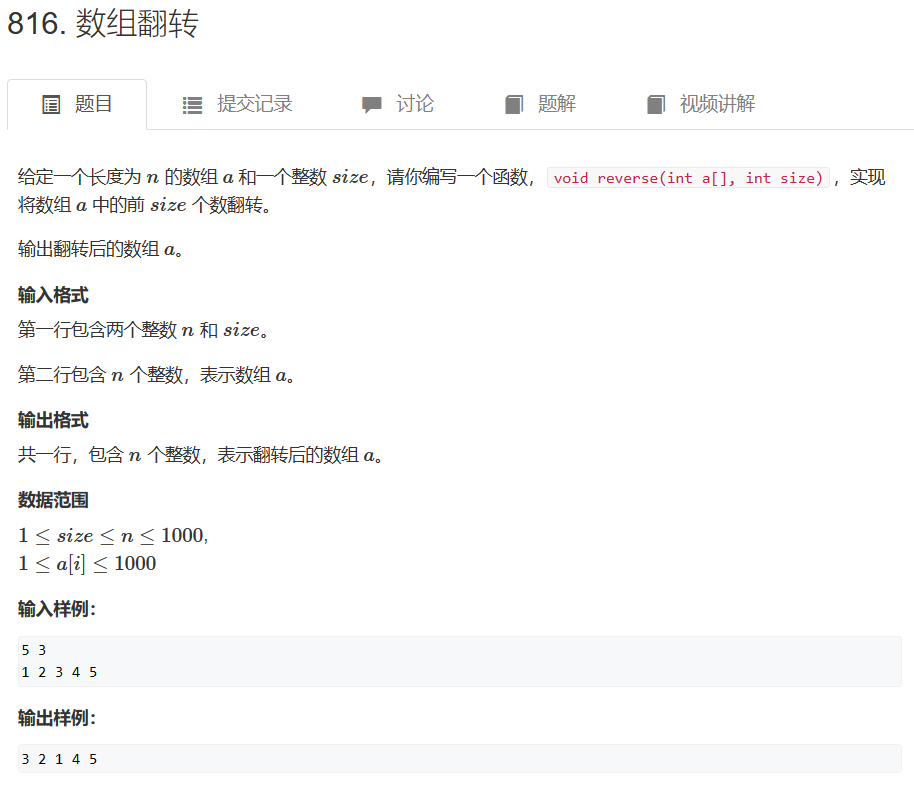
一、数组翻转
写法一:myself
切片太牛了
a[:size]=a[:size][::-1]
先将前size个数取出来,然后进行翻转
需要注意切片操作中左闭右开区间的规则
n,size=map(int,input().split())
a=list(map(int,input().split()))
a[:size]=a[:size][::-1]
for i in range(n):
print(a[i],end=' ')
写法二:函数
n, m = map(int, input().split())
a = list(map(int, input().split()))
def reverse(a, size):
for i in range(size // 2):
a[i], a[size - 1 - i] = a[size - 1 - i], a[i]
reverse(a, m)
for x in a:
print(x, end = " ")
写法三:
n, s = map(int, input().split())
a = input().split()
print(*reversed(a[:s]), *a[s:])
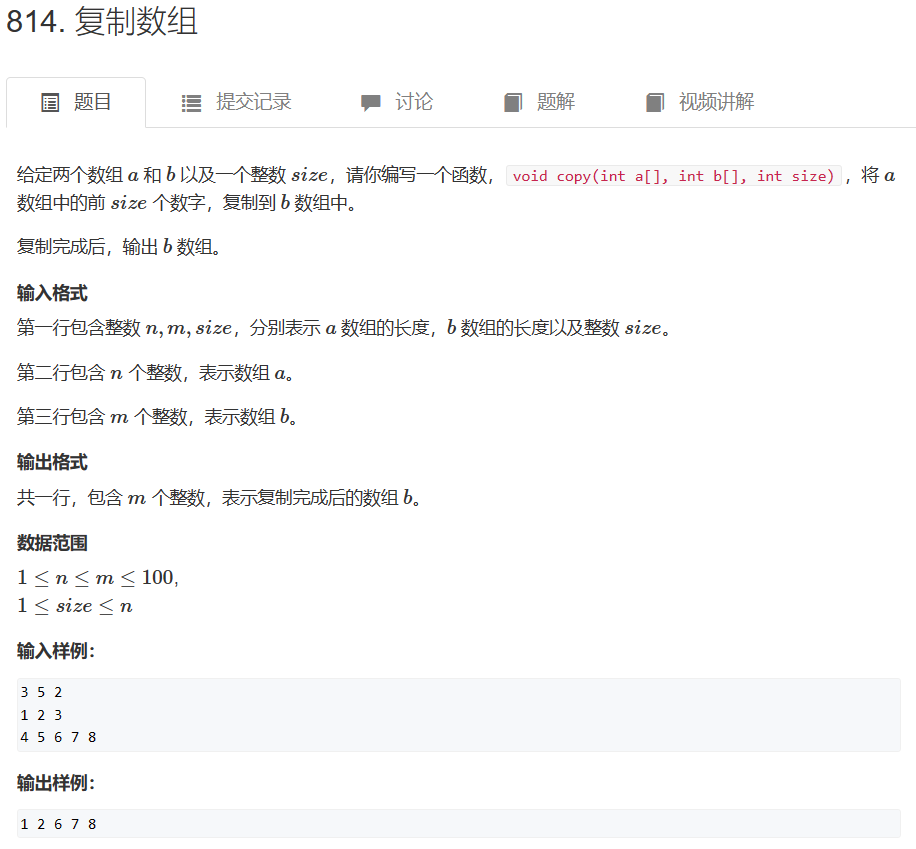
二、复制数组
写法一:
lambda x: int(x) 是一个匿名函数,它将一个字符串参数 x 转换为整数并返回该整数。通常情况下,Python中的 int() 函数将字符串参数转换为整数。lambda 函数提供了一种简便的方式来定义一个函数,通常用于需要将函数作为参数传递给其他函数的情况。
al,bl,size = map(lambda x:int(x),input().split(" "))
a = list(map(lambda x:int(x),input().split(" ")))
b = list(map(lambda x:int(x),input().split(" ")))
def copy(a,b,size):
for i in range(size):
b[i] = a[i]
return b
print(*copy(a,b,size))
写法二:
n,m,s=map(int,input().split())
a=list(input().split())
b=list(input().split())
def copy(a,b,s):
b[:s]=a[:s]
copy(a,b,s)
for i in range(m):
print(b[i],end=' ')
写法三:
n, m, s = map(int, input().split())
a = list(map(int, input().split()))
b = list(map(int, input().split()))
print(*(a[:s] + b[s:]))
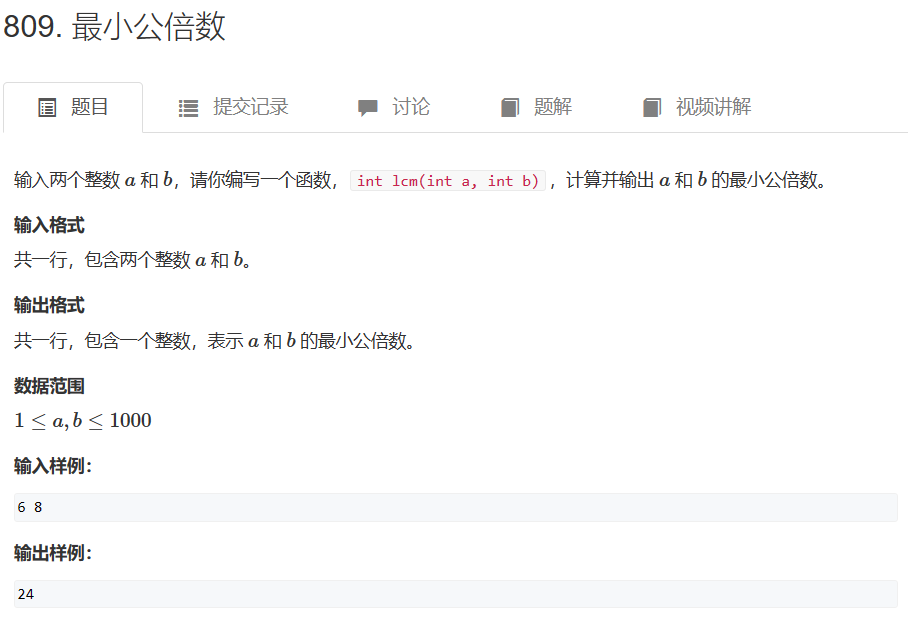
三、最小公倍数
最小公倍数和最大公约数是我一直都没太弄明白的,但是我现在弄明白了一些。
写法一:
lcm(a,b) = a * b / gcd(a,b)
其中,gcd(a,b)是a和b的最大公约数。该公式基于一个简单的事实,即两个数的积等于它们的最大公约数和最小公倍数的积。所以我们只需要求出它们的最大公约数,就可以用它们的积除以最大公约数来得到最小公倍数。
这里的gcd函数实现了求两个整数的最大公约数。它使用了递归的方式来实现,即不断用余数代替较大的数,直到余数为0为止。这是一个经典的欧几里得算法,也称作辗转相除法。
def gcd(a, b):
return a if b == 0 else gcd(b, a % b)
a, b = list(map(int, input().split()))
c = gcd(a, b)
print(a * b // c)
写法二:
这段代码实现了求两个整数的最小公倍数。
函数 lcm 的参数为两个整数 a 和 b,通过从 max(a, b) 开始枚举所有可能的最小公倍数,当遇到第一个同时能被 a 和 b 整除的数时,输出该数并跳出循环。
在主程序中,首先读入两个整数 a 和 b,然后调用函数 lcm,将它们作为参数传入。函数 lcm 的执行结果就是输出这两个整数的最小公倍数。
def lcm(a,b):
for i in range(max(a,b),a * b + 1):
if i % a == 0 and i % b == 0:#用的就是他的定义,遍历啦
print(i)
break
s = list(map(int,input().split(' ')))
a = s[0]
b = s[1]
lcm(a,b)
写法三:
gcd
from math import gcd
from math import gcd
a = list(map(int,input().split()))
print(a[0]*a[1]//gcd(a[0],a[1]))
写法四:
def gcd (m, n):
if n > m:
m, n = n, m
if m % n == 0:
return n
return gcd (n, m % n)
def lcm(m, n):
return m * n // gcd(m, n)
m, n = map(int, input().split())
print(lcm(m, n))
其他:两数相加
没有想到还可以这样子写
x, y = map(float, input().split())
print(f'{
x + y:.2f}')
还可以这样子写
print("%.2f" % sum(list(map(float, input().split()))))
其他:打印数字
a=input().split()
print(*a[:size],end=' ')
四、排序
按字典排序

这段代码实现的是输出1~n的全排列。
首先,读入一个整数n表示排列的长度。
定义一个长度为10的全局变量列表nums,用于存储排列结果;定义一个长度为10的全局变量列表st,表示数字是否已被使用。
然后定义一个深度优先搜索函数dfs,表示枚举当前排列中第u个位置的数字。如果u==n,即枚举完所有的位置,就输出当前排列结果。
在函数内部,遍历1~n的所有数字,如果当前数字未被使用,则将其标记为已使用,存储到nums数组中,然后继续搜索下一个位置,即调用dfs(u+1)。如果到达了排列的末尾,即u==n,就输出当前排列。
最后,在程序的最外层调用dfs(0)即可开始搜索排列结果。
n = int(input())
N = 10
nums = [0] * N
st = [False] * N
def dfs(u):
if u == n:
print(*nums[:n])
return
for i in range(1, n + 1):
if st[i] == False:
st[i] = True
nums[u] = i
dfs(u + 1)
st[i] = False
dfs(0)
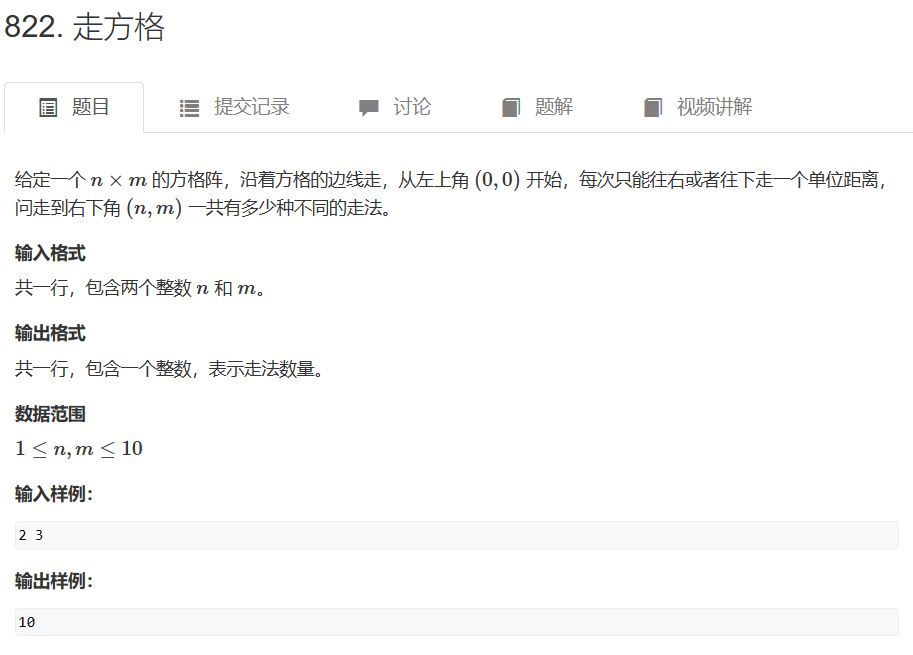
五、走方格
写法一:
n,m=map(int,input().split())
ans=0
def f(a,b):
if a==n and b==m:
return 1
if a>n or b>m:
return 0
return f(a+1,b)+f(a,b+1)
print(f(0,0))
写法二:
global为全局变量哦!
n, m = map(int, input().split())
res = 0
def dfs(a, b):
global res
if a == n and b == m:
res += 1
else:
if a < n:
dfs(a + 1, b)
if b < m:
dfs(a, b + 1)
dfs(0, 0)
print(res)
写法三:
n, m = map(int, input().split())
def f(a, b):
if a < 0 or b < 0:
return 0
if a == 0 and b == 0:
return 1
return f(a - 1, b) + f(a, b - 1)
print(f(n, m))
六、数组去重
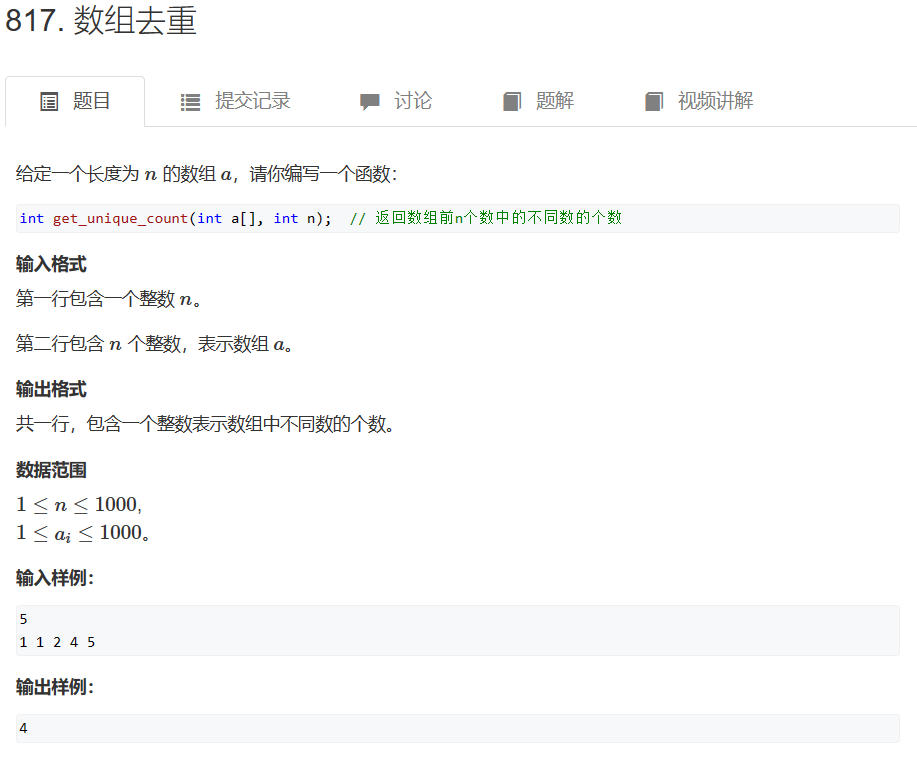
写法一:
具体来说,Counter(a)会返回一个字典,其中每个元素都是列表a中的一个不同元素,对应的值为该元素在列表中出现的次数。因此,len(Counter(a))返回的就是不同元素的个数。另外,需要注意的是,这段代码可能存在效率问题。由于Counter函数需要遍历整个列表,因此对于大规模的列表,可能会存在一定的时间复杂度问题。如果需要对性能进行优化,可以考虑使用其他算法实现。
from collections import Counter
n = int(input())
a = list(map(int, input().split()))
print(len(Counter(a)))
写法二:
def unique(a):
return len(set(a))
m = map(int, input().split())
lst = list(map(int, input().split()))
print(unique(lst))
写法三:
n = int(input())
data = list(map(lambda x:int(x),input().split(" ")))
def get_unique_count(data,n):
res = {
}
c = 0
for d in data:
if res.get(d,False):
continue
else:
res[d] = d
c+=1
return c
print(get_unique_count(data,n))
七、三元组排序
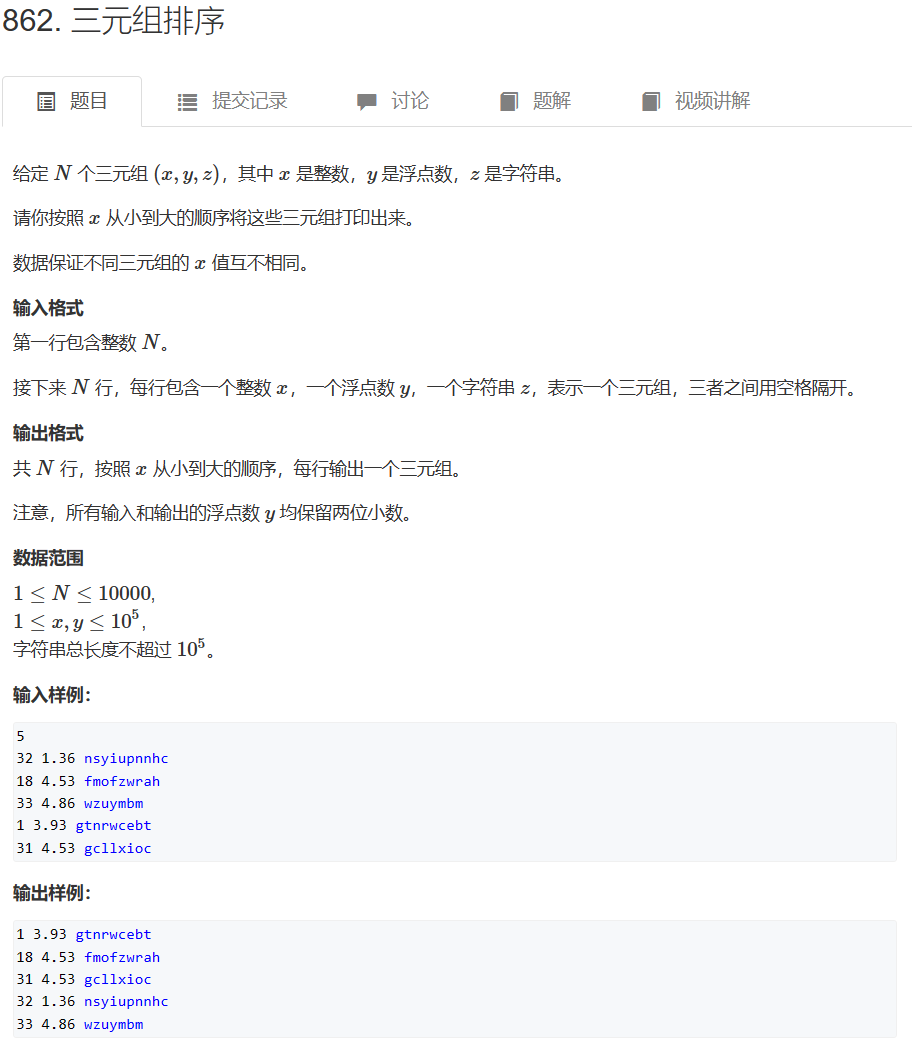
n = int(input())
res = []
for i in range(n):
n = list(input().split())
res.append((int(n[0]), float(n[1]), n[2]))
res.sort(key=lambda x: x[0])
for i in res:
print("{} {:.2f} {}".format(*i))