Sentence-LDA的相关论文:
Jo Y, Oh A H. Aspect and sentiment unification model for online review analysis[C]//Proceedings of the fourth ACM international conference on Web search and data mining. ACM, 2011: 815-824.
模型是这个样子的:
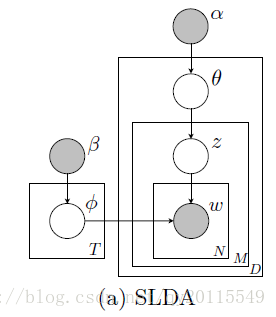
Zhang S, Sha Y, Wang X. Reviews Analysis Based on Sentence and Word Relevance[C]//Computational Intelligence and Design (ISCID), 2014 Seventh International Symposium on. IEEE, 2014, 1: 43-46.
模型是这个样子的:
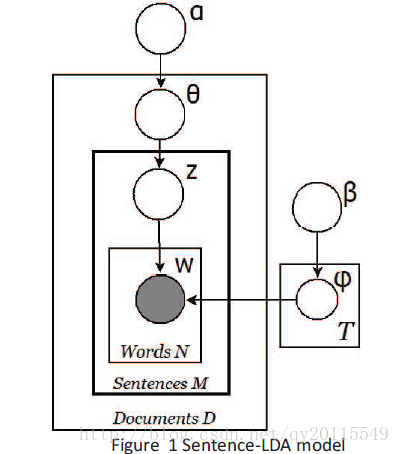
Balikas G, Amini M R, Clausel M. On a Topic Model for Sentences[C]//Proceedings of the 39th International ACM SIGIR conference on Research and Development in Information Retrieval. ACM, 2016: 921-924.
模型是这个样子的:
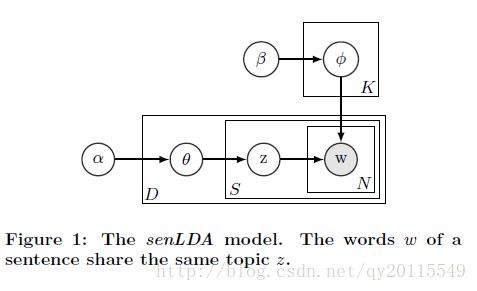
Büschken J, Allenby G M. Sentence-based text analysis for customer reviews[J]. Marketing Science, 2016, 35(6): 953-975.
模型是这个样子的:
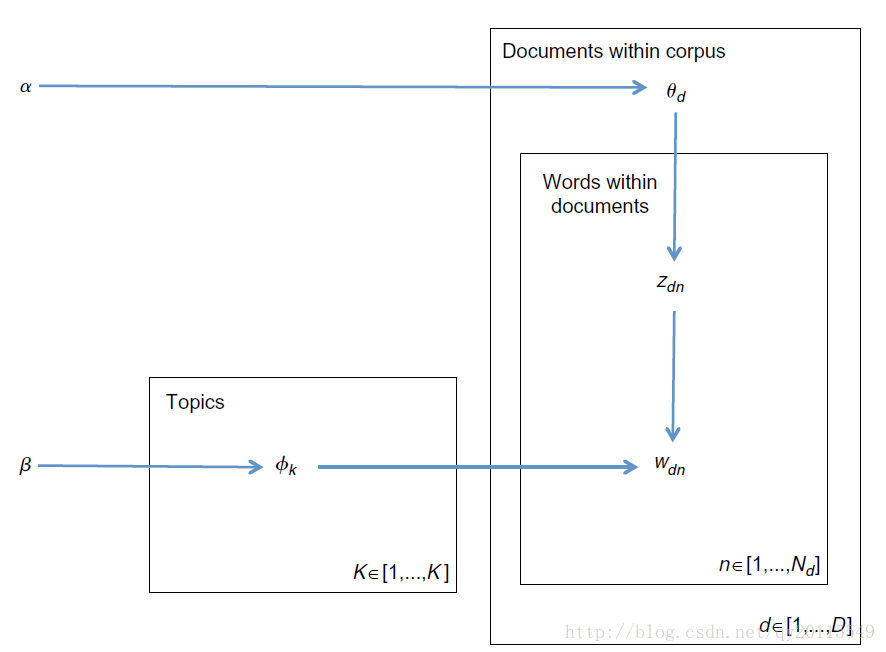
这几篇论文,是我看到的做Sentence-LDA,发现模型都是一样。。。。。哎,他们提出的模型,尽然都是一样的。
Sentence-LDA的思想
LDA的思想是每篇文档是由多个主题混合而成的,每个单词有其对应的主题。但针对短文本而言,每句话可能表达的仅仅是一个主题,Sentence-LDA的假设便是文档中的一个句子来自于一个主题。
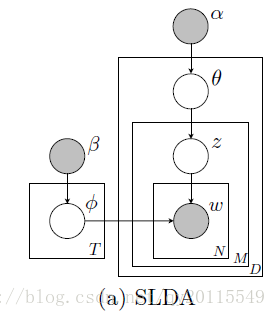
其生成过程如下:

基于上面的图,我解释一下,一篇文档多多个句子,每个句子的所有词均有一个主题z生成。
Gibbs抽样推断
主题z的抽样
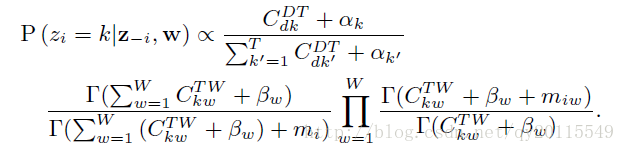
这里需要注意的是i表示第i个句子,可以看出这里抽的是句子的主题。而传统LDA里抽的是词的主题。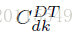
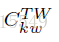
具体该公式的推理,可以看Sentence-based text analysis for customer reviews论文的附录。
文档的主题分布计算
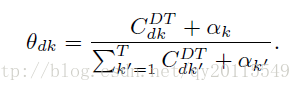
主题的词分布计算
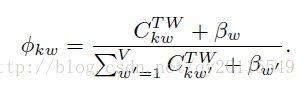
代码
是由16年,On a topic model for sentences这篇文章的作者提供的,为python版本,具体地址为:https://github.com/balikasg/topicModelling/