2020-5-11
Mark Clemens
说明:有一段时间没写博客了,这次正好轻松些,来水一篇关于最常用主题模型的文章。
LDA简介
Latent Dirichlet Allocation, 隐含狄利克雷分布,简称LDA。
LDA诞生于2003年,目前是学术界使用最广泛的主题模型之一,常常用于对论文和专利文本进行主题识别。
使用特性上,简单易用,(目前来看)稳定性其实算是比较好了(后面再解释)。
gensim和sklearn里面都有LDA算法实现。
# gensim
import gensim
gensim.corpora.Dictionary() # .doc2bow()
gensim.models.ldamodel.LdaModel()
# sklearn
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.decomposition import LatentDirichletAllocation
使用上,输入文本语料,预设好主题个数K。模型训练完就能得到K个主题,模型输出一般是:K个主题的topN个高频词。
通过阅读这些高频主题词语,总结这些主题,并为之贴上一个主题标签。所以这里的“主题”是人为给定的,模型只能输出主题下的词语,而我们需要进行人工阅读和总结,才能知道这堆词语对应的主题是什么。
LDA学习资料
上网搜索就能得到,这里只是列出资料名目
1.原始论文:
Blei, David M.; Ng, Andrew Y.; Jordan, Michael I. (2003): Latent dirichlet allocation. In Journal of Machine Learning Research 3, pp. 993–1022.
建议新手先看下面两个资料。
2.学习书籍:
靳志辉 (2013): 《LDA数学八卦》;对具体的算法原理讲得很详细,看第一遍的时候可能还是不太好懂,后期结合代码来理解吧。
3.学习博客:
v_JULY_v 结构之法 算法之道 《通俗理解LDA主题模型》
4.其他
关于LDA的资料非常多,选经典的看看,然后再结合算法实践慢慢地就能理解了。
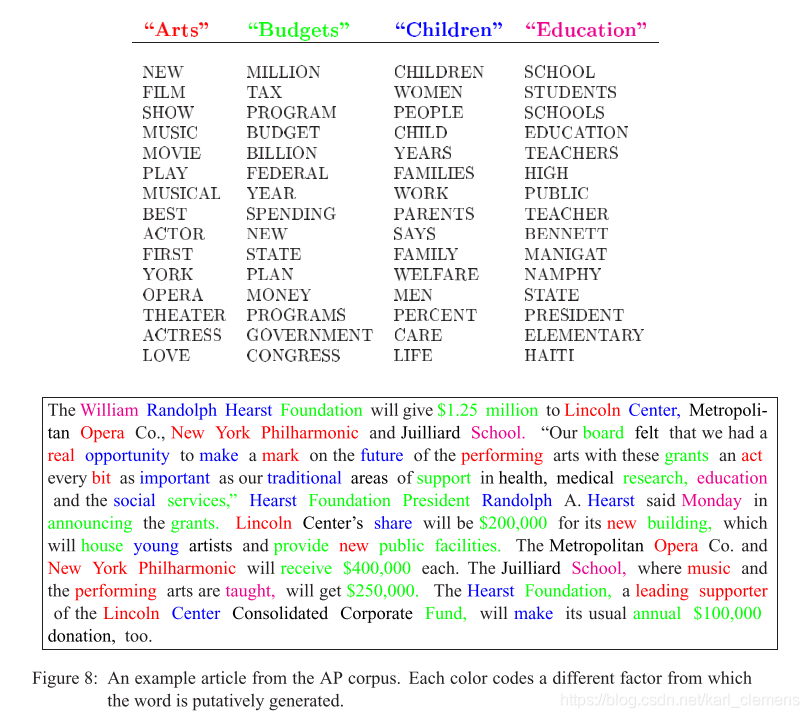
LDA 的使用
模型需要设定参数:先验参数α,β,预设主题个数K, 模型迭代次数iterations.
其中,主题个数K的设定比较主观(见下文),根据需求来设定,如设定为10
先验参数一般使用经典值:α=50/K, β=0.01。
迭代次数iterations,取决于困惑度(见下文)。
迭代次数与困惑度
困惑度perplexity是主题模型的一个评价指标,有固定的计算公式。
主题建模需要进行模型训练,通常需要进行几百或几千次(取决于数据集和参数设定)。在训练的过程中,模型的效果会越来越好,并且最终会趋于稳定。
在这个过程中,困惑度会不断地减少,模型稳定时,困惑度的数值也会趋于稳定。这时候,可以说模型的迭代次数(假如是Iters次)足以让模型表现良好。我们在设定iterations的时候,要满足:iterations ≥ Iters.
主题个数设定
最常见的方式是根据困惑度的收敛值来设定。
模型稳定后,对应的那个困惑度叫做“困惑度收敛值”。
这个值与主题个数有关,一般而言,设定的主题个数越大,困惑度收敛值会越低。但是,随着主题个数增加(自变量),这个收敛值(因变量)也不会一直小下去,也会趋于收敛。??就是说这个变化的收敛值也会再收敛。
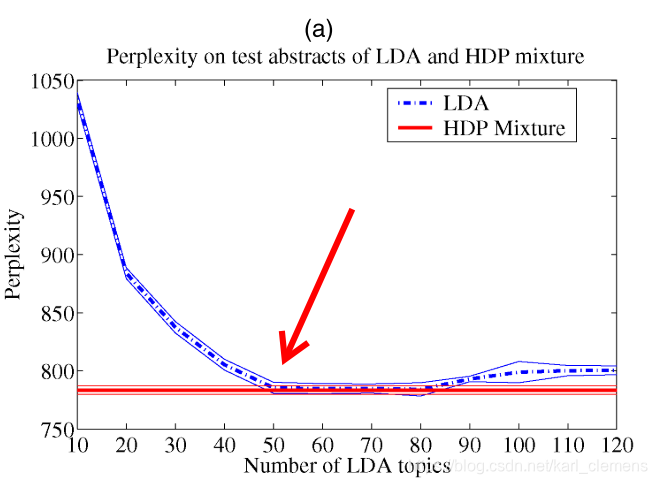
根据这个设定依据,上图对应的LDA设定的主题个数应该是50个,即K=50。
主题个数的设定还有其他的方法合思想,有时间我再整理一篇博客出来。
LDA原理简述
LDA的建模思想(即如何看待文档的组合或形成过程):
文档(doc)由不同主题(topic)组成,每个主题由权重不同单词(word)组成(这里的权重不同可以理解为词频不同)。
理解如下!:主题模型的建模过程就是对文档形成过程的复现,然后再和现实的语料(即文档)进行对比(计算困惑度算是一种比较方式),如果和现实语料比较接近的话,就说明建模效果比较好,也就是认为该主题模型结果和现实语料吻合。
“吻合”以后,模型就可以将各个主题下的高频词语输出,以供使用者进行主题分析和总结、以便对大量的语料进行核心内容的“抽取”(通过提取主题的方式)。
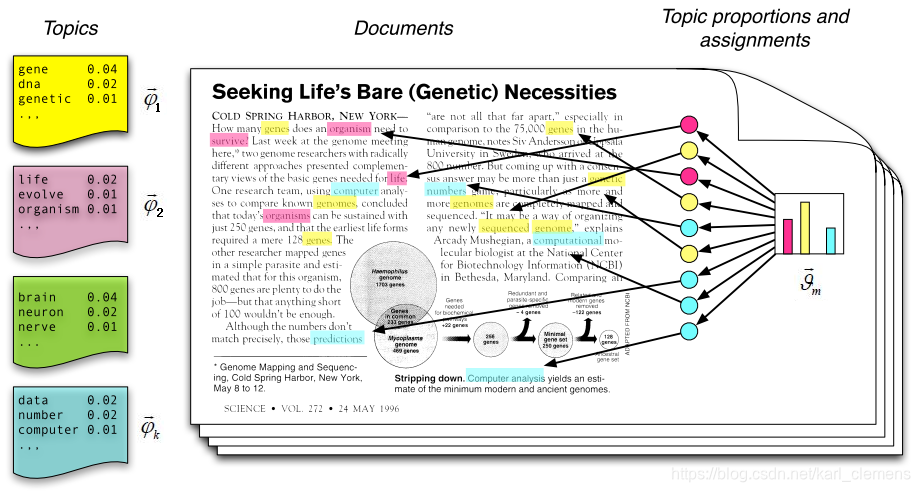
主题模型的过程参考上图进行理解。
主题模型不但可以输出“主题-词语”(上文提到的模型输出就是对应的这个信息),还能输出“文档-主题”信息,可用于文档分类等。
具体的信息使用方法取决于实际需求。
LDA的不足
LDA既稳定也不稳定:
- 主题个数 K 需要预设,而且现有的设定方法,实际上,不是很靠谱
- 结果“不稳定”,具有随机性,即每次建模的结果都不一样(主题顺序和词序都会变化)。
- 结果“太稳定”,主题个数 K 总是一定的,不能自动变化,不同的语料需要设定不同的主题数目。(好处是模型简单,收敛速度较快,结果可靠,总能得到K类主题)
- 主题的总结(标定)由人进行,具有主观性(当然,参数设定[如K]就有主观性)
- …