class', 'Images', 'Labels', 'Precision', 'Recall', '[email protected]', '[email protected]:.95')
print("Masks:",s)
pf = '%20s' + '%12i' * 2 + '%12.3g' * 4 # print format
print(pf % ('\t\t\tall', total_images, total_objects, s_mp, s_mr, s_map50, s_mean_ap))
if __name__ == "__main__":
from ultralytics.yolo.utils import DEFAULT_CFG
from ultralytics.yolo.cfg import get_cfg
from ultralytics.yolo.data.utils import check_det_dataset
from ultralytics import YOLO
from ultralytics.yolo.utils import ops
from openvino.runtime import Core
MODEL_PATH = f"runs/segment/train6/weights"
IR_MODEL_NAME = "v8_seg"
core = Core()
pt_path = f"{
MODEL_PATH}/best.pt"
#将需要量化的onnx模型路径串起来
# onnx_path = f"{MODEL_PATH}/{MODEL_NAME}"
#定义量化后的模型的路径名称
FP32_path = f"{
MODEL_PATH}/FP32_openvino_model/{
IR_MODEL_NAME}_FP32.xml"
FP16_path = f"{
MODEL_PATH}/FP16_openvino_model/{
IR_MODEL_NAME}_FP16.xml"
Int8_path = f"{
MODEL_PATH}/Int8_openvino_model/{
IR_MODEL_NAME}_Int8.xml"
CFG_PATH = 'ultralytics/yolo/cfg/default.yaml'
NUM_TEST_SAMPLES = 300
args = get_cfg(cfg=DEFAULT_CFG)
args.data = str(CFG_PATH)
fp32_model = core.read_model(FP32_path)
fp16_model = core.read_model(FP16_path)
quantized_model = core.read_model(Int8_path)
seg_model = YOLO(pt_path)
seg_validator = seg_model.ValidatorClass(args=args)
seg_validator.data = check_det_dataset('ultralytics/datasets/coco128-seg.yaml')
seg_data_loader = seg_validator.get_dataloader("D:\\Ultralytics\\datasets\\coco128-seg", 1)
seg_validator.is_coco = True
seg_validator.class_map = [1,2,3,4,5]
seg_validator.names = seg_model.model.names
seg_validator.metrics.names = seg_validator.names
seg_validator.nc = seg_model.model.model[-1].nc
seg_validator.nm = 32
seg_validator.process = ops.process_mask
seg_validator.plot_masks = []
# seg_data_loader = create_data_source()
fp32_seg_stats = my_test(fp32_model, core, seg_data_loader, seg_validator, num_samples=None)
fp16_seg_stats = my_test(fp16_model, core, seg_data_loader, seg_validator, num_samples=None)
int8_seg_stats = my_test(quantized_model, core, seg_data_loader, seg_validator, num_samples=None)
print("FP32 model accuracy")
print_stats(fp32_seg_stats, seg_validator.seen, seg_validator.nt_per_class.sum())
print("FP16 model accuracy")
print_stats(fp16_seg_stats, seg_validator.seen, seg_validator.nt_per_class.sum())
print("INT8 model accuracy")
print_stats(int8_seg_stats, seg_validator.seen, seg_validator.nt_per_class.sum())
3. python中的openvino推理
from openvino.runtime import Core, Model
from typing import Tuple
from ultralytics.yolo.utils import ops
import torch
import numpy as np
import cv2
from PIL import Image
from typing import Tuple, Dict
import cv2
from PIL import Image
from ultralytics.yolo.utils.plotting import colors
import time
def plot_one_box(box: np.ndarray, img: np.ndarray, color: Tuple[int, int, int] = None, mask: np.ndarray = None,
label: str = None, line_thickness: int = 5):
"""
Helper function for drawing single bounding box on image
Parameters:
x (np.ndarray): bounding box coordinates in format [x1, y1, x2, y2]
img (no.ndarray): input image
color (Tuple[int, int, int], *optional*, None): color in BGR format for drawing box, if not specified will be selected randomly
mask (np.ndarray, *optional*, None): instance segmentation mask polygon in format [N, 2], where N - number of points in contour, if not provided, only box will be drawn
label (str, *optonal*, None): box label string, if not provided will not be provided as drowing result
line_thickness (int, *optional*, 5): thickness for box drawing lines
"""
# Plots one bounding box on image img
tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness
color = color or [np.random.randint(0, 255) for _ in range(3)]
c1, c2 = (int(box[0]), int(box[1])), (int(box[2]), int(box[3]))
cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA)
if label:
tf = max(tl - 1, 1) # font thickness
t_size = cv2.getTextSize(label, 0, fontScale=tl, thickness=tf)[0]
c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3
cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled
cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl, [225, 255, 255], thickness=tf * 2, lineType=cv2.LINE_AA)
if mask is not None:
image_with_mask = img.copy()
mask
cv2.fillPoly(image_with_mask, pts=[mask.astype(int)], color=color)
img = cv2.addWeighted(img, 0.5, image_with_mask, 0.5, 1)
return img
def draw_results(results: Dict, source_image: np.ndarray, label_map: Dict):
"""
Helper function for drawing bounding boxes on image
Parameters:
image_res (np.ndarray): detection predictions in format [x1, y1, x2, y2, score, label_id]
source_image (np.ndarray): input image for drawing
label_map; (Dict[int, str]): label_id to class name mapping
Returns:
"""
boxes = results["det"]
masks = results.get("segment")
h, w = source_image.shape[:2]
for idx, (*xyxy, conf, lbl) in enumerate(boxes):
label = f'{
label_map[int(lbl)]} {
conf:.2f}'
mask = masks[idx] if masks is not None else None
source_image = plot_one_box(xyxy, source_image, mask=mask, label=label, color=colors(int(lbl)),
line_thickness=1)
return source_image
def letterbox(img: np.ndarray, new_shape: Tuple[int, int] = (640, 640), color: Tuple[int, int, int] = (114, 114, 114),
auto: bool = False, scale_fill: bool = False, scaleup: bool = False, stride: int = 32):
"""
Resize image and padding for detection. Takes image as input,
resizes image to fit into new shape with saving original aspect ratio and pads it to meet stride-multiple constraints
Parameters:
img (np.ndarray): image for preprocessing
new_shape (Tuple(int, int)): image size after preprocessing in format [height, width]
color (Tuple(int, int, int)): color for filling padded area
auto (bool): use dynamic input size, only padding for stride constrins applied
scale_fill (bool): scale image to fill new_shape
scaleup (bool): allow scale image if it is lower then desired input size, can affect model accuracy
stride (int): input padding stride
Returns:
img (np.ndarray): image after preprocessing
ratio (Tuple(float, float)): hight and width scaling ratio
padding_size (Tuple(int, int)): height and width padding size
"""
# Resize and pad image while meeting stride-multiple constraints
shape = img.shape[:2] # current shape [height, width]
if isinstance(new_shape, int):
new_shape = (new_shape, new_shape)
# Scale ratio (new / old)
r = min(new_shape[0] / shape[0], new_shape[1] / shape[1])
if not scaleup: # only scale down, do not scale up (for better test mAP)
r = min(r, 1.0)
# Compute padding
ratio = r, r # width, height ratios
new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r))
dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding
if auto: # minimum rectangle
dw, dh = np.mod(dw, stride), np.mod(dh, stride) # wh padding
elif scale_fill: # stretch
dw, dh = 0.0, 0.0
new_unpad = (new_shape[1], new_shape[0])
ratio = new_shape[1] / shape[1], new_shape[0] / shape[0] # width, height ratios
dw /= 2 # divide padding into 2 sides
dh /= 2
if shape[::-1] != new_unpad: # resize
img = cv2.resize(img, new_unpad, interpolation=cv2.INTER_LINEAR)
top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1))
left, right = int(round(dw - 0.1)), int(round(dw + 0.1))
img = cv2.copyMakeBorder(img, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border
return img, ratio, (dw, dh)
def preprocess_image(img0: np.ndarray):
"""
Preprocess image according to YOLOv8 input requirements.
Takes image in np.array format, resizes it to specific size using letterbox resize and changes data layout from HWC to CHW.
Parameters:
img0 (np.ndarray): image for preprocessing
Returns:
img (np.ndarray): image after preprocessing
"""
# resize
img = letterbox(img0)[0]
# Convert HWC to CHW
img = img.transpose(2, 0, 1)
img = np.ascontiguousarray(img)
return img
def image_to_tensor(image: np.ndarray):
"""
Preprocess image according to YOLOv8 input requirements.
Takes image in np.array format, resizes it to specific size using letterbox resize and changes data layout from HWC to CHW.
Parameters:
img (np.ndarray): image for preprocessing
Returns:
input_tensor (np.ndarray): input tensor in NCHW format with float32 values in [0, 1] range
"""
input_tensor = image.astype(np.float32) # uint8 to fp32
input_tensor /= 255.0 # 0 - 255 to 0.0 - 1.0
# add batch dimension
if input_tensor.ndim == 3:
input_tensor = np.expand_dims(input_tensor, 0)
return input_tensor
def postprocess(
pred_boxes:np.ndarray,
input_hw:Tuple[int, int],
orig_img:np.ndarray,
min_conf_threshold:float = 0.25,
nms_iou_threshold:float = 0.7,
agnosting_nms:bool = False,
max_detections:int = 300,
pred_masks:np.ndarray = None,
retina_mask:bool = False
):
"""
YOLOv8 model postprocessing function. Applied non maximum supression algorithm to detections and rescale boxes to original image size
Parameters:
pred_boxes (np.ndarray): model output prediction boxes
input_hw (np.ndarray): preprocessed image
orig_image (np.ndarray): image before preprocessing
min_conf_threshold (float, *optional*, 0.25): minimal accepted confidence for object filtering
nms_iou_threshold (float, *optional*, 0.45): minimal overlap score for removing objects duplicates in NMS
agnostic_nms (bool, *optiona*, False): apply class agnostinc NMS approach or not
max_detections (int, *optional*, 300): maximum detections after NMS
pred_masks (np.ndarray, *optional*, None): model ooutput prediction masks, if not provided only boxes will be postprocessed
retina_mask (bool, *optional*, False): retina mask postprocessing instead of native decoding
Returns:
pred (List[Dict[str, np.ndarray]]): list of dictionary with det - detected boxes in format [x1, y1, x2, y2, score, label] and segment - segmentation polygons for each element in batch
"""
nms_kwargs = {
"agnostic": agnosting_nms, "max_det":max_detections}
# if pred_masks is not None:
# nms_kwargs["nm"] = 32
preds = ops.non_max_suppression(
torch.from_numpy(pred_boxes),
min_conf_threshold,
nms_iou_threshold,
nc=5,
**nms_kwargs
)
results = []
proto = torch.from_numpy(pred_masks) if pred_masks is not None else None
for i, pred in enumerate(preds):
shape = orig_img[i].shape if isinstance(orig_img, list) else orig_img.shape
if not len(pred):
results.append({
"det": [], "segment": []})
continue
if proto is None:
pred[:, :4] = ops.scale_boxes(input_hw, pred[:, :4], shape).round()
results.append({
"det": pred})
continue
if retina_mask:
pred[:, :4] = ops.scale_boxes(input_hw, pred[:, :4], shape).round()
masks = ops.process_mask_native(proto[i], pred[:, 6:], pred[:, :4], shape[:2]) # HWC
segments = [ops.scale_segments(input_hw, x, shape, normalize=False) for x in ops.masks2segments(masks)]
else:
masks = ops.process_mask(proto[i], pred[:, 6:], pred[:, :4], input_hw, upsample=True)
pred[:, :4] = ops.scale_boxes(input_hw, pred[:, :4], shape).round()
segments = [ops.scale_segments(input_hw, x, shape, normalize=False) for x in ops.masks2segments(masks)]
results.append({
"det": pred[:, :6].numpy(), "segment": segments})
return results
def detect(image:np.ndarray, model:Model):
"""
OpenVINO YOLOv8 model inference function. Preprocess image, runs model inference and postprocess results using NMS.
Parameters:
image (np.ndarray): input image.
model (Model): OpenVINO compiled model.
Returns:
detections (np.ndarray): detected boxes in format [x1, y1, x2, y2, score, label]
"""
num_outputs = len(model.outputs)
preprocessed_image = preprocess_image(image)
input_tensor = image_to_tensor(preprocessed_image)
start_time = time.time()
result = model(input_tensor)
end_time = time.time()
inference_time = (end_time - start_time) * 1000
# print(f"推理时长为:{inference_time}ms")
boxes = result[model.output(0)]
masks = None
if num_outputs > 1:
masks = result[model.output(1)]
input_hw = input_tensor.shape[2:]
detections = postprocess(pred_boxes=boxes, input_hw=input_hw, orig_img=image, pred_masks=masks)
return detections, inference_time
if __name__ == "__main__":
from ultralytics import YOLO
from tqdm import tqdm
import sys
import glob
seg_model_path = 'runs/segment/train6/weights/FP16_openvino_model/v8_seg_FP16.xml'
# seg_model_path = 'runs/segment/train6/weights/FP32_openvino_model/v8_seg_FP32.xml'
# seg_model_path = 'runs/segment/train6/weights/Int8_openvino_model/v8_seg_Int8.xml'
core = Core()
seg_ov_model = core.read_model(seg_model_path)
device = "CPU" # "GPU"
if device != "CPU":
seg_ov_model.reshape({
0: [1, 3, 640, 640]})
seg_compiled_model = core.compile_model(seg_ov_model, device)
SEG_MODEL = YOLO(f'runs/segment/train6/weights/best.pt')
label_map = SEG_MODEL.model.names
image_folder = 'D:\\Ultralytics\\datasets\\coco128-seg\\images\\train2017\\*.jpg'
image_paths = glob.iglob(image_folder)
# Image_path = '2-12.13_RGB.jpg'
total_time = 0
index = 0
for image_path in image_paths:
sys.stdout.write('#')
sys.stdout.flush()
time.sleep(0.1)
# print(f"{(index/40) * 100}%")
input_image = np.array(Image.open(image_path))
detections, inference_time = detect(input_image, seg_compiled_model)
image_with_boxes= draw_results(detections[0], input_image, label_map)
b,g,r = cv2.split(image_with_boxes)
img_1 = cv2.merge([r,g,b])
index += 1
total_time += inference_time
cv2.namedWindow('test',cv2.WINDOW_NORMAL)
cv2.imshow('test', img_1)
cv2.waitKey(0)
# img = Image.fromarray(image_with_boxes)
#img.show()
print("\n",f"一共推理了{
index}张图像,平均耗时:{
total_time / index}ms")