Once a bottleneck has been located, we want to optimize that stage to boost the performance. In this section we present optimization techniques for the application,geometry, rasterization, and pixel processing stages.
一旦找到瓶颈,我们希望优化该阶段以提高性能。在本节中,我们将介绍应用程序、几何、光栅化和像素处理阶段的优化技术。
18.4.1 Application Stage
The application stage is optimized by making the code faster and the memory accesses of the program faster or fewer. Here we touch upon some of the key elements of code optimization that apply to CPUs in general.
通过使代码更快以及使程序的存储器访问更快或更少来优化应用阶段。在这里,我们将讨论一些适用于CPU的代码优化的关键元素。
For code optimization, it is crucial to locate the place in the code where most of the time is spent. A good code profiler is critical in finding these code hot spots,where most time is spent. Optimization efforts are then made in these places. Such locations in the program are often inner loops, pieces of the code that are executed many times each frame.
对于代码优化,找到代码中花费时间最多的地方是至关重要的。一个好的代码剖析器对于发现这些代码热点是至关重要的,因为这些地方花费了大部分时间。然后在这些地方进行优化工作。程序中的这些位置通常是内部循环,即每帧执行多次的代码片段。
The basic rule of optimization is to try a variety of tactics: Reexamine algorithms,assumptions, and code syntax, trying variants as possible. CPU architecture and compiler performance often limit the user’s ability to form an intuition about how to write the fastest code, so question your assumptions and keep an open mind.
优化的基本规则是尝试各种策略:重新检查算法、假设和代码语法,尽可能尝试变体。CPU架构和编译器性能通常会限制用户对如何编写最快的代码形成直觉的能力,因此请质疑您的假设并保持开放的心态。
One of the first steps is to experiment with the optimization flags for the compiler.There are usually a number of different flags to try. Make few, if any, assumptions about what optimization options to use. For example, setting the compiler to use more aggressive loop optimizations could result in slower code. Also, if possible, try different compilers, as these are optimized in different ways, and some are markedly superior. Your profiler can tell you what effect any change has.
第一步是试验编译器的优化标志。通常有许多不同的标志可以尝试。关于使用什么优化选项,几乎不做任何假设。例如,将编译器设置为使用更激进的循环优化可能会导致代码速度变慢。此外,如果可能的话,尝试不同的编译器,因为它们以不同的方式进行优化,而且有些明显更好。您的分析器可以告诉您任何更改会产生什么影响。
Memory Issues内存问题
Years ago the number of arithmetic instructions was the key measure of an algorithm’s efficiency; now the key is memory access patterns. Processor speed has increased much more rapidly than the data transfer rate for DRAM, which is limited by the pin count. Between 1980 and 2005, CPU performance doubled about every two years, and DRAM performance doubled about every six [1060]. This problem is known as the Von Neumann bottleneck or the memory wall. Data-oriented design focuses on cache coherency as a means of optimization.
几年前,算术指令的数量是衡量算法效率的关键;现在关键是内存访问模式。处理器速度的增长比DRAM的数据传输速率要快得多,后者受到引脚数的限制。在1980年到2005年之间,CPU性能大约每两年翻一番,DRAM性能大约每六年翻一番[1060]。这个问题被称为冯诺依曼瓶颈或记忆墙。面向数据的设计侧重于将缓存一致性作为一种优化手段。
On modern GPUs, what matters is the distance traveled by data. Speed and power costs are proportional to this distance. Cache access patterns can make up to an orders-of-magnitude performance difference [1206]. A cache is a small fastmemory area that exists because there is usually much coherence in a program, which the cache can exploit. That is, nearby locations in memory tend to be accessed one after another (spatial locality), and code is often accessed sequentially. Also, memory locations tend to be accessed repeatedly (temporal locality), which the cache also exploits [389]. Processor caches are fast to access, second only to registers for speed.Many fast algorithms work to access data as locally (and as little) as possible.
在现代GPU上,重要的是数据传输的距离。速度和功耗与这个距离成正比。高速缓存访问模式可以造成数量级的性能差异[1206]。缓存是一个小的快速内存区域,因为程序中通常有很多一致性,缓存可以利用这些一致性。也就是说,内存中的邻近位置倾向于被一个接一个地访问(空间局部性),并且代码经常被顺序地访问。此外,内存位置往往会被重复访问(时间局部性),高速缓存也利用了这一点[389]。处理器缓存的访问速度很快,仅次于寄存器。许多快速算法尽可能在本地(并且尽可能少地)访问数据。
Registers and local caches form one end of the memory hierarchy, which extends next to dynamic random access memory (DRAM), then to storage on SSDs and hard disks. At the top are small amounts of fast, expensive memory, at the bottom are large amounts of slow and inexpensive storage. Between each level of the hierarchy the speed drops by some noticeable factor. See Figure 18.1. For example, processor registers are usually accessed in one clock cycle, while L1 cache memory is accessed in a few cycles. Each change in level has an increase in latency in this way. As discussed in Section 3.10, sometimes latency can be hidden by the architecture, but it is always a factor that must be kept in mind.
寄存器和本地缓存构成了内存层次结构的一端,它延伸到动态随机存取存储器(DRAM),然后延伸到固态硬盘和硬盘上的存储。顶部是少量快速昂贵的内存,底部是大量慢速廉价的存储。在等级的每一级之间,速度下降了一些显著的因素。参见图18.1。例如,处理器寄存器通常在一个时钟周期内被访问,而L1高速缓冲存储器在几个周期内被访问。电平的每次变化都会以这种方式增加延迟。正如3.10节所讨论的,有时延迟可能会被架构隐藏,但它始终是一个必须牢记的因素。

Figure 18.1. The memory hierarchy. Speed and cost decrease as we descend the pyramid.
图18.1。记忆层次。随着我们沿着金字塔往下走,速度和成本都在下降。
Bad memory access patterns are difficult to directly detect in a profiler. Good patterns need to be built into the design from the start [1060]. Below is a list of pointers that should be kept in consideration when programming.
错误的内存访问模式很难在探查器中直接检测出来。好的模式需要从一开始就构建到设计中[1060]。下面是编程时应该考虑的指针列表。
• Data that is accessed sequentially in the code should also be stored sequentially in memory. For example, when rendering a triangle mesh, store texture coordinate #0, normal #0, color #0, vertex #0, texture coordinate #1, and normal #1, sequentially in memory if they are accessed in that order. This can also be important on the GPU, as with the post-transform vertex cache (Section 16.4.4).Also see Section 16.4.5 for why storing separate streams of data can be beneficial.
代码中顺序访问的数据也应该顺序存储在存储器中。例如,在渲染三角形网格时,如果按顺序访问纹理坐标#0、法线#0、颜色#0、顶点#0、纹理坐标#1和法线#1,则将它们按顺序存储在内存中。这在GPU上也很重要,就像变换后顶点缓存一样(16.4.4节)。另请参见第16.4.5节,了解为什么存储单独的数据流是有益的。
• Avoid pointer indirection, jumps, and function calls (in critical parts of the code), as these may significantly decrease CPU performance. You get pointer indirection when you follow a pointer to another pointer and so on. Modern CPUs try to speculatively execute instructions (branch prediction) and fetch memory (cache prefetching) to keep all their functional units busy running code.These techniques are highly effective when the code flow is consistent in a loop,but fail with branching data structures such as binary trees, linked lists, and graphs; use arrays instead, as possible. McVoy and Staelin [1194] show a code example that follows a linked list through pointers. This causes cache misses for data both before and after, and their example stalls the CPU more than 100 times longer than it takes to follow the pointer (if the cache could provide the address of the pointer). Smits [1668] notes how flattening a pointer-based tree into a list with skip pointers considerably improves hierarchy traversal.Using a van Emde Boas layout is another way to help avoid cache misses—see Section 19.1.4. High-branching trees are often preferable to binary trees because they reduce the tree depth and so reduce the amount of indirection.
避免间接指针、跳转和函数调用(在代码的关键部分),因为这些可能会显著降低CPU性能。当你沿着一个指针指向另一个指针时,你得到了间接指针,依此类推。现代CPU试图推测性地执行指令(分支预测)和获取内存(缓存预取),以保持所有功能单元忙于运行代码。当代码流在循环中保持一致时,这些技术非常有效,但对于分支数据结构(如二叉树、链表和图)则无效;尽可能使用数组。McVoy和Staelin [1194]显示了一个通过指针遵循链表的代码示例。这会导致之前和之后的数据缓存未命中,并且他们的示例使CPU停止的时间比跟随指针所用的时间长100倍以上(如果缓存可以提供指针的地址)。Smits [1668]注意到如何将基于指针的树展平成一个带有跳过指针的列表,从而极大地改善了层次遍历。使用van Emde Boas布局是帮助避免缓存未命中的另一种方法,请参见第19.1.4节。高分支树通常比二叉树更可取,因为它们减少了树的深度,从而减少了间接性。
• Aligning frequently used data structures to multiples of the cache line size can significantly improve overall performance. For example, 64 byte cache lines are common on Intel and AMD processors [1206]. Compiler options can help, but it is wise to design your data structures with alignment, called padding, in mind.Tools such as VTune and CodeAnalyst for Windows and Linux, Instruments for the Mac, and the open-source Valgrind for Linux can help identify caching bottlenecks. Alignment can also affect GPU shader performance [331].
将经常使用的数据结构调整为高速缓存行大小的倍数,可以显著提高整体性能。例如,64字节高速缓存线在英特尔和AMD处理器上很常见[1206]。编译器选项可能会有所帮助,但是在设计数据结构时,最好记住对齐,即填充。用于Windows和Linux的VTune和CodeAnalyst、用于Mac的Instruments以及用于Linux的开源Valgrind等工具可以帮助识别缓存瓶颈。对齐也会影响GPU着色器的性能[331]。
• Try different organizations of data structures. For example, Hecker [698] shows how a surprisingly large amount of time was saved by testing a variety of matrix structures for a simple matrix multiplier. An array of structures,
尝试不同的数据结构组织。例如,Hecker [698]展示了如何通过测试简单矩阵乘法器的各种矩阵结构来节省大量时间。一组结构,
struct Vertex { float x,y,z ;};
Vertex myvertices [1000];
or a structure of arrays,
或者阵列结构,
struct VertexChunk { float x [1000] , y [1000] , z [1000];};
VertexChunk myvertices ;
may work better for a given architecture. This second structure is better for using SIMD commands, but as the number of vertices goes up, the chance of a cache miss increases. As the array size increases, a hybrid scheme,
可能更适合给定的架构。第二种结构更适合使用SIMD命令,但是随着顶点数量的增加,缓存未命中的几率也会增加。随着阵列大小的增加,混合方案,
struct Vertex4 { float x[4] ,y[4] ,z [4];};
Vertex4 myvertices [250];
may be the best choice.
可能是最好的选择。
• It is often better to allocate a large pool of memory at start-up for objects of the same size, and then use your own allocation and free routines for handling the memory of that pool [113, 736]. Libraries such as Boost provide pool allocation. A set of contiguous records is more likely to be cache coherent than those created by separate allocations. That said, for languages with garbage collection, such as C# and Java, pools can actually reduce performance.
通常最好在启动时为相同大小的对象分配一个大的内存池,然后使用自己的分配和自由例程来处理该池的内存[113,736]。Boost等库提供了池分配。一组连续的记录比那些由单独分配创建的记录更有可能是缓存一致的。也就是说,对于带有垃圾收集的语言,比如C#和Java,池实际上会降低性能。
While not directly related to memory access patterns, it is worthwhile to avoid allocating or freeing memory within the rendering loop. Use pools and allocate scratch space once, and have stacks, arrays, and other structures only grow (using a variable or flags to note which elements should be treated as deleted).
虽然与内存访问模式没有直接关系,但避免在渲染循环中分配或释放内存是值得的。使用池并分配一次暂存空间,并且堆栈、数组和其他结构只会增长(使用变量或标志来注意哪些元素应被视为已删除).
18.4.2 API Calls API调用
Throughout this book we have given advice based on general trends in hardware. For example, indexed vertex buffers objects are usually the fastest way to provide the accelerator with geometric data (Section 16.4.5). This section is about how to best call the graphics API itself. Most graphics APIs have similar architectures, and there are well-established ways of using them efficiently.
在本书中,我们根据硬件的总体趋势给出了建议。例如,索引顶点缓冲对象通常是为加速器提供几何数据的最快方式(第16.4.5节)。这一节是关于如何最好地调用图形API本身。大多数图形API都有相似的体系结构,并且有很好的有效使用它们的方法。
Understanding object buffer allocation and storage is basic to efficient rendering [1679]. For a desktop system with a CPU and a separate, discrete GPU, each normally has its own memory. The graphics driver is usually in control of where objects reside, but it can be given hints of where best to store them. A common classification is static versus dynamic buffers. If the buffer’s data are changing each frame, using a dynamic buffer, which requires no permanent storage space on the GPU, is preferable. Consoles, laptops with low-power integrated GPUs, and mobile devices usually have unified memory, where the GPU and CPU share the same physical memory. Even in these setups, allocating a resource in the right pool matters. Correctly tagging a resource as CPU-only or GPU-only can still yield benefits. In general, if a memory area has to be accessed by both chips, when one writes to it the other has to invalidate its caches—an expensive operation—to be sure not to get stale data.
理解对象缓冲分配和存储是高效渲染的基础[1679]。对于带有CPU和独立的GPU的桌面系统,通常每个都有自己的内存。图形驱动程序通常控制着对象的位置,但是也可以提示它在哪里存储它们最好。常见的分类是静态与动态缓冲器。如果缓冲区的数据每帧都在变化,那么使用动态缓冲区更好,因为它不需要GPU上的永久存储空间。控制台、具有低功耗集成GPU的笔记本电脑和移动设备通常具有统一的内存,其中GPU和CPU共享相同的物理内存。即使在这些设置中,在正确的池中分配资源也很重要。正确地将资源标记为CPU专用或GPU专用仍然有好处。一般来说,如果一个内存区域必须由两个芯片访问,当一个芯片写入时,另一个芯片必须使其缓存无效(这是一个昂贵的操作),以确保不会获得过时的数据。
If an object is not deforming, or the deformations can be carried out entirely by shader programs (e.g., skinning), then it is profitable to store the data for the object in GPU memory. The unchanging nature of this object can be signaled by storing it as a static buffer. In this way, it does not have to be sent across the bus for every frame rendered, thus avoiding any bottleneck at this stage of the pipeline. The internal memory bandwidth on a GPU is normally much higher than the bus between CPU and GPU.
如果对象没有变形,或者变形可以完全由着色器程序执行(例如,蒙皮),那么将对象的数据存储在GPU存储器中是有利的。这个对象的不变性质可以通过将其存储为静态缓冲区来表示。通过这种方式,不必为渲染的每一帧都通过总线发送,从而避免了流水线这一阶段的任何瓶颈。GPU上的内部内存带宽通常远高于CPU和GPU之间的总线。
State Changes 状态更改
Calling the API has several costs associated with it. On the application side, more calls mean more application time spent, regardless of what the calls actually do. This cost can be minimal or noticeable, and a null driver can help identify it. Query functions that depend on values from the GPU can potentially halve the frame rate due to stalls from synchronization with the CPU [1167]. Here we will delve into optimizing a common graphics operation, preparing the pipeline to draw a mesh. This operation may involve changing the state, e.g., setting the shaders and their uniforms, attaching textures, changing the blend state or the color buffer used, and so on.
调用API有几个相关的成本。在应用程序方面,更多的调用意味着花费更多的应用程序时间,而不管调用实际做什么。这个成本可以是最小的或显著的,空驱动程序可以帮助识别它。依赖于来自GPU的值的查询函数可能会由于与CPU的同步暂停而导致帧速率减半[1167]。在这里,我们将深入研究如何优化常见的图形操作,准备绘制网格的管道。此操作可能涉及更改状态,例如,设置着色器及其制服、附加纹理、更改混合状态或使用的颜色缓冲区等。
A major way for the application to improve performance is to minimize state changes by grouping objects with a similar rendering state. Because the GPU is an extremely complex state machine, perhaps the most complex in computer science,changing the state can be expensive. While a little of the cost can involve the GPU,most of the expense is from the driver’s execution on the CPU. If the GPU maps well to the API, the state change cost tends to be predictable, though still significant. If the GPU has a tight power constraint or limited silicon footprint, such as with some mobile devices, or has a hardware bug to work around, the driver may have to perform heroics that cause unexpectedly high costs. State change costs are mostly on the CPU side, in the driver.
应用程序提高性能的一个主要方法是通过将具有相似呈现状态的对象分组来最小化状态更改。因为GPU是一种极其复杂的状态机,可能是计算机科学中最复杂的状态机,改变状态的代价可能非常昂贵。虽然有一小部分成本涉及到GPU,但大部分成本来自于驱动程序在CPU上的执行。如果GPU能很好地映射到API,那么状态变化的成本往往是可以预测的,尽管仍然很重要。如果GPU有一个严格的功率限制或有限的硅占用,例如在一些移动设备上,或有一个硬件错误需要解决,驱动程序可能不得不执行导致意外高成本的英雄行为。状态更改成本主要在CPU端,即驱动程序中。
One concrete example is how the PowerVR architecture supports blending. In older APIs blending is specified using a fixed-function type of interface. PowerVR’s blending is programmable, which means that their driver has to patch the current blend state into the pixel shader [699]. In this case a more advanced design does not map well to the API and so incurs a significant setup cost in the driver. While throughout this chapter we note that hardware architecture and the software running it can affect the importance of various optimizations, this is particularly true for state change costs. Even the specific GPU type and driver release may have an effect.While reading, please imagine the phrase “your mileage may vary” stamped in large red letters over every page of this section.
一个具体的例子是PowerVR架构如何支持混合。在旧API中,混合是使用固定函数类型的接口指定的。PowerVR的混合是可编程的,这意味着他们的驱动程序必须将当前混合状态修补到像素着色器中[699]。在这种情况下,更高级的设计不能很好地映射到API,因此会在驱动程序中产生很大的设置成本。尽管在本章中,我们注意到硬件架构和运行它的软件可能会影响各种优化的重要性,但对于状态更改成本来说尤其如此。甚至特定的GPU类型和驱动程序版本也可能产生影响。阅读时,请想象在本节的每一页上用红色大字印上的短语“你的里程可能不同”。
Everitt and McDonald [451] note that different types of state changes vary considerably in cost, and give some rough idea as to how many times a second a few could be performed on an NVIDIA OpenGL driver. Here is their order, from most expensive to least, as of 2014:
Everitt和McDonald[451]注意到,不同类型的状态更改在成本上有很大差异,并给出了一些粗略的想法,说明NVIDIA OpenGL驱动程序每秒可以执行多少次。以下是截至2014年的订单,从最贵到最便宜:
• Render target (framebuffer object), ∼60k/sec.
• Shader program, ∼300k/sec.
• Blend mode (ROP), such as for transparency.
• Texture bindings, ∼1.5M/sec.
• Vertex format.
• Uniform buffer object (UBO) bindings.
• Vertex bindings.
• Uniform updates, ∼10M/sec.
•渲染目标(帧缓冲区对象),∼60k/秒。
•着色器程序,∼300k/秒。
•混合模式(ROP),例如透明度。
•纹理绑定,∼1.5M/秒。
•顶点格式。
•统一缓冲区对象(UBO)绑定。
•顶点绑定。
•统一更新,∼10M/秒。
This approximate cost order is borne out by others [488, 511, 741]. One even more expensive change is switching between the GPU’s rendering mode and its compute shader mode [1971]. Avoiding state changes can be achieved by sorting the objects to be displayed by grouping them by shader, then by textures used, and so on down the cost order. Sorting by state is sometimes called batching.
此近似成本订单由其他人承担[488,511,741]。一个更昂贵的改变是在GPU的渲染模式和计算着色器模式之间切换[1971]。避免状态更改可以通过对要显示的对象进行排序来实现,方法是按着色器对对象进行分组,然后按使用的纹理进行分组,以此类推。按状态排序有时称为批处理。
Another strategy is to restructure the objects’ data so that more sharing occurs.A common way to minimize texture binding changes is to put several texture images into one large texture or, better yet, a texture array. If the API supports it,bindless textures are another option to avoid state changes (Section 6.2.5). Changing the shader program is usually relatively expensive compared to updating uniforms,so variations within a class of materials may be better represented by a single shader that uses “if” statements. You might also be able to make larger batches by sharing a shader [1609]. Making shaders more complex can also lower performance on the GPU, however. Measuring to see what is effective is the only foolproof way to know.
另一个策略是重组对象的数据,以便进行更多的共享。最小化纹理绑定更改的一种常见方法是将多个纹理图像放入一个大纹理中,或者更好地放入一个纹理数组中。如果API支持,无绑定纹理是避免状态更改的另一种选择(第6.2.5节)。与更新制服相比,更改着色器程序通常相对昂贵,因此,使用“if”语句的单个着色器可以更好地表示一类材质中的变化。您还可以通过共享着色器来进行更大的批处理[1609]。但是,使着色器更复杂也会降低GPU的性能。衡量什么是有效的是唯一万无一失的方法。
Making fewer, more effective calls to the graphics API can yield some additional savings. For example, often several uniforms can be defined and set as a group, so binding a single uniform buffer object is considerably more efficient [944]. In DirectX these are called constant buffers. Using these properly saves both time per function and time spent error-checking inside each individual API call [331, 613].
对图形API进行更少、更有效的调用可以带来一些额外的节省。例如,通常可以将多个统一定义并设置为一个组,因此绑定单个统一缓冲区对象的效率要高得多[944]。在DirectX中,这些称为常量缓冲区。正确使用这些函数可以节省每个函数的时间和在每个单独的API调用中检查错误所花费的时间[331,613]。
Modern drivers often defer setting state until the first draw call encountered. If redundant API calls are made before then, the driver will filter these out, thus avoiding the need to perform a state change. Often a dirty flag is used to note that a state change is needed, so going back to a base state after each draw call may become costly. For example, you may want to assume state X is off by default when you are about to draw an object. One way to achieve this is “Enable(X); Draw(M1); Disable(X);” then “Enable(X); Draw(M2); Disable(X);” thus restoring the state after each draw.However, it is also likely to waste significant time setting the state again between the two draw calls, even though no actual state change occurs between them.
现代驱动程序通常会推迟设置状态,直到遇到第一次绘制调用。如果在此之前进行了冗余API调用,驱动程序将过滤掉这些调用,从而避免执行状态更改的需要。通常使用脏标志来表示需要更改状态,因此在每次调用draw后返回基本状态可能会花费很大的代价。例如,当您要绘制对象时,您可能希望假定默认情况下状态X处于关闭状态。实现这一点的一种方法是“启用(X);绘制(M1);禁用(X)”然后“启用(X);绘制(M2);禁用(X)”从而恢复每次绘制后的状态。但是,即使在两个绘制调用之间没有实际的状态更改,也可能会浪费大量时间来再次设置状态。
Usually the application has higher-level knowledge of when a state change is needed. For example, changing from a “replace” blending mode for opaque surfaces to an “over” mode for transparent ones normally needs to be done once during the frame. Issuing the blend mode before rendering each object can easily be avoided.Galeano [511] shows how ignoring such filtering and issuing unneeded state calls would have cost their WebGL application up to nearly 2 ms/frame. However, if the driver already does such redundancy filtering efficiently, performing this same testing per call in the application can be a waste. How much effort to spend filtering out API calls primarily depends on the underlying driver [443, 488, 741].
通常,应用程序具有更高级别的状态更改知识。例如,从不透明曲面的“替换”混合模式更改为透明曲面的的“覆盖”模式通常需要在帧期间执行一次。可以轻松避免在渲染每个对象之前发出混合模式。Galeano[511]展示了忽略这种过滤和发出不必要的状态调用将如何使WebGL应用程序的成本达到近2ms/帧。但是,如果驱动程序已经有效地进行了这种冗余过滤,那么在应用程序中每次调用执行相同的测试可能是一种浪费。过滤掉API调用的工作量主要取决于底层驱动程序[443488741]。
Consolidating and Instancing 整合和实例化
Using the API efficiently avoids having the CPU be the bottleneck. One other concern with the API is the small batch problem. If ignored, this can be a significant factor affecting performance in modern APIs. Simply put, a few triangle-filled meshes are much more efficient to render than many small, simple ones. This is because there is a fixed-cost overhead associated with each draw call, a cost paid for processing a primitive, regardless of size.
有效地使用API可以避免CPU成为瓶颈。API的另一个问题是小批量问题。如果忽略,这可能是影响现代API性能的一个重要因素。简单地说,几个三角形填充网格的渲染效率要比许多小而简单的网格高得多。这是因为每个绘制调用都有一个固定的开销,不管大小,都是为处理原语而支付的开销。
Back in 2003, Wloka [1897] showed that drawing two (relatively small) triangles per batch was a factor of 375 away from the maximum throughput for the GPU tested. Instead of 150 million triangles per second, the rate was 0.4 million, for a 2.7 GHz CPU. For a scene rendered consisting of many small and simple objects, each with only a few triangles, performance is entirely CPU-bound by the API; the GPU has no ability to increase it. That is, the processing time on the CPU for the draw call is greater than the amount of time the GPU takes to actually draw the mesh, so the GPU is starved.
早在2003年,Wloka[1897]就表明,每批绘制两个(相对较小的)三角形与测试GPU的最大吞吐量相差375倍。对于2.7 GHz的CPU,速率为40万,而不是每秒1.5亿个三角形。对于由许多小而简单的对象组成的场景,每个对象只有几个三角形,性能完全受API的CPU限制;GPU没有增加它的能力。也就是说,绘制调用在CPU上的处理时间大于GPU实际绘制网格所需的时间,因此GPU处于饥饿状态。
Wloka’s rule of thumb is that “You get X batches per frame.” This is a maximum number of draw calls you can make per frame, purely due to the CPU being the limiting factor. In 2003, the breakpoint where the API was the bottleneck was about 130 triangles per object. Figure 18.2 shows how the breakpoint rose in 2006 to 510 triangles per mesh. Times have changed. Much work was done to ameliorate this draw call problem, and CPUs became faster. The recommendation back in 2003 was 300 draw calls per frame; in 2012, 16,000 draw calls per frame was one team’s ceiling [1381]. That said, even this number is not enough for some complicated scenes.With modern APIs such as DirectX 12, Vulkan, and Metal, the driver cost may itself be minimized—this is one of their major advantages [946]. However, the GPU can have its own fixed costs per mesh.
Wloka的经验法则是:“每帧可以获得X个批次。”这是每帧可以进行的绘制调用的最大数量,纯粹是因为CPU是限制因素。2003年,API成为瓶颈的断点是每个对象大约130个三角形。图18.2显示了2006年断点如何上升到每网格510个三角形。时代变了。为了改善这个绘制调用问题,做了很多工作,CPU变得更快了。2003年的建议是每帧300次抽签;2012年,每帧16000次平局是一支球队的上限[1381]。也就是说,即使这个数字对于一些复杂的场景来说也不够。使用DirectX 12、Vulkan和Metal等现代API,驱动程序成本本身可以最小化,这是它们的主要优势之一[946]。但是,GPU可以有其自己的固定网格成本。

Figure 18.2. Batch performance benchmarks for an Intel Core 2 Duo 2.66 GHz CPU using an NVIDIA G80 GPU, running DirectX 10. Batches of varying size were run and timed under different conditions. The “Low” conditions are for triangles with just the position and a constant-color pixel shader; the other set of tests is for reasonable meshes and shading. “Single” is rendering a single batch many times. “Instancing” reuses the mesh data and puts the per-instance data in a separate stream.“Constants” is a DirectX 10 method where instance data are put in constant memory. As can be seen, small batches hurt all methods, but instancing gives proportionally much faster performance.At a few hundred triangles, performance levels out, as the bottleneck becomes how fast vertices are retrieved from the vertex buffer and caches. (Graph courtesy of NVIDIA Corporation.)
图18.2.使用NVIDIA G80 GPU、运行DirectX 10的Intel Core 2 Duo 2.66 GHz CPU的批处理性能基准。不同大小的批处理在不同条件下运行和计时。“低”条件适用于仅具有位置和恒定颜色像素着色器的三角形;另一组测试是合理的网格和阴影。“Single”多次渲染单个批次。“实例化”重用网格数据,并将每个实例的数据放入单独的流中。“Constants”是一种DirectX 10方法,其中实例数据存储在常量内存中。可以看出,小批量会损害所有方法,但实例化会相应地提高性能。在几百个三角形的情况下,性能会下降,因为瓶颈变成从顶点缓冲区和缓存中检索顶点的速度。(图表由NVIDIA Corporation提供。)
One way to reduce the number of draw calls is to consolidate several objects into a single mesh, which needs only one draw call to render the set. For sets of objects that use the same state and are static, at least with respect to one another, consolidation can be done once and the batch can be reused each frame [741, 1322]. Being able to consolidate meshes is another reason to consider avoiding state changes by using a common shader and texture-sharing techniques. The cost savings from consolidation are not just from avoiding API draw calls. There are also savings from the application itself handling fewer objects. However, having batches that are considerably larger than needed can make other algorithms, such as frustum culling, be less effective [1381].One practice is to use a bounding volume hierarchy to help find and group static objects that are near each other. Another concern with consolidation is selection,since all the static objects are undifferentiated, in one mesh. A typical solution is to store an object identifier at each vertex in the mesh.
减少绘制调用次数的一种方法是将多个对象合并到一个网格中,该网格只需要一次绘制调用即可渲染集。对于使用相同状态且至少相对于彼此是静态的对象集,可以进行一次合并,并且可以在每一帧重复使用批次[741、1322]。能够合并网格是考虑使用常用着色器和纹理共享技术避免状态更改的另一个原因。整合带来的成本节约不仅仅来自于避免API调用。应用程序本身处理较少对象也可以节省成本。然而,具有比所需大得多的批次可能会使其他算法(如截头体剔除)的效率降低[1381]。一种做法是使用边界体积层次来帮助查找和分组彼此靠近的静态对象。合并的另一个问题是选择,因为在一个网格中所有静态对象都是无差别的。典型的解决方案是在网格中的每个顶点存储对象标识符。
The other approach to minimize application processing and API costs is to use some form of instancing [232, 741, 1382]. Most APIs support the idea of having an object and drawing it several times in a single call. This is typically done by specifying a base model and providing a separate data structure that holds information about each specific instance desired. Beyond position and orientation, other attributes could be specified per instance, such as leaf colors or curvature due to the wind, or anything else that could be used by shader programs to affect the model. Lush jungle scenes can be created by liberal use of instancing. See Figure 18.3. Crowd scenes are a good fit for instancing, with each character appearing unique by selecting different body parts from a set of choices. Further variation can be added by random coloring and decals.Instancing can also be combined with level of detail techniques [122, 1107, 1108]. See Figure 18.4 for an example.
最小化应用程序处理和API成本的另一种方法是使用某种形式的实例化[2327411382]。大多数API都支持拥有一个对象并在一次调用中多次绘制该对象的想法。这通常是通过指定一个基本模型并提供一个单独的数据结构来完成的,该数据结构保存关于每个所需的特定实例的信息。除了位置和方向之外,还可以为每个实例指定其他属性,例如树叶颜色或风引起的曲率,或者着色器程序可以使用的任何其他属性来影响模型。可以通过自由使用实例化来创建茂盛的丛林场景。见图18.3。人群场景非常适合实例化,通过从一组选择中选择不同的身体部位,每个角色都显得独特。可以通过随机着色和贴花添加更多变化。实例化还可以与细节级别技术相结合[12211071108]。示例见图18.4。

Figure 18.3. Vegetation instancing. All objects the same color in the lower image are rendered in a single draw call [1869]. (Image from CryEngine1, courtesy of Crytek.)
图18.3.植被实例化。下部图像中相同颜色的所有对象都在单个绘制调用【1869】中渲染。(图片来自CryEngine1 ,由Crytek提供。)

Figure 18.4. Crowd scene. Using instancing minimizes the number of draw calls needed. Level of detail techniques are also used, such as rendering impostors for distant models [1107, 1108]. (Image courtesy of Jonathan Ma¨ım, Barbara Yersin, Mireille Clavien, and Daniel Thalmann.)
图18.4.人群场景。使用实例化可以最小化所需的绘制调用数。还使用了细节级别技术,例如为远距离模型渲染冒名顶替者[11071108]。(图片由Jonathan Maım、Barbara Yersin、Mireille Clavien和Daniel Thalmann提供)
A concept that combines consolidation and instancing is called merge-instancing,where a consolidated mesh contains objects that may in turn be instanced [146, 1382].In theory, the geometry shader can be used for instancing, as it can create duplicate data of an incoming mesh. In practice, if many instances are needed, this method can be slower than using instancing API commands. The intent of the geometry shader is to perform local, small-scale amplification of data [1827]. In addition, for some architectures, such as Mali’s tile-based renderer, the geometry shader is implemented in software. To quote Mali’s best practices guide [69], “Find a better solution to your problem. Geometry shaders are not your solution.”
将合并和实例化相结合的概念称为合并实例化,其中合并网格包含可以依次实例化的对象[1461382]。理论上,几何体着色器可以用于实例化,因为它可以创建传入网格的重复数据。在实践中,如果需要许多实例,这种方法可能比使用实例API命令慢。几何着色器的目的是对数据进行局部、小规模放大[1827]。此外,对于某些架构,例如马里的基于瓦片的渲染器,几何着色器是在软件中实现的。引用马里的最佳实践指南[69],“为您的问题找到更好的解决方案。几何着色器不是您的解决方案”
18.4.3 Geometry Stage几何阶段
The geometry stage is responsible for transforms, per-vertex lighting, clipping, projection,and screen mapping. Other chapters discuss ways to reduce the amount of data flowing through the pipeline. Efficient triangle mesh storage, model simplification,and vertex data compression (Chapter 16) all save both processing time and memory.Techniques such as frustum and occlusion culling (Chapter 19) avoid sending the full primitive itself down the pipeline. Adding such large-scale techniques on the CPU can entirely change performance characteristics of the application and so are worth trying early on in development. On the GPU such techniques are less common. One notable example is how the compute shader can be used to perform various types of culling [1883, 1884].
几何体阶段负责变换、逐顶点照明、剪裁、投影和屏幕映射。其他章节讨论了减少流经管道的数据量的方法。高效的三角形网格存储、模型简化和顶点数据压缩(第16章)都节省了处理时间和内存。诸如截头体和遮挡剔除(第19章)之类的技术避免了将整个基本体本身发送到管道中。在CPU上添加这样的大规模技术可以完全改变应用程序的性能特征,因此值得在开发早期尝试。在GPU上,这种技术不太常见。一个值得注意的例子是计算着色器如何用于执行各种类型的剔除[18831884]。
The effect of elements of lighting can be computed per vertex, per pixel (in the pixel processing stage), or both. Lighting computations can be optimized in several ways. First, the types of light sources being used should be considered. Is lighting needed for all triangles? Sometimes a model only requires texturing, texturing with colors at the vertices, or simply colors at the vertices.
照明元素的效果可以按顶点、按像素(在像素处理阶段)或两者计算。可以通过多种方式优化照明计算。首先,应考虑使用的光源类型。所有三角形都需要照明吗?有时,模型只需要纹理,在顶点处使用颜色进行纹理,或者只需要在顶点处添加颜色。
If light sources are static with respect to geometry, then the diffuse and ambient lighting can be precomputed and stored as colors at the vertices. Doing so is often referred to as “baking” on the lighting. A more elaborate form of prelighting is to precompute the diffuse global illumination in a scene (Section 11.5.1). Such illumination can be stored as colors or intensities at the vertices or as light maps.
如果光源相对于几何体是静态的,则可以预先计算漫反射和环境光,并将其存储为顶点处的颜色。这样做通常被称为照明上的“烘焙”。更复杂的预照明形式是预计算场景中的漫反射全局照明(第11.5.1节)。这样的照明可以存储为顶点处的颜色或强度或光照贴图。
For forward rendering systems the number of light sources influences the performance of the geometry stage. More light sources means more computation. A common way to lessen work is to disable or trim down local lighting and instead use an environment map (Section 10.5).
对于前向渲染系统,光源的数量会影响几何阶段的性能。更多的光源意味着更多的计算。减少工作量的常用方法是禁用或修剪局部照明,而使用环境贴图(第10.5节)。
18.4.4 Rasterization Stage光栅化阶段
Rasterization can be optimized in a few ways. For closed (solid) objects and for objects that will never show their backfaces (for example, the back side of a wall in a room), backface culling should be turned on (Section 19.3). This reduces the number of triangles to be rasterized by about half and so reduces the load on triangle traversal. In addition, this can be particularly beneficial when the pixel shading computation is expensive, as backfaces are then never shaded.
光栅化可以通过几种方式进行优化。对于闭合(实体)对象和永远不会显示其背面的对象(例如,房间中墙的背面),应启用背面消隐(第19.3节)。这将要光栅化的三角形数量减少了大约一半,从而减少了三角形遍历的负荷。此外,当像素着色计算昂贵时,这可能特别有益,因为背面永远不会着色。
18.4.5 Pixel Processing Stage像素处理阶段
Optimizing pixel processing is often profitable, since usually there are many more pixels to shade than vertices. There are notable exceptions. Vertices always have to be processed, even if a draw ends up not generating any visible pixels. Ineffective culling in the rendering engine might make the vertex shading cost exceed pixel shading.Too small a triangle not only causes more vertex shading evaluation than may be needed, but also can create more partial-covered quads that cause additional work.More important, textured meshes that cover only a few pixels often have low thread occupancy rates. As discussed in Section 3.10, there is a large time cost in sampling a texture, which the GPU hides by switching to execute shader programs on other fragments, returning later when the texture data has been fetched. Low occupancy can result in poor latency hiding. Complex shaders that use a high number of registers can also lead to low occupancy by allowing fewer threads to be available at one time (Section 23.3). This condition is referred to as high register pressure. There are other subtleties, e.g., frequent switching to other warps may cause more cache misses.Wronski [1911, 1914] discusses various occupancy problems and solutions.
优化像素处理通常是有利可图的,因为通常要着色的像素比顶点多得多。有明显的例外。始终必须处理顶点,即使绘制最终没有生成任何可见像素。渲染引擎中的无效剔除可能会使顶点着色成本超过像素着色。三角形太小不仅会导致顶点着色评估超过所需的数量,而且还会创建更多局部覆盖的四边形,从而导致额外的工作。更重要的是,仅覆盖少数像素的纹理网格通常具有低线程占用率。如第3.10节所述,对纹理进行采样会耗费大量时间,GPU会通过切换到对其他片段执行着色器程序来隐藏纹理,并在提取纹理数据后返回。占用率低可能导致延迟隐藏较差。使用大量寄存器的复杂着色器也可能导致占用率低,因为它允许一次使用更少的线程(第23.3节)。这种情况称为寄存器压力高。还有其他微妙之处,例如,频繁切换到其他扭曲可能会导致更多缓存未命中。Wronski[1911914]讨论了各种入住问题和解决方案。
To begin, use native texture and pixel formats, i.e., use the formats that the graphics accelerator uses internally, to avoid a possible expensive transform from one format to another [278]. Two other texture-related techniques are loading only the mipmap levels needed (Section 19.10.1) and using texture compression (Section 6.2.6). As usual, smaller and fewer textures mean less memory used, which in turn means lower transfer and access times. Texture compression also can improve cache performance,since the same amount of cache memory is occupied by more pixels.
首先,使用原生纹理和像素格式,即使用图形加速器内部使用的格式,以避免从一种格式到另一种格式的可能的昂贵转换[278]。另外两种与纹理相关的技术是仅加载所需的mipmap级别(第19.10.1节)和使用纹理压缩(第6.2.6节)。与往常一样,越来越小的纹理意味着更少的内存使用,这反过来意味着更低的传输和访问时间。纹理压缩还可以提高缓存性能,因为相同数量的缓存内存被更多的像素占用。
One level of detail technique is to use different pixel shader programs, depending on the distance of the object from the viewer. For example, with three flying saucer models in a scene, the closest might have an elaborate bump map for surface details that the two farther away do not need. In addition, the farthest saucer might have specular highlighting simplified or removed altogether, both to simplify computations and to reduce “fireflies,” i.e., sparkle artifacts from undersampling. Using a color per vertex on simplified models can give the additional benefit that no state change is needed due to the texture changing.
一种细节技术是使用不同的像素着色器程序,具体取决于对象与查看器的距离。例如,在一个场景中有三个飞碟模型,距离最近的可能会有一个精心制作的凹凸贴图,用于两个更远的不需要的表面细节。此外,最远的碟子可能会简化或完全删除镜面反射高光,以简化计算并减少“萤火虫”,即由于采样不足而产生的闪光伪影。在简化模型上使用逐顶点颜色可以提供额外的好处,即不需要由于纹理变化而改变状态。
The pixel shader is invoked only if the fragment is visible at the time the triangle is rasterized. The GPU’s early-z test (Section 23.7) checks the z-depth of the fragment against the z-buffer. If not visible, the fragment is discarded without any pixel shader evaluation, saving considerable time. While the z-depth can be modified by the pixel shader, doing so means that early-z testing cannot be performed.
仅当三角形光栅化时片段可见时,才会调用像素着色器。GPU的早期z测试(第23.7节)对照z缓冲区检查片段的z深度。如果不可见,片段将被丢弃而不进行任何像素着色器评估,从而节省大量时间。虽然像素着色器可以修改z深度,但这样做意味着无法执行早期z测试。
To understand the behavior of a program, and especially the load on the pixel processing stage, it is useful to visualize the depth complexity, which is the number of surfaces that cover a pixel. Figure 18.5 shows an example. One simple method of generating a depth complexity image is to use a call like OpenGL’s glBlendFunc(GL ONE,GL ONE), with z-buffering disabled. First, the image is cleared to black. All objects in the scene are then rendered with the color (1/255, 1/255, 1/255). The effect of the blend function setting is that for each primitive rendered, the values of the written pixels will increase by one intensity level. A pixel with a depth complexity of 0 is then black and a pixel of depth complexity 255 is full white, (255, 255, 255).
为了理解程序的行为,尤其是像素处理阶段的负载,可视化深度复杂度是非常有用的,深度复杂度就是覆盖像素的曲面数量。图18.5显示了一个示例。生成深度复杂度图像的一种简单方法是使用类似OpenGL的glBlendFunc(GL ONE,GL ONE)的调用,禁用z缓冲。首先,图像被清除为黑色。然后,场景中的所有对象都将使用颜色(1/255、1/255和1/255)进行渲染。混合函数设置的效果是,对于渲染的每个基本体,写入像素的值将增加一个强度级别。深度复杂度为0的像素为黑色,深度复杂度255的像素为全白色(255255255)。

Figure 18.5. The depth complexity of the scene on the left is shown on the right. (Images created using NVPerfHUD from NVIDIA Corporation.)
图18.5.左侧场景的深度复杂度如右图所示。(使用NVIDIA Corporation的NVPerfHUD创建的图像。)
The amount of pixel overdraw is related to how many surfaces actually were rendered.The number of times the pixel shader is evaluated can be found by rendering the scene again, but with the z-buffer enabled. Overdraw is the amount of effort wasted computing a shade for a surface that is then hidden by a later pixel shader invocation.An advantage of deferred rendering (Section 20.1), and ray tracing for that matter, is that shading is performed after all visibility computations are performed.
像素过度绘制的数量与实际渲染的曲面数量有关。通过再次渲染场景,但启用z缓冲区,可以找到像素着色器的求值次数。Overdraw是为曲面计算阴影所浪费的工作量,该曲面随后被稍后的像素着色器调用隐藏。延迟渲染(第20.1节)和光线跟踪的一个优点是,在执行所有可见性计算后执行着色。
Say two triangles cover a pixel, so the depth complexity is two. If the farther triangle is drawn first, the nearer triangle overdraws it, and the amount of overdraw is one. If the nearer is drawn first, the farther triangle fails the depth test and is not drawn, so there is no overdraw. For a random set of opaque triangles covering a pixel,the average number of draws is the harmonic series [296]:
假设两个三角形覆盖一个像素,那么深度复杂度为2。如果先绘制较远的三角形,则较近的三角形会透支,透支量为1。如果先绘制越近的三角形,则越远的三角形无法通过深度测试,因此不会绘制,因此不会过度绘制。对于覆盖像素的不透明三角形的随机集合,平均绘制次数为调和级数[296]:

The logic behind this is that the first triangle rendered is one draw. The second triangle is either in front or behind the first, a 50/50 chance. The third triangle can have one of three positions compared to the first two, giving one chance in three of it being frontmost. As n goes to infinity,
这背后的逻辑是,渲染的第一个三角形是一个平局。第二个三角形在第一个三角形的前面或后面,有50/50的机会。与前两个三角形相比,第三个三角形可以有三个位置中的一个,这三个三角形中有一个是最前面的。当n趋于无穷大时,

where γ = 0.57721 . . . is the Euler-Mascheroni constant. Overdraw rises rapidly when depth complexity is low, but quickly tapers off. For example, a depth complexity of 4 gives an average of 2.08 draws, 11 gives 3.02 draws, but it takes a depth complexity of 12,367 to reach an average of 10.00 draws.
其中γ=0.57721…是欧拉-马斯切罗尼常数。当深度复杂度较低时,过度绘制会迅速增加,但会迅速减少。例如,深度复杂度为4时,平均绘制2.08张,11时绘制3.02张,但深度复杂度需要12367才能达到平均绘制10.00张。
So, overdraw is not necessarily as bad as it seems, but we would still like to minimize it, without costing too much CPU time. Roughly sorting and then drawing the opaque objects in a scene in an approximate front-to-back order (near to far) is a common way to reduce overdraw [240, 443, 488, 511]. Occluded objects that are drawn later will not write to the color or z-buffers (i.e., overdraw is reduced). Also, the pixel fragment can be rejected by occlusion culling hardware before even reaching the pixel shader program (Section 23.5). Sorting can be accomplished by any number of methods. An explicit sort based on the distance along the view direction of the centroids of all opaque objects is one simple technique. If a bounding volume hierarchy or other spatial structure is already in use for frustum culling, we can choose the closer child to be traversed first, on down the hierarchy.
因此,透支不一定像看起来那么糟糕,但我们仍然希望在不花费太多CPU时间的情况下将其最小化。对场景中的不透明对象进行粗略排序,然后以近似的前后顺序(从近到远)绘制,是减少透支的常用方法[240、443、488、511]。稍后绘制的被遮挡对象将不会写入颜色或z缓冲区(即,减少过度绘制)。此外,像素片段可以在到达像素着色器程序之前被遮挡剔除硬件拒绝(第23.5节)。排序可以通过任意数量的方法完成。基于所有不透明对象的质心沿视图方向的距离进行显式排序是一种简单的技术。如果边界体层次或其他空间结构已经用于截头体剔除,我们可以选择要首先遍历的较近的子对象,沿着层次向下。
Another technique can be useful for surfaces with complex pixel shader programs.Performing a z-prepass renders the geometry to just the z-buffer first, then the whole scene is rendered normally [643]. This eliminates all overdraw shader evaluations,but at the cost of an entire separate run through all the geometry. Pettineo [1405] writes that the primary reason his team used a depth prepass in their video game was to avoid overdraw. However, drawing in a rough front-to-back order may provide much of the same benefit without the need for this extra work. A hybrid approach is to identify and first draw just a few large, simple occluders likely to give the most benefit [1768]. As McGuire [1177] notes, a full-draw prepass did not help performance for his particular system. Measuring is the only way to know which technique, if any,is most effective for your application.
另一种技术可以用于具有复杂像素着色器程序的曲面。执行z预处理首先将几何体渲染到z缓冲区,然后正常渲染整个场景[643]。这消除了所有的过度绘制着色器评估,但代价是整个单独运行所有几何体。佩蒂诺[1405]写道,他的团队在视频游戏中使用深度预处理的主要原因是避免透支。然而,在不需要额外工作的情况下,以粗略的前后顺序绘制可以提供相同的好处。一种混合方法是识别并首先绘制几个可能带来最大益处的大型简单封堵器[1768]。正如麦奎尔[1177]所指出的那样,一场全面的平局预赛并不能帮助他的特定系统发挥作用。测量是了解哪种技术(如果有的话)对您的应用最有效的唯一方法。
Earlier we recommended grouping by shader and texture to minimize state changes;here we talk about rendering objects sorted by distance. These two goals usually give different object draw orders and so conflict with each other. There is always some ideal draw order for a given scene and viewpoint, but this is difficult to find in advance. Hybrid schemes are possible, e.g., sorting nearby objects by depth and sorting everything else by material [1433]. A common, flexible solution [438, 488, 511,1434, 1882] is to create a sorting key for each object that encapsulates all the relevant criteria by assigning each a set of bits. See Figure 18.6.
早些时候,我们建议按着色器和纹理进行分组,以最小化状态变化;这里我们讨论按距离排序的渲染对象。这两个目标通常给出不同的对象绘制顺序,因此相互冲突。对于给定的场景和视点,总是有一些理想的绘制顺序,但这很难提前找到。混合方案是可能的,例如,按深度对附近对象进行排序,并按材质对其他对象进行排序[1433]。一个常见的灵活解决方案[43848851114341882]是为每个对象创建一个排序键,通过为每个对象分配一组位来封装所有相关标准。见图18.6。

Figure 18.6. Example sort key for draw order. Keys are sorted from low to high. Setting the transparency bit means that the object is transparent, as transparent objects are to be rendered after all opaque objects. The object’s distance from the camera is stored as an integer with low precision.For transparent objects the distance is reversed or negated, since we want objects in a back-to-front order. Shaders are each given a unique identification number, as are textures.
图18.6.绘制顺序的排序键示例。键从低到高排序。设置透明度位意味着对象是透明的,因为透明对象将在所有不透明对象之后渲染。对象与相机的距离存储为低精度整数。对于透明对象,距离是相反的或相反的,因为我们希望对象是前后顺序的。每个着色器都有一个唯一的标识号,纹理也是如此。
We can choose to favor sorting by distance, but by limiting the number of bits storing the depth, we can allow grouping by shader to become relevant for objects in a given range of distances. It is not uncommon to sort draws into even as few as two or three depth partitions. If some objects have the same depth and use the same shader, then the texture identifier is used to sort the objects, which then groups objects with the same texture together.
我们可以选择支持按距离排序,但通过限制存储深度的位数,我们可以允许按着色器进行分组,使其与给定距离范围内的对象相关。将绘图分类到两三个深度分区中并不少见。如果某些对象具有相同的深度并使用相同的着色器,则使用纹理标识符对对象进行排序,然后将具有相同纹理的对象分组在一起。
This is a simple example and is situational, e.g., the rendering engine may itself keep opaque and transparent objects separate so that the transparency bit is not necessary. The number of bits for the other fields certainly varies with the maximum number of shaders and textures expected. Other fields may be added or substituted in,such as one for blend state and another for z-buffer read and write. Most important of all is the architecture. For example, some tile-based GPU renderers on mobile devices do not gain anything from sorting front to back, so state sorting is the only important element to optimize [1609]. The main idea here is that putting all attributes into a single integer key lets you perform an efficient sort, thus minimizing overdraw and state changes as possible.
这是一个简单的示例,并且是情境性的,例如,渲染引擎本身可以将不透明对象和透明对象分开,从而不需要透明位。其他字段的位数当然会随着预期的着色器和纹理的最大数量而变化。可以在中添加或替换其他字段,例如一个用于混合状态,另一个用于z缓冲区读取和写入。最重要的是架构。例如,移动设备上的一些基于瓦片的GPU渲染器无法从前后排序中获得任何好处,因此状态排序是优化的唯一重要因素[1609]。这里的主要思想是,将所有属性放在一个整数键中,可以执行有效的排序,从而尽可能减少透支和状态更改。
18.4.6 Framebuffer Techniques帧缓冲技术
Rendering a scene often incurs a vast amount of accesses to the framebuffer and many pixel shader executions. To reduce the pressure on the cache hierarchy, a common piece of advice is to reduce the storage size of each pixel of the framebuffer. While a 16-bit floating point value per color channel provides more accuracy, an 8-bit value is half the size, which means faster accesses assuming that the accuracy is sufficient. The chrominance is often subsampled in many image and video compression schemes, such as JPEG and MPEG. This can often be done with negligible visual effect due to fact that the human visual system is more sensitive to luminance than to chrominance.For example, the Frostbite game engine [1877] uses this idea of chroma subsampling to reduce bandwidth costs for post-processing their 16-bits-per-channel images.
渲染场景通常会导致对帧缓冲区的大量访问和许多像素着色器的执行。为了减轻缓存层次结构的压力,一个常见的建议是减少帧缓冲区中每个像素的存储大小。虽然每个颜色通道的16位浮点值提供了更高的精度,但8位值是其大小的一半,这意味着在精度足够的情况下访问速度更快。在许多图像和视频压缩方案(如JPEG和MPEG)中,色度通常是二次采样的。由于人类视觉系统对亮度比色度更敏感,这通常可以在视觉效果可以忽略不计的情况下完成。例如,Frostbite游戏引擎[1877]使用这种色度二次采样的思想来降低后处理每通道16位图像的带宽成本。
Mavridis and Papaioannou [1144] propose that the lossy YCoCg transform, described on page 197, is used to achieve a similar effect for the color buffer during rasterization. Their pixel layout is shown in Figure 18.7. Compared to RGBA, this halves the color buffer storage requirements (assuming A is not needed) and often increases performance, depending on architecture. Since each pixel has only one of the chrominance components, a reconstruction filter is needed to infer a full YCoCg per pixel before converting back to RGB before display. For a pixel missing the Co-value,for example, the average of the four closest Co-values can be used. However, this does not reconstruct edges as well as desired. Therefore, a simple edge-aware filter is used instead, which is implemented as
Mavridis和Papaioannou[1144]提出,第197页描述的有损YCoCg变换用于在光栅化期间实现颜色缓冲器的类似效果。它们的像素布局如图18.7所示。与RGBA相比,这减少了颜色缓冲存储需求(假设不需要A),并且通常会提高性能,具体取决于架构。由于每个像素只有一个色度分量,所以在显示之前,需要重构滤波器来推断每个像素的完整YCoCg,然后再转换回RGB。例如,对于缺少Co值的像素,可以使用四个最接近的Co值中的平均值。然而,这并不能像期望的那样重建边缘。因此,使用了一个简单的边缘感知滤波器,它被实现为

Figure 18.7. Left: 4 × 2 pixels, each storing four color components (RGBA). Right: an alternative representation where each pixel stores the luminance, Y , and either the first (Co) or the second (Cg) chrominance component, in a checkerboard pattern.
图18.7.左侧:4×2像素,每个像素存储四个颜色分量(RGBA)。右:另一种表示,其中每个像素以棋盘图案存储亮度、Y和第一(Co)或第二(Cg)色度分量。
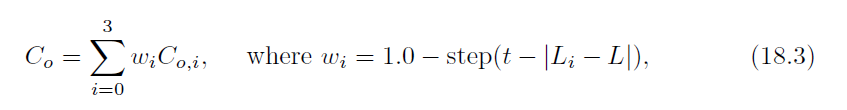
for a pixel that does not have Co, where Co,i and Li are the values to the left, right,top, and bottom of the current pixel, L is the luminance of the current pixel, and t is a threshold value for edge detection. Mavridis and Papaioannou used t = 30/255.The step(x) function is 0 if x < 0, and 1 otherwise. Hence, the filter weights wi are either 0 or 1, where they are zero if the luminance gradient, |Li−L|, is greater than t.A WebGL demo with source code is available online [1144].
对于不具有Co的像素,其中Co、i和Li是当前像素的左、右、上和下的值,L是当前像素亮度,t是边缘检测的阈值。Mavridis和Papaioannou使用t=30/255。如果x<0,则步骤(x)函数为0,否则为1。因此,滤波器权重wi为0或1,如果亮度梯度|Li−L|大于t。带有源代码的WebGL演示可在线获取[1144]。
Because of the continuing increase in display resolutions and the shader execution cost savings, using a checkerboard pattern for rendering has been used in several systems [231, 415, 836, 1885]. For virtual reality applications, Vlachos [1824] uses a checkerboard pattern for pixels around the periphery of the view, and Answer [59] reduces each 2 × 2 quad by one to three samples.
由于显示分辨率的不断提高和着色器执行成本的节省,使用棋盘图案进行渲染已在多个系统中使用[2314158361885]。对于虚拟现实应用程序,Vlachos[1824]使用棋盘格图案来表示视图周围的像素,Answer[59]将每个2×2的四分之一减少到三个样本。
18.4.7 Merging Stage合并阶段
Make sure to enable blend modes only when useful. In theory “over” compositing could be set for every triangle, opaque or transparent, since opaque surfaces using “over” will fully overwrite the value in the pixel. However, this is more costly than a simple “replace” raster operation, so tracking objects with cutout texturing and materials with transparency is worthwhile. Alternately, there are some raster operations that cost nothing extra. For example, when the z-buffer is being used, on some systems it costs no additional time to also access the stencil buffer. This is because the 8-bit stencil buffer value is stored in the same word as the 24-bit z-depth value [890].
确保仅在有用时启用混合模式。理论上,可以为每个三角形(不透明或透明)设置“覆盖”合成,因为使用“覆盖”的不透明曲面将完全覆盖像素中的值。然而,这比简单的“替换”光栅操作成本更高,因此使用剪切纹理和透明材质跟踪对象是值得的。或者,有些光栅操作不需要额外费用。例如,当使用z缓冲区时,在某些系统上,也不需要额外的时间来访问模具缓冲区。这是因为8位模板缓冲值存储在与24位z深度值相同的字中[890]。
Thinking through when various buffers need to be used or cleared is worthwhile. Since GPUs have fast clear mechanisms (Section 23.5), the recommendation is to always clear both color and depth buffers since that increases the efficiency of memory transfers for these buffers.
仔细考虑何时需要使用或清除各种缓冲区是值得的。由于GPU具有快速清除机制(第23.5节),建议始终清除颜色和深度缓冲区,因为这样可以提高这些缓冲区的内存传输效率。
You should normally avoid reading back render targets from the GPU to the CPU if you can help it. Any framebuffer access by the CPU causes the entire GPU pipeline to be flushed before the rendering is returned, losing all parallelism there [1167, 1609].
如果可以帮助,通常应避免将渲染目标从GPU读回CPU。CPU对帧缓冲区的任何访问都会导致整个GPU管道在渲染返回之前被刷新,从而失去所有并行性[11671609]。
If you do find that the merging stage is your bottleneck, you may need to rethink your approach. Can you use lower-precision output targets, perhaps through compression?Is there any way to reorder your algorithm to mitigate the stress on this stage?For shadows, are there ways to cache and reuse parts where nothing has moved?
如果你确实发现合并阶段是你的瓶颈,你可能需要重新思考你的方法。您是否可以使用较低精度的输出目标,或者通过压缩?有没有办法重新排序你的算法以减轻这个阶段的压力?对于阴影,是否有方法缓存和重用没有移动的部分?
In this section we have discussed ways of using each stage well by searching for bottlenecks and tuning performance. That said, be aware of the dangers of repeatedly optimizing an algorithm when you may be better served by using an entirely different technique.
在本节中,我们讨论了通过搜索瓶颈和调整性能来很好地使用每个阶段的方法。也就是说,当使用完全不同的技术可能会更好地为您服务时,请注意重复优化算法的危险。