前段时间,看到一篇叫做《面试官:阮一峰版的快速排序完全是错的》的文章,恰巧此前不久也学习了阮一峰老师的快排,非常通俗易懂易实现,不得不说,标题一下抓住了我的眼球。
文章内容就是某面试官(简写成A,下同)微博公开说阮一峰老师(简写成R,下同)快排是完全错误的,重点是,所有面试者的快排都是R的,Google 前端快排 也都是R的,一个A认为完全错误的算法还一统前端的天下了,也许A在发博的时候带了情绪,亦或是有别的原因,措辞犀利,引起了前端界一波争议。而以上,都不是我关注的重点,我把重点投到了算法上:
思路:
1、选择数组中间数作为基数,并从数组中取出此基数;
2、准备两个数组容器,遍历数组,逐个与基数比对,较小的放左边容器,较大的放右边容器;
3、递归处理两个容器的元素,并将处理后的数据与基数按大小合并成一个数组,返回。
实现:
var quickSort = function(arr) {
if (arr.length <= 1) { return arr; }
var pivotIndex = Math.floor(arr.length / 2);
var pivot = arr.splice(pivotIndex, 1)[0];
var left = [];
var right = [];
for (var i = 0; i < arr.length; i++){
if (arr[i] < pivot) {
left.push(arr[i]);
} else {
right.push(arr[i]);
}
}
return quickSort(left).concat([pivot], quickSort(right));
};
总结:
R的思路非常清晰,选择基数为参照,划分数组,分而治之,对于新手来理解快排的核心思想“参照-划分-递归”,很容易理解 。
既实现了排序,又符合快速排序的思想,为什么还会为人所诟病呢?原来是因为:
1、R取基数用的是splice()函数取,而不是算法中常用的取下标。基数只是一个参照对象,在比对的时候,只要能从数组中取到即可,所以只需要知道它的索引即可,调用函数删除基数只会更耗时;
2、根据基数来划分时,R专门生成两个数组来存储,从而占用了更多的存储空间(增加了空间复杂度)。
严格上讲,R的代码仅仅是用快速排序的思想实现了排序,也算是快速排序,但是还有很多改进之处。
二、文章中提出的快排js实现
思路:
1、通过下标取中间数为基数;
2、从起点往后寻找比基数大的,记录为下标 i;再从终点往前寻找比基数小的,记录为下标 j,当 i <= j时,原地交换数值;
3、重复步骤2,直到遍历所有元素,并记录遍历的最后一个下标 i,以此下标为分界线,分为左右两边,分别重复步骤1~3实现递归排序;
实现(为方便理解,在原文基础上有所合并):
// 快排改进——黄佳新 var devide_Xin = function (array, start, end) { if(start >= end) return array; var baseIndex = Math.floor((start + end) / 2), // 基数索引 i = start, j = end; while (i <= j) { while (array[i] < array[baseIndex]) { i++; } while (array[j] > array[baseIndex]) { j--; } if(i <= j) { var temp = array[i]; array[i] = array[j]; array[j] = temp; i++; j--; } } return i; } var quickSort_Xin = function (array, start, end) { if(array.length < 1) { return array; } var index = devide_Xin(array, start, end); if(start < index -1) { quickSort_Xin(array, start, index - 1); } if(end > index) { quickSort_Xin(array, index, end); } return array; }
总结:
1、用下标取基数,只有一个赋值操作,跟快;
2、原地交换,不需要新建多余的数组容器存储被划分的数据,节省存储;
比较:
相较而言,理论分析,实现二确实是更快速更省空间,那么事实呢?
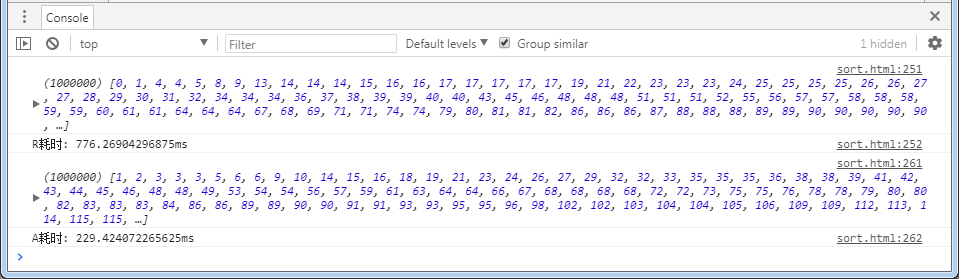
以上是实现一与实现二在chrome上测试耗时的统计结果,测试方案为:各自随机生成100万个数(乱序),分别完成排序,统计耗时。
结论:
事实上,乱序排序,实现二更快。
三、网上其他的快排js实现
思路:
1、通过下表取排序区间的第0个数为基数
2、排序区间基数以后,从右往左,寻找比基数小的,从左往右,寻找比基数大的,原地交换;
3、重复步骤2直到 i >= j;
4、将基数与下标为 i 的元素原地交换,从而实现划分;
5、递归排序基数左边的数,递归排序基数右边的数,返回数组。
实现:
var quickSort_New = function(ary, left, right) { if(left >= right) { return ary; } var i = left, j = right; base = ary[left]; while (i < j) { // 从右边起,寻找比基数小的数 while (i<j && ary[j] >= base) { j--; } // 从左边起,寻找比基数大的数 while (i<j && ary[i] <= base) { i++ } if (i<j) { var temp = ary[i]; ary[i] = ary[j]; ary[j] = temp; } } ary[left] = ary[i]; ary[i] = base; quickSort_New(ary, left, i-1); quickSort_New(ary, i+1, right); return ary; }
总结:
除选基数不同以外,其他与实现二类似。
另外:
比较一下实现二与实现三的速度,结果如下:
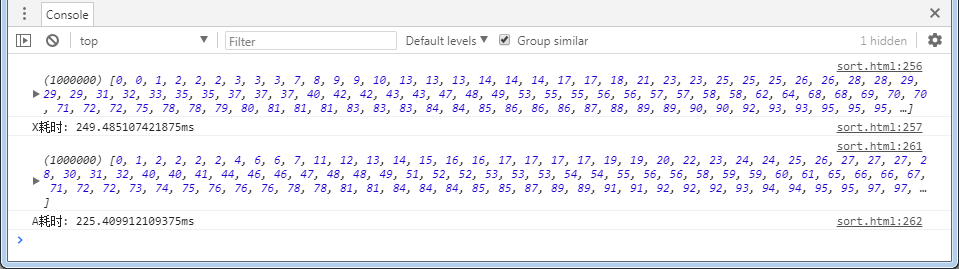
多次测试结果均为:实现二耗时略小于实现三,偶尔出现大于的情况,但相差不大。
算法是计算机基础,无论前后端,都应该重视,前端入门门槛低,确实很多前端算法功底差,但前端也有挺多东西要学,并不是A所说的“天花板低”。还是埋起头来学习吧!
完~