文章目录
Llama 2 模型介绍
2023年7月18日,Meta 发布了Llama 2,包含7B,13B,70B三种参数(34B暂时还未发布)。
官方: https://ai.meta.com/llama/
论文:Llama 2: Open Foundation and Fine-Tuned Chat Models
模型:https://huggingface.co/meta-llama
github:https://github.com/facebookresearch/llama
Llama 2相比Llama最大亮点之一是允许商业化,但需要注意的是如果使用Llama 2的企业月活人数超过7亿,将需要向Meta申请特定的商业许可。
Llama 2的核心点
Llama 2 训练语料相比LLaMA多出40%,接受了 2 万亿个标记的训练;
Llama 2 上下文长度是由之前的2048升级到4096,可以理解和生成更长的文本;
Llama 2 的34B、70B模型采用分组查询注意力(GQA),代替了MQA和MHA,主要是考虑效果和易扩展性的权衡(GQA可以提高大模型的推理扩展性)。
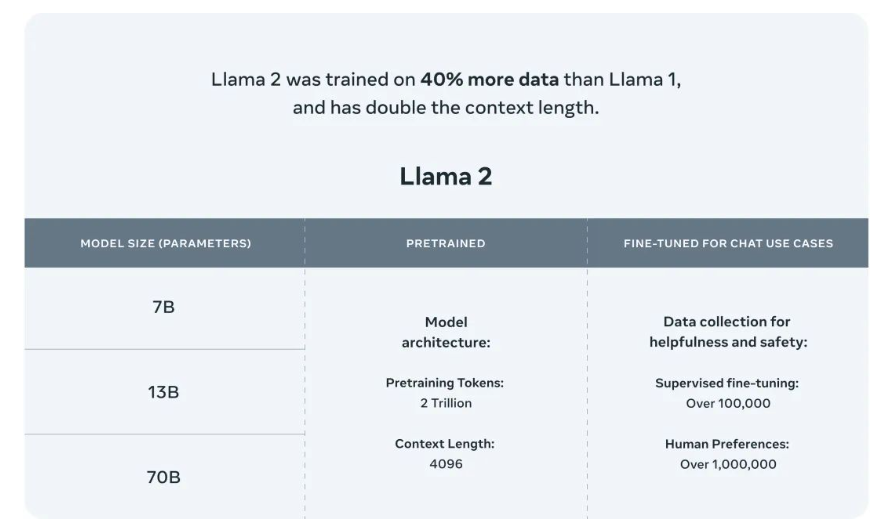
Llama 2的测评结果
公布的测评结果显示,Llama 2 在包括推理、编码、精通性和知识测试等许多外部基准测试中都优于其他开源语言模型。
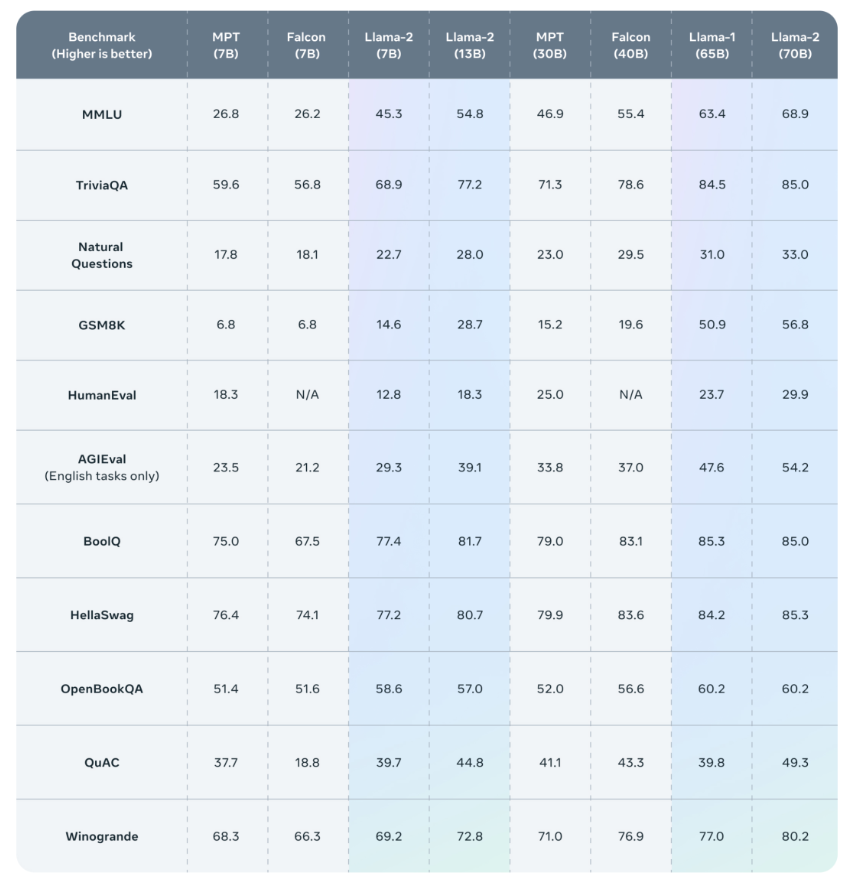
Llama 2的预训练
Llama 2以 Llama 1 的预训练方法为基础,使用了优化的自回归 transformer,并做了一些改变以提升性能。
预处理数据
Llama 2 的训练语料库包含了来自公开可用资源的混合数据,并且不包括 Meta 产品或服务相关的数据。同时从一些包含大量个人信息的网站上删除了相关数据。
预训练设置和模型架构
Llama 2 采用了 Llama 1 中的大部分预训练设置和模型架构,包括标准 Transformer 架构、使用 RMSNorm 的预归一化、SwiGLU 激活函数和旋转位置嵌入。
与Llama 1的主要区别包括增加的上下文长度(由2048变为4096)和分组查询注意力(GQA)。
在超参数方面,Llama 2 使用 AdamW 优化器进行训练,其中 β_1 = 0.9,β_2 = 0.95,eps = 10^−5。同时使用余弦学习率计划(预热 2000 步),并将最终学习率衰减到了峰值学习率的 10%。使用了用了0.1的权重衰减和1.0的梯度剪切。训练损失如下:
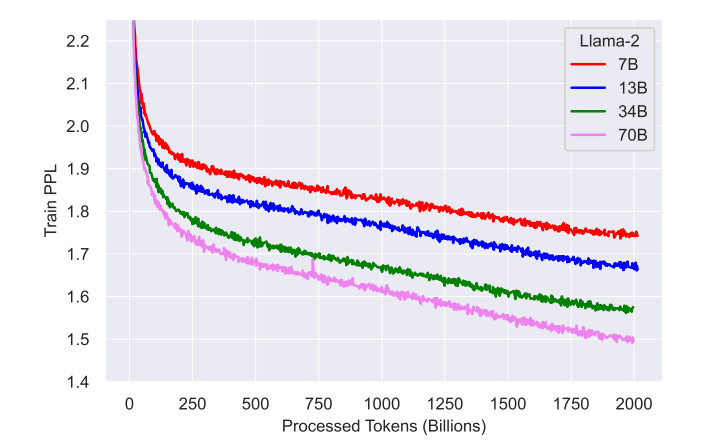
可以看出,对2T的tokens进行预训练后,模型仍然没有出现饱和现象。
分词 采用和Llama 1 相同的分词器,即字节对编码(BPE),使用了SentencePiece中的实现,将所有数字分割成单个数字,并使用字节来分解未知的UTF-8字符,总词汇大小是32K tokens。
关于GQA
论文:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
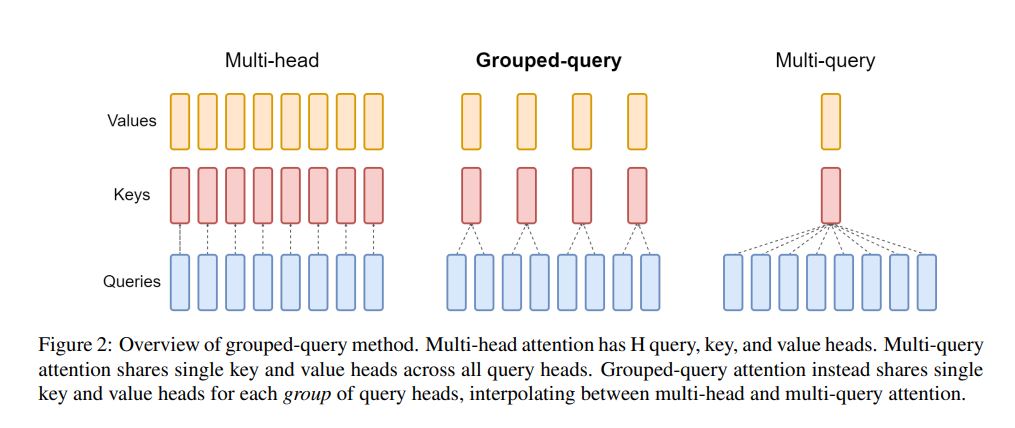
GQA是2023年5月谷歌提出来的一种注意力方法。了解GQA前,要先知道 MHA 和 MQA。
MHA就是Transformer中的多头注意力,如果头数是8的话,就会有8个Q,8个K,8个V(Q是查询向量,K是键向量,V是值向量);
MQA是多查询注意力,是对MHA的一种改进,将K和V都只保留一个,相当于是用8个Q,1个K,1个V进行注意力的计算,这种方式的优点是可以加速解码器的推理速度(因为K和V的计算量少了),缺点就是性能下降;
GQA的提出,则是将K和V的数量设置为大于1,小于Q的一个值(如设置为4,介于1到8之间),这种方式以较小的计算成本将多头注意力模型转换为多查询模型,从而实现快速的多查询和高质量的推理,实现了性能和速度的平衡。
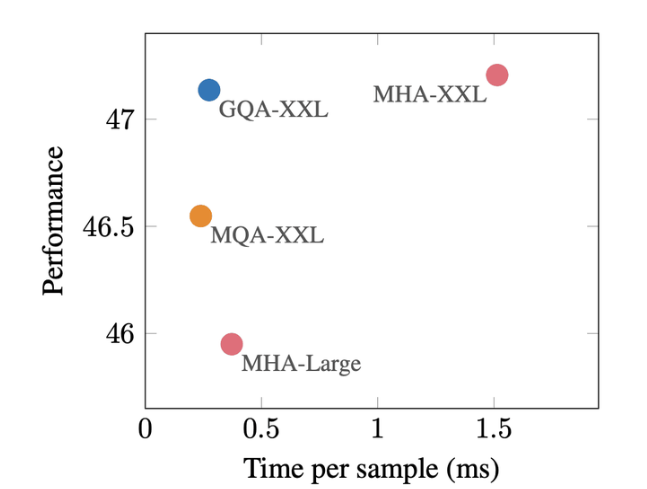
GQA在推理速度上几乎和MQA持平,在效果上几乎和MHA持平。
Llama-2-chat 模型介绍
Llama-2-chat 模型在帮助性和安全性上的表现
Llama-2-chat 模型 接受了超过 100 万个新的人类注释的训练,使用来自人类反馈的强化学习(RLHF)来确保安全性和帮助性。
Llama-2-chat 模型在帮助性和安全性(helpfulness and safety)的表现优于现有的开源模型,甚至和一些闭源模型的效果相当(评估方式为人工评估)
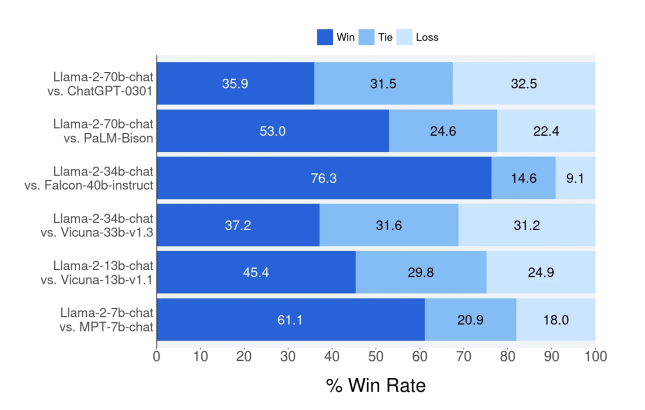
- 下图为Llama 2-70b-chat 和其他的开源和闭源模型在大约4000个帮助性提示的效果对比,其中Win表示赢,Tie表示持平局,Loss表示失败。
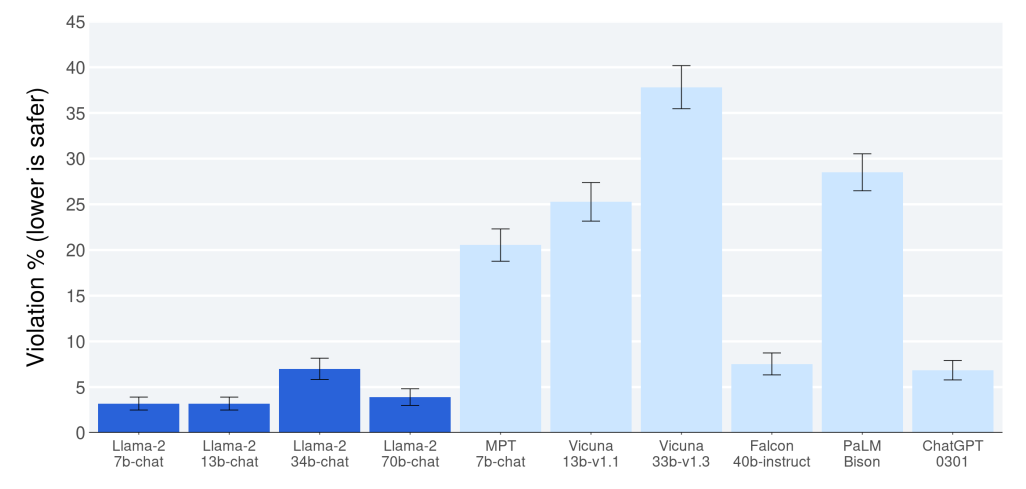
下图为 Llama 2-70b-chat 和其他的开源和闭源模型在大约2000个对抗性提示中判断模型的安全违规情况的效果对比。纵轴表示的是违规率,数值越小,表示越安全。
Llama-2-chat 模型的训练过程
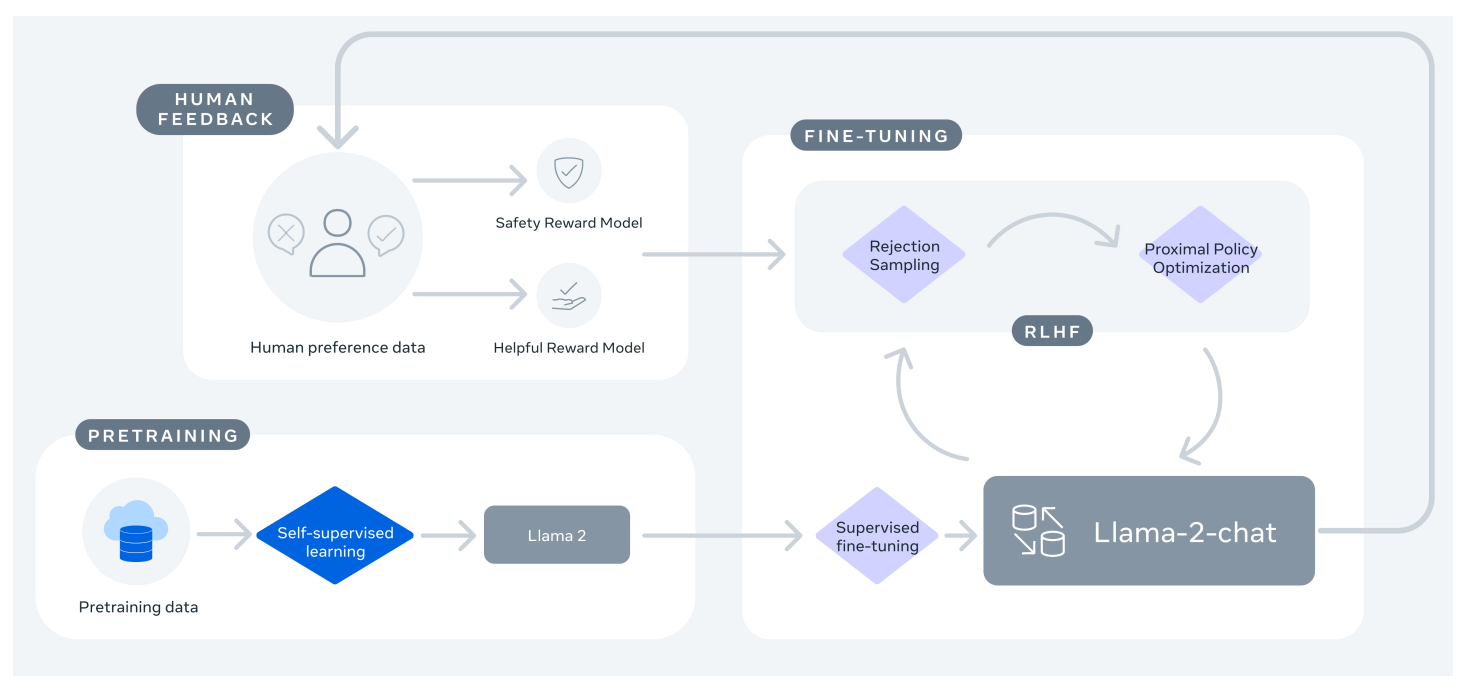
Llama 2-Chat 的训练:首先使用公开的在线资源对Llama 2进行预训练,然后通过监督微调的方式创建一个初始版本的Llama 2-Chat,最后使用具有人类反馈的强化学习(RLHF)方法,特别是通过拒绝采样和近似策略优化(PPO),对模型进行迭代优化。在整个RLHF阶段,迭代奖励建模数据的积累与模型增强并行对于确保奖励模型保持在分布范围内至关重要。
从上图可以看出来,针对安全性和帮助性,都设置了奖励模型,也就是Safety Reward Model 和 Helpful Reward Model。