此次 Meta 发布的 Llama 2 模型系列包含 70 亿、130 亿和 700 亿三种参数变体。此外还训练了 340 亿参数变体,但并没有发布,只在技术报告中提到了。
据介绍,相比于 Llama 1,Llama 2 的训练数据多了 40%,上下文长度也翻倍,并采用了分组查询注意力机制。具体来说,Llama 2 预训练模型是在 2 万亿的 token 上训练的,精调 Chat 模型是在 100 万人类标记数据上训练的。
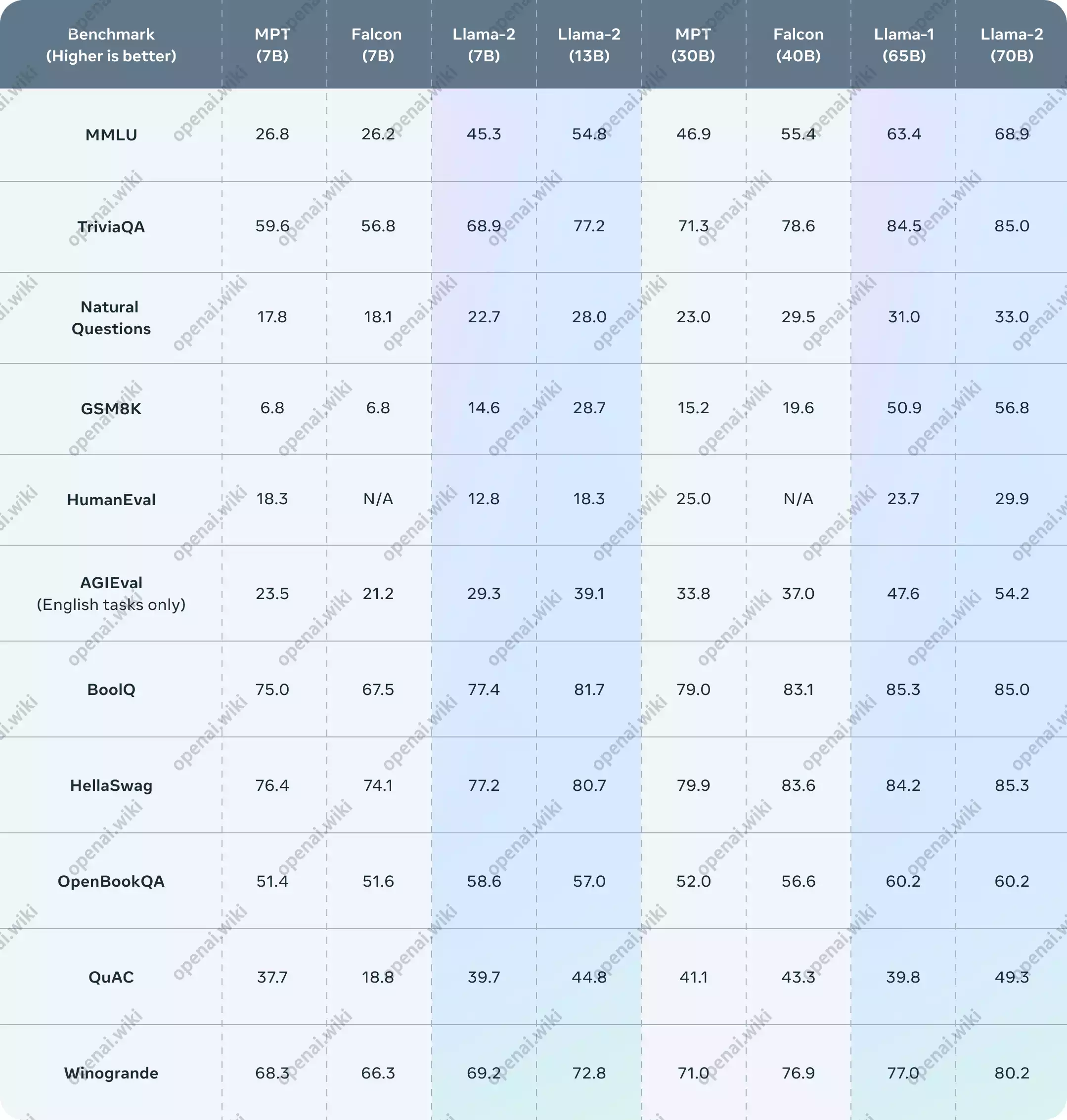
公布的测评结果显示,Llama 2 在包括推理、编码、精通性和知识测试等许多外部基准测试中都优于其他开源语言模型。
项目说明
该项目经站长反复测试,Llama2可以理解你发送的中文,但进行输出回复时是抽奖回复的,有较小概率回复中文,一般都是英文,所以使用起来可能也没有那么方便。
项目相关
项目地址:facebookresearch/llama: Inference code for LLaMA models (github.com)
论文地址:Llama 2: Open Foundation and Fine-Tuned Chat Models | Meta AI Research
安装教程
原本站长写了很长的教程,都已经快写完了。但是突然想到这些开源语言模型五花八门,实在是太麻烦了,于是开始寻找解决方案。
折腾了半天之后,还真的找到了一个解决办法,那就是