目录
前言
学习Python多进程多线程前,大家先要了解什么是线程,什么是进程、共享内存、锁等相关知识点,方便理解后续的内容。
进程和线程的区别
进程是系统进行资源分配和调度的一个独立单位,最小的资源管理单位。线程是进程的一个实体, 是 CPU 调度和分派的基本单位,它是比进程更小的能独立运行的基本单位,最小的 CPU 执行单元。线程拥有的资源:程序计数器、 寄存器、 栈 、状态字。
1. 进程有独立的地址空间,线程有自己的堆栈和局部变量,但线程之间没有单独的地址空间;
2. 进程和线程切换时,需要切换进程和线程的上下文,进程的上下文切换时间开销远远大于线程上下文切换时间,耗费资源较大,效率要差一些;
3. 进程的并发性较低,线程的并发性较高;
4. 每个独立的进程有一个程序运行的入口、顺序执行序列和程序的出口,但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制;
5. 系统在运行的时候会为每个进程分配不同的内存空间;而对线程而言,除了 CPU 外,系统不会为线程分配内存(线程所使用的资源来自其所属进程的资源),线程组之间只能共享资源;
6. 一个进程崩溃后,在保护模式下不会对其他进程产生影响,但是一个线程崩溃整个进程都死掉。所以多进程要比多线程健壮。
共享内存
进程间通信主要包括:管道、命名管道、信号、消息队列、共享内存、内存映射、信号量、Socket。
共享内存: 共享内存允许两个或者多个进程共享物理内存的同一块区域(通常被称为段)。由于一个共享内存段会称为一个进程用户空间的一部分,因此这种 IPC 机制无需内核介入。所有需要做的就是让一个进程将数据复制进共享内存中,并且这部分数据会对其他所有共享同一个段的进程可用。与管道等要求发送进程将数据从用户空间的缓冲区复制进内核内存和接收进程将数据从内核内存复制进用户空间的缓冲区的做法相比,这种 IPC 技术的速度更快。
Python多线程和多进程概念
线程是操作系统创建的,每个线程对应一个代码执行的数据结构,保存了代码执行过程中的重要的状态信息。
没有线程,操作系统没法管理和维护 代码运行的状态信息。
所以没有创建线程之前,操作系统是不会执行我们的代码的。
我们前面写的Python程序,里面虽然没有创建线程的代码,但实际上,当Python解释器程序运行起来(成为一个进程),OS就自动的创建一个线程,通常称为主线程,在这个主线程里面执行代码指令。
当解释器执行我们python程序代码的时候。 我们的代码就在这个主线程中解释执行。
比如:下面这个程序,运行起来后,只有一个线程,就是主线程,在主线程里面,执行代码,顺序下来,一直执行到结束, 主线程就退出了。 同时进程也结束了。
fee = input('请输入午餐费用:')
members = input('请输入聚餐人姓名,以英文逗号,分隔:')
# 将人员放入一个列表
memberlist = members.split(',')
# 得到人数
headcount = len(memberlist)
# 计算人均费用
avgfee = int (fee) / headcount
print(avgfee)现代计算机上面,CPU是多核的, 每个核都可以执行代码。
要运行程序里面的代码,操作系统就会分配一个CPU核心去执行该代码。
有的时候,我们希望,能够让更多的CPU核心同时执行我们的程序里面的一些代码。
假如,我们程序里面有个名为 compress 的函数,执行压缩文件的任务。
现在有4个大文件,需要压缩。
如果是一个CPU核心执行这个函数(单线程的程序),压缩一个文件要10秒钟的话, 那么压缩4个文件,就要40秒。
如果我们能够让 4个CPU核心 同时 执行压缩函数, 理论上就只要 10秒。
有的时候, 我们有一批任务要执行,而这些任务的执行时间主要耗费在 非CPU计算 上面。
比如,我们需要到 前程无忧 网站 抓取 python 开发相关的职位信息。
我们要抓取几百个网页的内容, 执行这些抓取信息的任务的代码,时间主要耗费在等待网站返回信息上面。 等待信息返回的时候CPU是空闲的。
如果我们像以前那样 在一个线程里面,用一个循环 依次 获取100个网页的信息,如下
# 抓取 网页的职位信息
def grabOnePage(url):
print('代码发起请求,抓取网页信息,具体代码省略')
for pageIdx in range(1,101):
url = f'https://search.51job.com/list/020000,000000,0000,00,9,99,python,2,{pageIdx}.html'
grabOnePage(url)就会有很长的时间耗费在 等待服务器返回信息上面。
如果我们能用100个线程,同时运行 获取网页信息的代码, 理论上,可以100倍的减少执行时间。
要让多个CPU核心同时去执行任务,我们的程序必须 创建多个线程 ,让 CPU 执行 多个线程 对应的代码。
Python代码中创建新线程
那么我们的程序代码怎么产生新线程呢?
应用程序必须 通过操作系统提供的 系统调用,请求操作系统分配一个新的线程。
python3 将 系统调用创建线程 的功能封装在 标准库 threading 中。
大家来看下面的一段代码
print('主线程执行代码')
# 从 threading 库中导入Thread类
from threading import Thread
from time import sleep
# 定义一个函数,作为新线程执行的入口函数
def threadFunc(arg1,arg2):
print('子线程 开始')
print(f'线程函数参数是:{arg1}, {arg2}')
sleep(5)
print('子线程 结束')
# 创建 Thread 类的实例对象
thread = Thread(
# target 参数 指定 新线程要执行的函数
# 注意,这里指定的函数对象只能写一个名字,不能后面加括号,
# 如果加括号就是直接在当前线程调用执行,而不是在新线程中执行了
target=threadFunc,
# 如果 新线程函数需要参数,在 args里面填入参数
# 注意参数是元组, 如果只有一个参数,后面要有逗号,像这样 args=('参数1',)
args=('参数1', '参数2')
)
# 执行start 方法,就会创建新线程,
# 并且新线程会去执行入口函数里面的代码。
# 这时候 这个进程 有两个线程了。
thread.start()
# 主线程的代码执行 子线程对象的join方法,
# 就会等待子线程结束,才继续执行下面的代码
thread.join()
print('主线程结束')运行该程序,解释器执行到下面代码时
thread = Thread(target=threadFunc,
args=('参数1', '参数2')
)创建了一个Thread实例对象,其中,Thread类的初始化参数 有两个
target参数 是指定新线程的 入口函数, 新线程创建后就会 执行该入口函数里面的代码,
args 指定了 传给 入口函数threadFunc 的参数。 线程入口函数 参数,必须放在一个元组里面,里面的元素依次作为入口函数的参数。
注意,上面的代码只是创建了一个Thread实例对象, 但这时,新的线程还没有创建。
要创建线程,必须要调用 Thread 实例对象的 start方法 。也就是执行完下面代码的时候
thread.start()新的线程才创建成功,并开始执行 入口函数threadFunc 里面的代码。
有的时候, 一个线程需要等待其它的线程结束,比如需要根据其他线程运行结束后的结果进行处理。
这时可以使用 Thread对象的 join 方法
如果一个线程A的代码调用了 对应线程B的Thread对象的 join 方法,线程A就会停止继续执行代码,等待线程B结束。 线程B结束后,线程A才继续执行后续的代码。
所以主线程在执行上面的代码时,就暂停在此处, 一直要等到 新线程执行完毕,退出后,才会继续执行后续的代码。
join通常用于 主线程把任务分配给几个子线程,等待子线程完成工作后,需要对他们任务处理结果进行再处理。
就好像一个领导把任务分给几个员工,等几个员工完成工作后,他需要收集他们提交的报告,进行后续处理。
这种情况,主线程必须子线程完成才能进行后续操作,所以join就是 等待参数对应的线程完成,才返回。
建线程对象 的时候,不要写成下面这样
thread = Thread(target=threadFunc('参数1', '参数2'))为什么这样写不对?和下面的写法有什么区别?
thread = Thread(target=threadFunc,
args=('参数1', '参数2'))共享数据的访问控制
做多线程开发,经常遇到这样的情况:多个线程里面的代码 需要访问 同一个 公共的数据对象。
这个公共的数据对象可以是任何类型, 比如一个 列表、字典、或者自定义类的对象。
有的时候,程序 需要 防止线程的代码 同时操作 公共数据对象。 否则,就有可能导致 数据的访问互相冲突影响。
请看一个例子。
我们用一个简单的程序模拟一个银行系统,用户可以往自己的帐号上存钱。
对应代码如下:
from threading import Thread
from time import sleep
bank = {
'byhy' : 0
}
# 定义一个函数,作为新线程执行的入口函数
def deposit(theadidx,amount):
balance = bank['byhy']
# 执行一些任务,耗费了0.1秒
sleep(0.1)
bank['byhy'] = balance + amount
print(f'子线程 {theadidx} 结束')
theadlist = []
for idx in range(10):
thread = Thread(target = deposit,
args = (idx,1)
)
thread.start()
# 把线程对象都存储到 threadlist中
theadlist.append(thread)
for thread in theadlist:
thread.join()
print('主线程结束')
print(f'最后我们的账号余额为 {bank["byhy"]}')上面的代码中,一起执行
开始的时候, 该帐号的余额为0,随后我们启动了10个线程, 每个线程都deposit函数,往帐号byhy上存1元钱。
可以预期,执行完程序后,该帐号的余额应该为 10。
然而,我们运行程序后,发现结果如下
子线程 0 结束
子线程 3 结束
子线程 2 结束
子线程 4 结束
子线程 1 结束
子线程 7 结束
子线程 5 结束
子线程 9 结束
子线程 6 结束
子线程 8 结束
主线程结束
最后我们的账号余额为 1为什么是 1 呢? 而不是 10 呢?
如果在我们程序代码中,只有一个线程,如下所示
from time import sleep
bank = {
'byhy' : 0
}
# 定义一个函数,作为新线程执行的入口函数
def deposit(theadidx,amount):
balance = bank['byhy']
# 执行一些任务,耗费了0.1秒
sleep(0.1)
bank['byhy'] = balance + amount
for idx in range(10):
deposit (idx,1)
print(f'最后我们的账号余额为 {bank["byhy"]}')代码都是 串行 执行的。 不存在多线程同时访问 bank对象 的问题,运行结果一切都是正常的。
现在我们程序代码中,有多个线程,并且在这个几个线程中都会去调用 deposit,就有可能同时操作这个bank对象,就有可能出一个线程覆盖另外一个线程的结果的问题。
这时,可以使用 threading库里面的锁对象 Lock 去保护。
我们修改多线程代码,如下:
from threading import Thread,Lock
from time import sleep
bank = {
'byhy' : 0
}
bankLock = Lock()
# 定义一个函数,作为新线程执行的入口函数
def deposit(theadidx,amount):
# 操作共享数据前,申请获取锁
bankLock.acquire()
balance = bank['byhy']
# 执行一些任务,耗费了0.1秒
sleep(0.1)
bank['byhy'] = balance + amount
print(f'子线程 {theadidx} 结束')
# 操作完共享数据后,申请释放锁
bankLock.release()
theadlist = []
for idx in range(10):
thread = Thread(target = deposit,
args = (idx,1)
)
thread.start()
# 把线程对象都存储到 threadlist中
theadlist.append(thread)
for thread in theadlist:
thread.join()
print('主线程结束')
print(f'最后我们的账号余额为 {bank["byhy"]}')执行一下,结果如下
子线程 0 结束
子线程 1 结束
子线程 2 结束
子线程 3 结束
子线程 4 结束
子线程 5 结束
子线程 6 结束
子线程 7 结束
子线程 8 结束
子线程 9 结束
主线程结束
最后我们的账号余额为 10正确了。
Lock 对象的acquire方法 是申请锁。
每个线程在 操作共享数据对象之前,都应该 申请获取操作权,也就是 调用该 共享数据对象对应的锁对象的acquire方法。
如果线程A 执行如下代码,调用acquire方法的时候,
bankLock.acquire()别的线程B 已经申请到了这个锁, 并且还没有释放,那么 线程A的代码就在此处 等待 线程B 释放锁,不去执行后面的代码。
直到线程B 执行了锁的 release 方法释放了这个锁, 线程A 才可以获取这个锁,就可以执行下面的代码了。
如果这时线程B 又执行 这个锁的acquire方法, 就需要等待线程A 执行该锁对象的release方法释放锁, 否则也会等待,不去执行后面的代码。
daemon线程(守护进程)
执行下面的代码
from threading import Thread
from time import sleep
def threadFunc():
sleep(2)
print('子线程 结束')
thread = Thread(target=threadFunc)
thread.start()
print('主线程结束')以发现,主线程先结束,要过个2秒钟,等子线程运行完,整个程序才会结束退出。
因为:
Python程序中当所有的 `非daemon线程` 结束了,整个程序才会结束
主线程是非daemon线程,启动的子线程缺省也是 非daemon 线程。
所以,要等到 主线程和子线程 都结束,程序才会结束。
我们可以在创建线程的时候,设置daemon参数值为True,如下
from threading import Thread
from time import sleep
def threadFunc():
sleep(2)
print('子线程 结束')
thread = Thread(target=threadFunc,
daemon=True # 设置新线程为daemon线程
)
thread.start()
print('主线程结束')再次运行,可以发现,只要主线程结束了,整个程序就结束了。因为只有主线程是非daemon线程。
多进程
Python 官方解释器 的每个线程要获得执行权限,必须获取一个叫 GIL (全局解释器锁) 的东西。
这就导致了 Python 的多个线程 其实 并不能同时使用 多个CPU核心。
所以如果是计算密集型的任务,不能采用多线程的方式。
大家可以运行一下如下代码
from threading import Thread
def f():
while True:
b = 53*53
if __name__ == '__main__':
plist = []
# 启动10个线程
for i in range(10):
p = Thread(target=f)
p.start()
plist.append(p)
for p in plist:
p.join()运行后,打开任务管理器,可以发现 即使是启动了10个线程,依然只能占用一个CPU核心的运算能力。
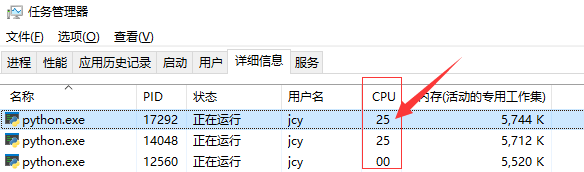
如下图所示,我的电脑有4个核心,这个Python进程占用了1个核心的运行能力,所以下图显示25,表示 25% ,也就是 1/4的CPU占用率

如果需要利用电脑多个CPU核心的运算能力,可以使用Python的多进程库,如下
from multiprocessing import Process
def f():
while True:
b = 53*53
if __name__ == '__main__':
plist = []
for i in range(2):
p = Process(target=f)
p.start()
plist.append(p)
for p in plist:
p.join()运行后,打开任务管理器,可以发现 有3个Python进程,其中主进程CPU占用率为0,两个子进程CPU各占满了一个核心的运算能力。
如下图所示
仔细看上面的代码,可以发现和多线程的使用方式非常类似。
还有一个问题,主进程如何获取 子进程的 运算结果呢?
可以使用多进程库 里面的 Manage 对象,如下
from multiprocessing import Process,Manager
from time import sleep
def f(taskno,return_dict):
sleep(2)
# 存放计算结果到共享对象中
return_dict[taskno] = taskno
if __name__ == '__main__':
manager = Manager()
# 创建 类似字典的 跨进程 共享对象
return_dict = manager.dict()
plist = []
for i in range(10):
p = Process(target=f, args=(i,return_dict))
p.start()
plist.append(p)
for p in plist:
p.join()
print('get result...')
# 从共享对象中取出其他进程的计算结果
for k,v in return_dict.items():
print (k,v)