本文介绍了关于视频增强技术的相关方法包括传统方法和基于深度学习的方法,并给出了他们的对比实验结果,最后对它们简单的做了总结,文中有一些图片和总结来自于网上其他博主的文章,已在文中标记并给出了相关的原文链接,OK,接下来就步入正题吧~
视频去噪概述
https://blog.csdn.net/yanceyxin/article/details/127764236

(1)视频噪声
● 噪声来源主要分为两种:
○ 图像获取中:图像传感器CCD 、CMOS采集图像时,受到传感器材料属性、工作环境、电子元器件、电路结构影响;
○ 图像信号传输中:传输介质和记录设备不完善;
● 噪声分类
○ 高斯噪声:概率密度函数服从高斯分布(正态分布);
○ 泊松噪声:光子离散噪声,实际数字图像中的噪声基本是高斯噪声和泊松噪声的混合噪声;
○ 椒盐噪声、加性噪声、乘性噪声、量化噪声等;
● 噪声场景
○ 夜晚场景:夜晚除了画面不清楚外,大量噪声也是引起视频体验的主要因素;
○ 平坦区域:摄像头的物理硬件的随机波动,在平坦区域会产生被视觉更容易察觉的噪声;
○ 高分辨率:分辨率越高,噪声波动对人眼视觉越明显;
○ 背光区域:由于前后景亮度差异过大,背光区域曝光不足,会让噪声看起来更明显;
(2)视频降噪技术
● 滤波法
○ 空域法:mean filters、gaussian filters、medium filters、bilateral filters、NLM、NLB等;
○ 变换域法:维纳、离散傅立叶、离散小波、DCT等;
○ 混合时空变换法 :BM3D、meshflow、hqdn3d、卡尔曼等;
● 稀疏表达:k-SVD
● 聚类低秩:WNNM(weighted nuclear norm minization,加权核范数最小化)
● 统计模型:高斯混合模型
● 深度学习:DnCNN、FFDNet、CBDNet等;
1.传统去噪方法
https://zhuanlan.zhihu.com/p/51403693
1.1 空域像素特征去噪算法
基于空域像素特征的方法,是通过分析在一定大小的窗口内,中心像素与其他相邻像素之间在灰度空间的直接联系,来获取新的中心像素值的方法,因此往往都会存在一个典型的输入参数,即滤波半径r。此滤波半径可能被用于在该局部窗口内计算像素的相似性,也可能是一些高斯或拉普拉斯算子的计算窗口。在邻域滤波方法里面,最具有代表性的滤波方法有以下几种:

1.1.1 算术均值滤波与高斯滤波
算术均值滤波用像素邻域的平均灰度来代替像素值,适用于脉冲噪声,因为脉冲噪声的灰度级一般与周围像素的灰度级不相关,而且亮度高出其他像素许多。
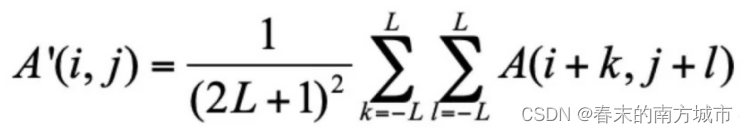
均值滤波结果A'(i,j)随着L(滤波半径)取值的增大而变得越来越模糊,图像对比度越来越小。经过均值处理之后,噪声部分被弱化到周围像素点上,所得到的结果是噪声幅度减小,但是噪声点的颗粒面积同时变大,所以污染面积反而增大。为了解决这个问题,可以通过设定阈值,比较噪声和邻域像素灰度,只有当差值超过一定阈值时,才被认为是噪声。不过阈值的设置需要考虑图像的总体特性和噪声特性,进行统计分析。自适应均值滤波算法通过方向差分来寻找噪声像素,从而赋予噪声像素与非噪声像素不同的权重,并自适应地寻找最优窗口大小,优于一般的均值滤波方法。
高斯滤波矩阵的权值,随着与中心像素点的距离增加,而呈现高斯衰减的变换特性。这样的好处在于,离算子中心很远的像素点的作用很小,从而能在一定程度上保持图像的边缘特征。通过调节高斯平滑参数,可以在图像特征过分模糊和欠平滑之间取得折中。与均值滤波一样,高斯平滑滤波的尺度因子越大,结果越平滑,但由于其权重考虑了与中心像素的距离,因此是更优的对邻域像素进行加权的滤波算法。
1.1.2 统计中值滤波
中值滤波首先确定一个滤波窗口及位置(通常含有奇数个像素),然后将窗口内的像素值按灰度大小进行排序,最后取其中位数代替原窗口中心的像素值。

1.1.3 Wiener滤波
维纳滤波是诺波特·维纳在二十世纪四十年代提出的一种滤波器,即假定线性滤波器的输入为有用信号和噪声之和,两者均为广义平稳过程且知道它们的二阶统计特性,根据最小均方误差准则(滤波器的输出信号与需要信号之差的均方值最小),求得最佳线性滤波器的参数。
维纳滤波器是一种自适应最小均方差滤波器。维纳滤波的方法是一种统计方法,它用的最优准则是基于图像和噪声各自的相关矩阵,它能根据图像的局部方差调整滤波器的输出,局部方差最大,滤波器的平滑作用就越强。
1.1.4 双边滤波
一种非线性的保边滤波方法,是结合图像的空间邻近度和像素值相似度的一种折中处理,同时考虑空域信息和灰度相似性,达到保边去噪的目的。具有简单、非迭代、局部的特点。双边滤波器之所以可以达到保边去噪的效果,是因为滤波器是由两个函数构成。一个函数是由几何空间距离决定滤波器系数。另一个由像素差值决定滤波器系数。双边滤波器中,输出像素的值g(i,j)依赖于邻域像素的值的加权组合
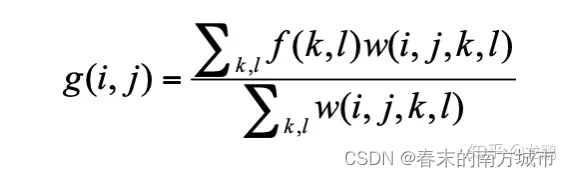

上图中权重系数w(i,j)取决于空域核和值域核的乘积。其中空域滤波器对空间上邻近的点进行加权平均,加权系数随着距离的增加而减少。值域滤波器则是对像素值相近的点进行加权平均,加权系数随着值差的增大而减少。
1.1.5 引导滤波
高斯滤波等线性滤波算法所用的核函数相对于待处理的图像是独立无关的,这里的独立无关也就意味着,对任意图像都是采用相同的操作。
引导滤波就是在滤波过程中加入引导图像中的信息,这里的引导图可以是单独的图像也可以是输入图像,当引导图为输入图像时,引导滤波就成为了一个可以保持边缘的去噪滤波操作.
1.1.6 NLM 算法
(Non-Local means)-NLM,前面基于邻域像素的滤波方法,基本上只考虑了有限窗口范围内的像素灰度值信息,没有考虑该窗口范围内像素的统计信息如方差,也没有考虑整个图像的像素分布特性,和噪声的先验知识。
针对其局限性,NLM算法被提出使用自然图像中普遍存在的冗余信息来去噪声。与常用的双线性滤波、中值滤波等利用图像局部信息来滤波不同的是,利用了整幅图像来进行去噪,以图像块为单位在图像中寻找相似区域,再对这些区域求平均,能够比较好地去掉图像中存在的高斯噪声。
1.1.7 NLB
“Non-Local Bayes” (NL-Bayes)非局部贝叶斯,利用图像的自相似结构进行去噪。
○ 原理
■ one-step
● 找到与给定图像块相似的图像块,并组成3D块
● 协方差滤波
○ 贝叶斯公式应用到3D块;
○ 重新定位3D块;
● 聚合
○ 聚合就是为了消除3D滤波产生的滤波块重叠,被获取的许多估计数需要为每个像素组合;
● Acceleration 加速
■ two-step
● grouping 组块
● Collaborative Filtering 协方差滤波
● Aggregation 聚合
○ 迭代版本
■ Non-local Bayesian Video Denoising 非局部贝叶斯视频去噪
■ https://github.com/pariasm/vnlb
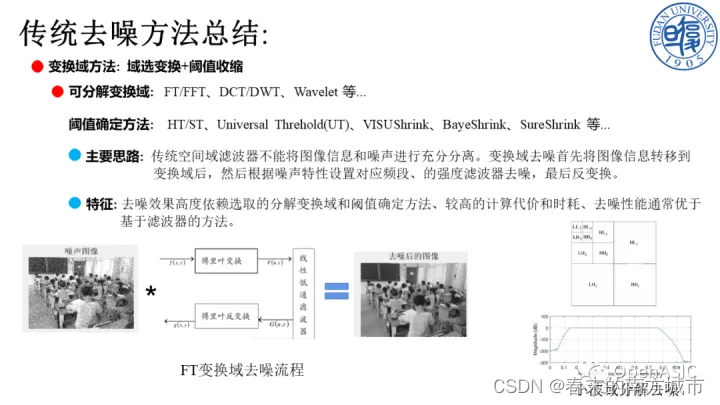
1.2 变换域去噪方法
变换域去噪算法的基本思想是首先进行某种变换,将图像从空间域转换到变换域,然后从频率上把噪声分为高中低频噪声,用这种变换域的方法就可以把不同频率的噪声分离,之后进行反变换将图像从变换域转换到原始空间域,最终达到去除图像噪声的目的。
图像从空间域转换到变换域的方法很多,其中最具代表性的有傅里叶变换、离散余弦变换、小波变换以及多尺度几何分析方法,
下图转载自OpenASIC公众号文章,感谢作者的辛苦工作~
1.3 BM3D去噪算法
https://github.com/gfacciol/bm3d
BM3D是融合了空域spatial denoise和变换域tranform denoise的一种方法,从而可以得到最高的峰值信噪比。它先吸取了NLM中的计算相似块的方法,然后又融合了小波变换域去噪的方法。





2.基于深度学习的去噪方法
常见的基于深度学习的图像去噪方法包括:
1. 基于自编码器的图像去噪方法:自编码器是一种无监督学习的神经网络,它可以将输入图像压缩成一个低维向量,然后再将这个向量解码成与原始图像相同的大小。通过训练自编码器,可以学习到图像的特征,从而实现图像去噪。
2. 基于卷积神经网络的图像去噪方法:卷积神经网络可以通过多层卷积和池化操作来提取图像的特征,从而实现图像去噪。常见的卷积神经网络包括U-Net、ResNet等。
3. 基于生成对抗网络的图像去噪方法:生成对抗网络(GAN)是一种能够生成逼真图像的神经网络,它由一个生成器和一个判别器组成。生成器用于生成逼真图像,判别器用于判断生成的图像是否逼真。通过训练生成对抗网络,可以实现图像去噪。
与图像去噪相比,视频去噪需要考虑时间维度,因此需要设计能够处理时序数据的神经网络。通过训练循环神经网络,对视频进行去噪处理,从而提高视频的清晰度和可视性。
1. 基于3D卷积神经网络的视频去噪方法:3D卷积神经网络可以同时处理时间和空间信息,因此非常适合处理视频数据。通过训练3D卷积神经网络,可以学习视频的时空特征,从而实现视频去噪。
2. 基于光流的视频去噪方法:光流是描述视频中像素运动的一种方法,通过计算光流可以得到视频中像素的运动轨迹。基于光流的视频去噪方法可以利用像素的运动信息来去除视频中的噪声。
3. 基于生成对抗网络的视频去噪方法:与图像去噪类似,生成对抗网络也可以用于视频去噪。通过训练生成对抗网络,可以生成逼真的视频,并去除视频中的噪声。
2.1 DnCNN
https://arxiv.org/pdf/1608.03981.pdf
https://www.appliedaicourse.com/
https://github.com/saproovarun/DnCNN-Keras
DnCNN中有三种类型的层:

- Conv+ReLU:过滤器大小为3,过滤器数量为64,跨步为1,使用零填充保持卷积后的输出形状,使用ReLU作为激活函数。输出为形状(批量大小,50、50、64)
- Conv+批量归一化+ReLU:过滤器大小为3,过滤器数量为64,步长为1,使用零填充保持卷积后的输出形状,使用批量归一化层更好地收敛,ReLU作为激活函数。输出为形状(批次大小,50、50、64)。
- Conv:滤镜大小为3,跨步为1,滤镜数量为c(彩色图像为3个,灰度图像为1个),使用零填充在卷积后保持输出形状。输出形状为(批次大小,50,50,c)。
DnCNN模型的输出为残差图像。因此,原始图像=噪声图像-残差图像。在DnCNN中,在每层卷积之前填充零,以确保中间层的每个特征贴图与输入图像具有相同的大小。
|
|
|


2.2 FFDNet
FFDNet: Toward a Fast and Flexible Solution for CNN based Image Denoising 这篇论文是DnCNN的升级版,网络在对噪声的适应能力和计算量均要优于DnCNN,该算法网络结构如下:

该网络的特点主要有:
- 该网络的结构和DnCNN一致,但是输入输出不同,网络输入为原始带噪图像降采样获得的四张子图以及一张由用户输入的参数σ\sigmaσ生成的噪声水平图像,输出为四张降噪后的子图,通过上采样获得最终的降噪图像。使用的损失函数仍然是MSE。
- 由于该网络的输入中包含一个有用户控制的参数,该算法对于不同噪声的适应程度要优于DnCNN
2.3 CBDNet
Toward Convolutional Blind Denoising of Real Photographs 这篇论文算是FFDNet的再一次升级,在FFDNet中通过添加一个用户输入的噪声强度参数σ\sigmaσ,在CBDNet中通过添加一个全卷积网络来学习该参数,从而达到自适应噪声的目的,该算法的网络结构如下:
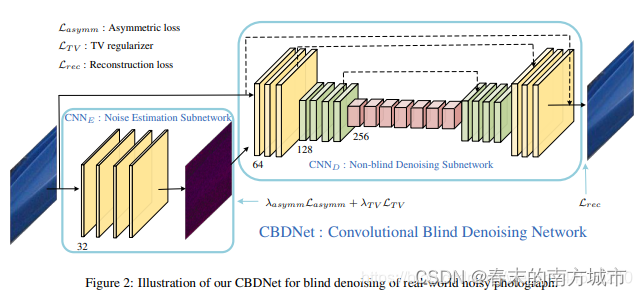
该网络的特点主要有:
- 该网络的结构分为两部分:第一部分为五层全卷积网络用于噪声估计噪声水平图,第二部分与FFDNet不同,为带残差的UnNet,用于降噪。
- 设计了非对称损失函数,目的主要是为了消除非对称敏感性,所谓非对称敏感性指的像BM3D和FFDNet这样的降噪算法,输入降噪参数σ\sigmaσ较小时,降噪效果较差,输入降噪参数σ\sigmaσ较大时,虽然纹理有损失,但是降噪效果仍然比较好。
- 该算法学习的是更接近于真实噪声的高斯泊松噪声,而前面两篇论文都是学习高斯噪声;并且结合使用合成和真实噪声数据来训练模型,提高模型泛化能力,可以更好地对真实场景进行降噪;
2.4 RIDNet
Real Image Denoising with Feature Attention 这篇论文效果比CBDNet要更好,论文指出CBDNet是一个二阶段去噪网络,不够高效灵活,而本文的一阶段算法更加实用,可以在标准差已知或者未知的情况下同时处理高斯泊松噪声,网络结构如下:

网络结构设计包括三部分:特征提取、4个EMA组成的残差模型、重建。其中特征提取和重建模块都是卷积层+ReLU层。EMA的结构如上图中下半部分框图所示:
(1)两个空洞卷积分支增加感受野,拼接并进行卷积融合
(2)两个残差学习结构用于进行特征的提取
(3)由1x1的卷积核构成的注意力机制
结构如下图所示:

2.5 PMRID
Practical Deep Raw Image Denoising on Mobile Devices 是2020 CVPR上旷视提出来的一篇非常elegant的算法,该算法的特点网络结构比较小,通过一个k-sigma变换来解决小网络在不同增益噪声下的鲁棒性问题,网络结构如下图所示:

该网络的主要特点有:
- 这个网络的结构大体上还是一个UNet的结构,为了降低计算量使用了separable conv卷积,然后使用的是5x5的模型来降低模型深度,使用stride为2的卷积进行下采样,以及2x2的deconv结构进行上采样,使用3x3的separable conv来进行skip connnection的通道构建。可以说网络结构是小而精美。
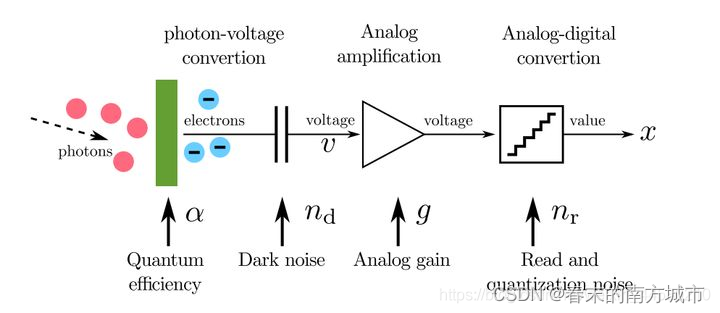
- 论文提出了k-sigma变换,像FFDNet,CBDNet都是通过设置网络参数来适应不同强度的噪声,而本文是通过将不同强度的噪声进行归一化来简化网络结构,这个思路有点类似于generalization anscombe transform,CMOS Sensor的成像模型入下图所示:
2.6 SID
Learning to See in the Dark 这篇论文除了提供一个非常有用的数据集之外,还提出了一个端到端的网络结果,直接处理Raw数据得到去马赛克,去噪和色彩变化后的图像,网络结果如下:
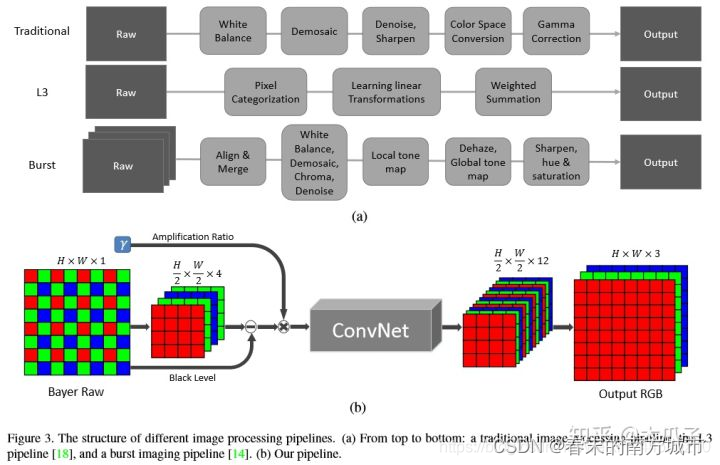
该网络的特点主要有:
- 输入为bayer图拆分出来的4通道数据,分辨率变为原来的一半,输出为12通道的数据,分辨率为原图的一般,然后经过sub-pixel复原全分辨率的RGB三通道数据,其中ConvNet默认是一个UNet的数据结构。
- 损失函数使用L1的损失函数,因此降噪的结果显得比较平滑。
- 该网络并没有专门的设计降噪网络,因此降噪效果并不是特别出色,但是其在颜色复原上会有较为明显的优势,并且该网络泛化能力差,一款相机得单独训练一个网络。
3.实验结果比较
实验数据
(1)SIDD
原始图像:
|
|
|
|
|
|





噪声图像:
|
|
|
|
|
|





(2)SIDD++
原始图像:
|
|
|
|
|
|





噪声图像:
|
|
|
|
|
|





手动噪声(高斯噪声,椒盐噪声,乘法噪声)
原始图像:
3.1 Median Filter
Kernel size:5x5
SIDD result:
|
|
|
|
|
|





SIDD++ result:
|
|
|
|
|
|





3.2 Wiener Filter
Kernel size:5x5
SIDD result:
|
|
|
|
|
|





SIDD++ result:
|
|
|
|
|
|





3.3 DnCNN
SIDD result:
|
|
|
|
|
|





SIDD++ result:
|
|
|
|
|
|





3.4 FFDNet
SIDD result:
|
|
|
|
|
|





SIDD++ result:
|
|
|
|
|
|





4.去噪方法总结
- (1)中值滤波,均值滤波,box滤波对于椒盐噪声的效果较好
(2)高斯滤波对高斯噪声的效果较好
(3)双边滤波可以在滤波的同时保持一定的图像边缘信息