一、基础数据类型的补充
1)如果元组里面只有一个元素且没有逗号 “,” 则该数据的数据类型与里面的元素相同。
tu1 = ([1, 2, 3]) #列表 tu2 = ([1, 2, 3],) tu3 = ([1, 2, 3],[4, 5]) print(tu1,type(tu1)) print(tu2,type(tu2)) print(tu3,type(tu3)) [1, 2, 3] <class 'list'> #列表 ([1, 2, 3],) <class 'tuple'> ([1, 2, 3], [4, 5]) <class 'tuple'>
2)循环一个列表(字典)时,最好不要改变列表(字典)的大小(增删),否则会影响你的最终结果或者报错。
例题: li = [111, 222,333, 444, 555, 6, 7, 8, 9] 删除索引为奇数位


1 li = [111, 222,333, 444, 555, 6, 7, 8, 9] 2 for i in range(0,len(li)-1): 3 print('删除之前的索引:',i) 4 print('删除之前的列表:',li) 5 if i % 2 == 1: 6 del li[i] 7 print('删除之后的索引:',i) 8 print('删除之后的列表:',li) 9 10 删除之前的索引: 0 11 删除之前的列表: [111, 222, 333, 444, 555, 6, 7, 8, 9] 12 删除之后的索引: 0 13 删除之后的列表: [111, 222, 333, 444, 555, 6, 7, 8, 9] 14 删除之前的索引: 1 15 删除之前的列表: [111, 222, 333, 444, 555, 6, 7, 8, 9] 16 删除之后的索引: 1 17 删除之后的列表: [111, 333, 444, 555, 6, 7, 8, 9] 18 删除之前的索引: 2 19 删除之前的列表: [111, 333, 444, 555, 6, 7, 8, 9] 20 删除之后的索引: 2 21 删除之后的列表: [111, 333, 444, 555, 6, 7, 8, 9] 22 23 #前面的都没问题 24 25 删除之前的索引: 3 26 删除之前的列表: [111, 333, 444, 555, 6, 7, 8, 9] 27 删除之后的索引: 3 28 删除之后的列表: [111, 333, 444, 6, 7, 8, 9] 29 30 # 3在原代码中:444 但在这里(删除之前的列表) 3指的是:555 31 #列表会变,但索引还是按之前的索引删就错了 32 33 删除之前的索引: 4 34 删除之前的列表: [111, 333, 444, 6, 7, 8, 9] 35 删除之后的索引: 4 36 删除之后的列表: [111, 333, 444, 6, 7, 8, 9] 37 删除之前的索引: 5 38 删除之前的列表: [111, 333, 444, 6, 7, 8, 9] 39 删除之后的索引: 5 40 删除之后的列表: [111, 333, 444, 6, 7, 9] 41 删除之前的索引: 6 42 删除之前的列表: [111, 333, 444, 6, 7, 9] 43 删除之后的索引: 6 44 删除之后的列表: [111, 333, 444, 6, 7, 9] 45 删除之前的索引: 7 46 删除之前的列表: [111, 333, 444, 6, 7, 9]
正确答案:切片最简单 应该倒着删,否则列表会变但索引依旧是li的元索引
= [111, 222,333, 444, 555, 6, 7, 8, 9] for i in range(len(li)-1,-1,-1): #len(li)计算 li 总长度, len(li)-1 :最后一位索引。 # -1 :第一位之前,过头不顾尾,取不到第一位,所以【0-1=-1】 -1:倒着隔一位取一个 if i % 2 == 1: del li[i] print(li) [111, 333, 555, 7, 9]
dic = {'k1':'v1','k2':'v2','k3':'v3','name':'alex'}删除含“k”的键
dic = {'k1':'v1','k2':'v2','k3':'v3,','name':'alex'}
li = []
for i in dic: # for 循环 dic 键
if "k" in i: #如果 dic 的键里含 “k”
del dic[i]
print(dic)
RuntimeError: dictionary changed size during iteration
运行时错误:字典在迭代过程中改变了大小
正确答案:在遍历的过程中 绝对 不能有任何改变
dic = {'k1':'v1','k2':'v2','k3':'v3,','name':'alex'}
li = []
for i in dic: # for 循环 dic 键
if "k" in i: #如果 dic 的键里含 “k”
li.append(i)
for a in li: # for 循环 dic 的键
del dic[a]
print(dic)
{'name': 'alex'}
3)fromkeys:返回一个新的,带有(可迭代的键)和(值等于值的键)。
常用于创建有规律的字典
# 如何通过一行语句创建一个这样的字典{1: 'alex', 2: 'alex', 3: 'alex'}?
dic = dict.fromkeys([1,2,3],'alex') print(dic) {1: 'alex', 2: 'alex', 3: 'alex'}
### fromkeys 虽然很好用,但是有个坑 【字典的值是容器类型,可变时】
dic = dict.fromkeys([1,2,3],[]) print(dic) {1: [], 2: [], 3: []} dic[1].append(666) # 我给 1 的列表加 666 print(dic) {1: [666], 2: [666], 3: [666]} # 1 2 3 这三个列表在内存中用的是一个
二、集合 (set)
集合是无序的,不重复的数据集合,集合本身是可变的(增删查)【因为是无序的,所以没办法修改】,但是它却要求它里面的元素是不可变的(可哈希)【所以集合是做不了字典的键,但里面的元素可以做字典的键】
集合最重要的两点:
1)去重(chong 重复)把一个列表变成集合,自动去重。
set = set(list)
2)关系测试,测试两组数据之间的交集、差集、并集等
1)集合的创建
set1 = set() # 小括号 创建空集合 print(set1,type(set1)) set2 = {'aass',5,9,True} # 大括号,创建非空集合 print(set2) set() <class 'set'> {9, 'aass', 5, True} <class 'set'>
2)增:.add() 直接加
.update() 迭代着增加 【字典里是两个字典之间的更新】
els = {'taibai','alex','wusir'}
els.add('女神')
print(els)
{'alex', '女神', 'wusir', 'taibai'} #集合特性:无序。所以新加的内容的位置会随机
{'女神', 'alex', 'taibai', 'wusir'}
els = {'taibai','alex','wusir'}
els.update('女神')
print(els)
{'神', 'taibai', 'wusir', 'alex', '女'}
els = {'taibai','alex','wusir',}
els.update(['女神']) #加中括号
print(els)
{'wusir', 'taibai', 'alex', '女神'}
3)删 .pop() 随机删
del 集合 删除集合
.clear() 清空集合
.remove(元素) 删除一个元素 【列表:按元素删除】
set1 = {'taibai','alex','wusir','yue'}
print(set1.pop()) # pop 有返回值 随机删
print(set1)
alex
{'taibai', 'wusir', 'yue'}
set1 = {'taibai','alex','wusir','yue'}
del set1
print(set1)
NameError: name 'set1' is not defined
set1 = {'taibai','alex','wusir','yue'}
print(set1.clear()) # 清空集合 没有返回值
print(set1)
None
set()
set1 = {'taibai','alex','wusir','yue'}
print(set1.remove('taibai')) #按元素删 没有返回值
print(set1)
None
{'wusir', 'yue', 'alex'}
4)查 因为集合是无序的,所以没办法用索引,只能 for 循环
set1 = {'taibai','alex','wusir','yue'}
for i in set1:
print(i)
# 结果是无序的
alex
taibai
wusir
yue
5)集合的其他操作:
1)去重
set1 = {1, 1, 1, 1, 1, 1, 1, 1, 1}
print(set1)
{1}
2)关系测试:
1)交集 (& 或 intersection)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
print(set1 & set2)
print(set1.intersection(set2))
{4, 5}
{4, 5}
2)并集 (| 或 union)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
print(set1 | set2)
print(set1.union(set2))
{1, 2, 3, 4, 5, 6, 7, 8}
{1, 2, 3, 4, 5, 6, 7, 8}
3)差集 (- 或 difference)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
print(set1 - set2) # 对于 set1 来说,它的差值是
print(set2.difference(set1)) # 对于 set2 来说,它的差值是
{1, 2, 3}
{8, 6, 7}
4)反交集 (^ 或 symmetric_difference)
set1 = {1, 2, 3, 4, 5}
set2 = {4, 5, 6, 7, 8}
print(set1 ^ set2)
print(set2.symmetric_difference(set1)
{1, 2, 3, 6, 7, 8}
{1, 2, 3, 6, 7, 8}
5)子集与超集 issubset “<” “>”
set1 = {1, 2, 3}
set2 = {1, 2, 3, 4, 5}
print(set1 > set2)
print(set2.issubset(set1)) # 判断set2 是否是 set1 的子集
print(set1 < set2)
print(set1.issubset(set2)) # 判断set2 是否是 set1 的超集
False
False
True
True
set1 = {1, 2, 3}
set2 = {1, 2, 3}
print(set2.issubset(set1)) # 判断set2 是否是 set1 的子集
print(set1.issubset(set2)) # 判断set1 是否是 set 的子集
print(set1 > set2)
print(set1 < set2)
True
True
False
False
# set1 与 set2 互为子集,互为超集
6)frozenset 不可变集合,让集合变成不可变类型【集合本身是可变的】
set = {'d', 5, 9, 7}
set2 = frozenset(set) # 冻结
set.update('bsd') # 迭代增加 ‘b','s','d'
print(set2.pop()) # 随机删
print(set2)
frozenset({'d', 9, 5, 7})
AttributeError: 'frozenset' object has no attribute 'update'
AttributeError:“frozenset”对象没有属性“更新”
AttributeError: 'frozenset' object has no attribute 'pop'
#AttributeError:'frozenset'对象没有属性'pop'
三、深浅copy
我们先看赋值运算
l1 = [1, 2, 3, ['barry','alex']] l2 = l1 l1[0] = 111 # 将 1 改成 111 。l1 与 l2 都改变了 print(l1) print(l2) l1[3][0] = 'taibai' #将 ‘barry’ 改成 ‘taibai’。l1 与 l2 都改变了 print(l1) print(l2) [111, 2, 3, ['barry', 'alex']] [111, 2, 3, ['barry', 'alex']]
[111, 2, 3, ['taibai', 'alex']] [111, 2, 3, ['taibai', 'alex']]

对于赋值运算来说,l1与l2指向的是同一个内存地址,所以他们是完全一样的
1)浅 copy 拷贝
l1 = [1, 2, 3, ['barry','alex']] l2 = l1.copy() print(l1 , id(l1)) #[1, 2, 3, ['barry', 'alex']] 2079355846088 print(l2, id(l2)) # [1, 2, 3, ['barry', 'alex']] 2079357049160 l1[1] = 0 print(l1,id(l1)) #[1, 0, 3, ['barry', 'alex']] 2079355846088 print(l2,id(l2)) #[1, 2, 3, ['barry', 'alex']] 2079357049160 # 内存地址不同,所以这是两个列表, l1 做出了改变,而 l2 没有改变 l1[3][0] = 'taibai' print(l1,id(l1[3])) #[1, 0, 3, ['taibai', 'alex']] 2079357059272 print(l2,id(l2[3])) #[1, 2, 3, ['taibai', 'alex']] 2079357059272 # 内存地址相同,所以 l1 与 l2 共用一个['barry','alex']
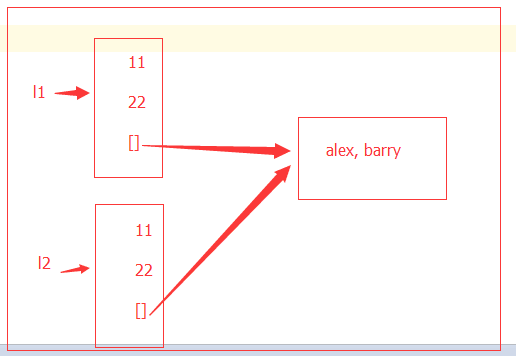
对于浅copy来说,第一层创建的是新的内存地址,而从第二层开始,指向的都是同一个内存地址,所以,对于第二层以及更深的层数来说,保持一致性。
1.1)对于切片来说,这是浅copy
l1 = [1, 2, 3, ['barry','alex']] l2 = l1[::1] print(l2) #[1, 2, 3, ['barry', 'alex']] l1[0] = 56 print(l1,id(l1)) #[56, 2, 3, ['barry', 'alex']] 2255049604552 print(l2,id(l2)) #[1, 2, 3, ['barry', 'alex']] 2255050807624 l1[-1][0] = 'taibai' print(l1,id(l1[-1])) #[56, 2, 3, ['taibai', 'alex']] 2255050817736 print(l2,id(l2[-1])) #[1, 2, 3, ['taibai', 'alex']] 2255050817736
2) 深层拷贝 deepcopy
import copy # 一定不能缺 l1 = [1, 2, 3, ['barry','alex']] l2 = copy.deepcopy(l1) #完全复制 print(l1,id(l1)) #[1, 2, 3, ['barry', 'alex']] 2113649875272 print(l2,id(l2)) #[1, 2, 3, ['barry', 'alex']] 2113650028872 l1[1] = 222 print(l1,id(l1)) #[1, 222, 3, ['barry', 'alex']] 2113649875272 print(l2,id(l2)) #[1, 2, 3, ['barry', 'alex']] 2113650028872 l1[3][0] = 'taibai' print(l1,id(l1)) #[1, 222, 3, ['taibai', 'alex']] 2113649875272 print(l2,id(l2)) #[1, 2, 3, ['barry', 'alex']] 211365002887
对于深copy来说,两个是完全独立,改变任意一个的任意元素(无论多少层),另一个绝对不变