前言
本文将和大家一起探讨python并发编程的实际运用,会以一些我实际使用的案例,或者一些典型案例来分享。本文使用的案例是我实际使用的案例(下篇),是基于之前效率不高的代码改写成并发编程的。让我们来看看改造的过程,这样就会对并发编程的高效率有个清晰地认知,也会在改造过程中学到一些知识。
本文为python并发编程的第十八篇,上一篇文章地址如下:
python:并发编程(十七)_Lion King的博客-CSDN博客
下一篇文章地址如下:
python:并发编程(十九)_Lion King的博客-CSDN博客
一、实施方案:有没有可能image_gray函数也可以优化
通过前两个章节,我们优化了assert_run函数,并且通过进程优化了一些时间,当然耗时最多的部分image_gray函数并没有被优化。本章将一起探讨该部分的优化。
1、image_gray是否可以通过并发优化
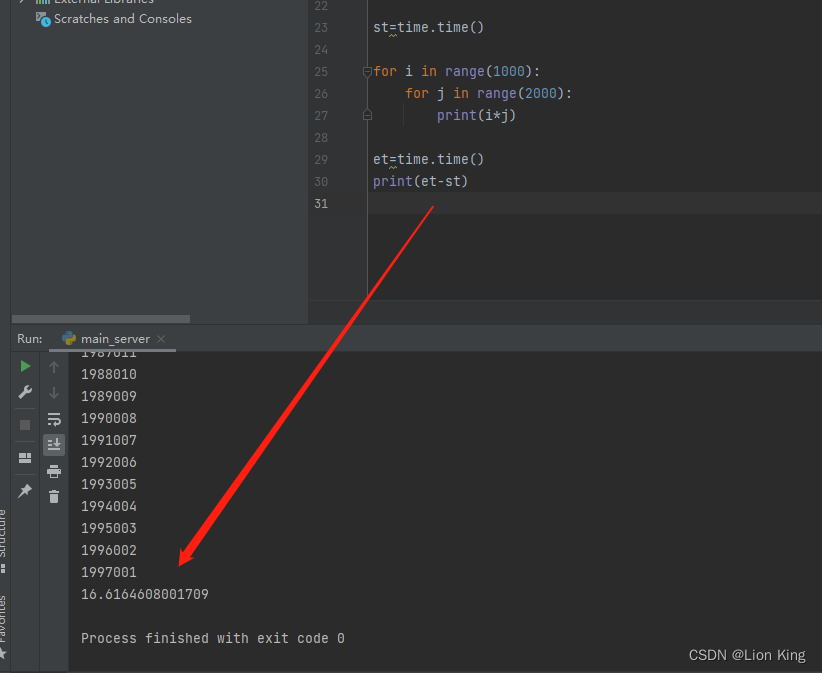
我们先看一下该函数运用到的2个for循环,先用其他for循环模拟他使用的时间,即如下一个简单的函数:
import time
st=time.time()
for i in range(1000):
for j in range(2000):
print(i*j)
et=time.time()
print(et-st)上述函数,在没有并发的情况下耗时16.6秒。
2、多线程改造2个for循环
(1)单线程是花的时间为39秒左右
import concurrent.futures
import time
def process(i, j):
result = i * j
return result
st=time.time()
with concurrent.futures.ThreadPoolExecutor(max_workers=1) as executor:
futures = []
for i in range(1000):
for j in range(2000):
future = executor.submit(process, i, j)
futures.append(future)
# 获取结果
for future in concurrent.futures.as_completed(futures):
result = future.result()
print(result)
et=time.time()
print(et-st)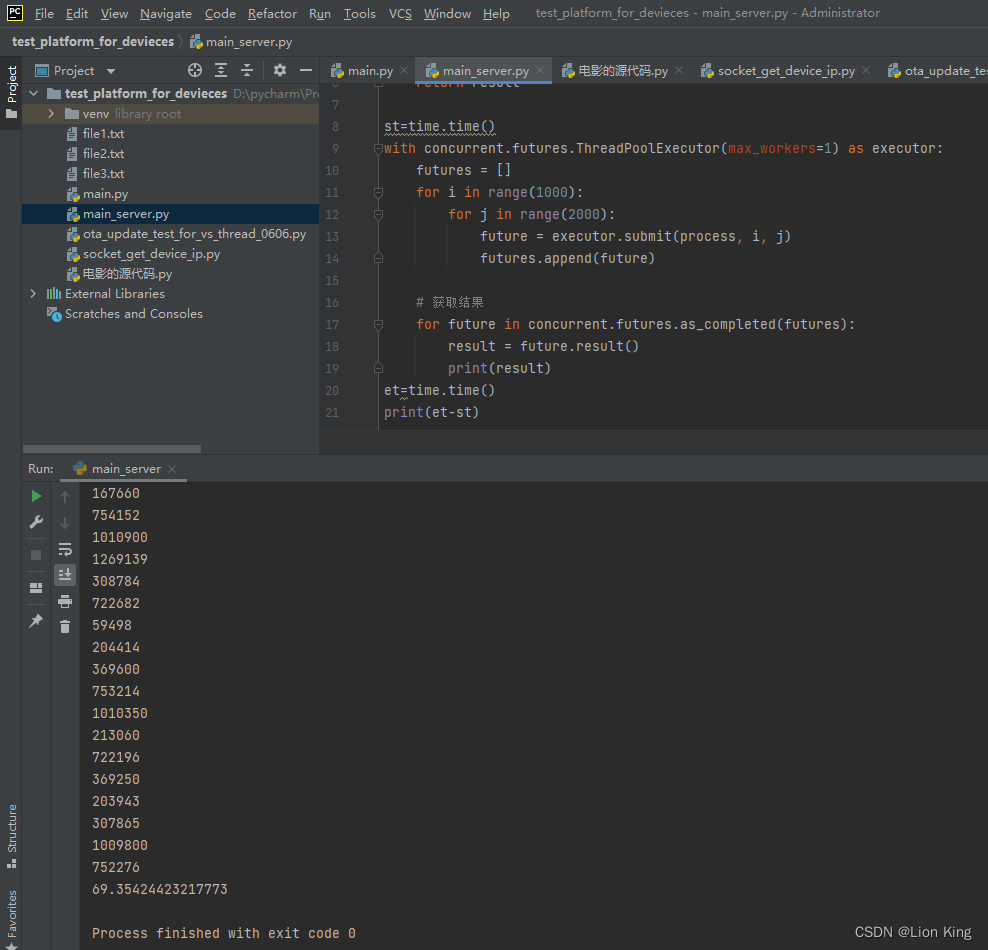
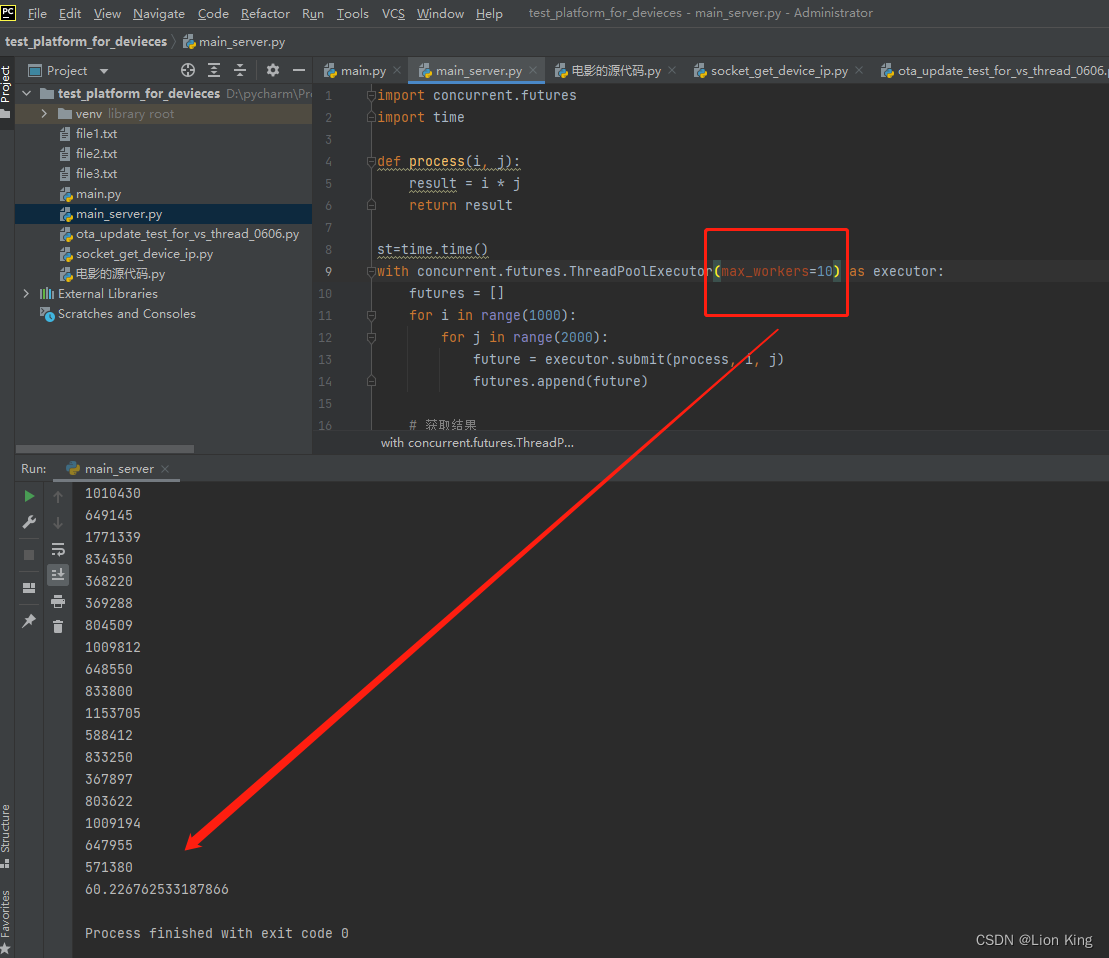
(2)10个线程是花的时间为60秒左右
3、多进程改造2个for循环
(1)单进程是花的时间为502秒左右
import concurrent.futures
import time
def process(i, j):
result = i * j
return result
if __name__ == "__main__":
st=time.time()
with concurrent.futures.ProcessPoolExecutor(max_workers=1) as executor:
futures = []
for i in range(1000):
for j in range(2000):
future = executor.submit(process, i, j)
futures.append(future)
# 获取结果
for future in concurrent.futures.as_completed(futures):
result = future.result()
print(result)
et=time.time()
print(et-st)
(2)10个进程是花的时间为520秒左右

二、来自两个for循环的一点点思考
1、为什么两个for循环不加线程时只花费16秒。加了线程花费60秒?
如果在两个嵌套的 for 循环中添加了线程,并且在每次迭代中启动一个新的线程来执行计算任务,这可能导致执行时间增加的原因有以下几点:
(1)线程创建和销毁开销:创建和销毁线程都会带来一定的开销。如果在每次迭代中都创建新的线程,那么线程的创建和销毁开销将会成为性能瓶颈,从而增加整体执行时间。
(2)线程切换开销:在线程之间进行切换也需要一定的开销。如果线程切换的次数过多,例如在每次迭代中都切换线程,那么线程切换的开销会累积并导致执行时间增加。
(4)GIL(全局解释器锁)限制:如果你使用的是 CPython 解释器,并且每个线程都在执行 CPU 密集型任务(如计算),那么由于 GIL 的存在,同一时间只能有一个线程执行 Python 字节码,其他线程将被阻塞。这就意味着多个线程无法真正并行执行计算任务,反而会带来额外的线程切换开销,从而增加整体执行时间。
综上所述,如果添加线程的目的是为了加速计算任务,但是在 CPU 密集型场景中,由于线程的创建和销毁开销、线程切换开销以及 GIL 的限制,可能会导致执行时间增加。在这种情况下,考虑使用其他并发模型,如多进程或异步编程,可以更好地利用计算资源和提高性能。
2、为什么两个for循环不加进程时只花费16秒。加了进程花费500秒?
如果在两个嵌套的 for 循环中添加了进程,并且在每次迭代中启动一个新的进程来执行计算任务,这可能导致执行时间增加的原因有以下几点:
(1)进程创建和销毁开销:创建和销毁进程都会带来较大的开销。如果在每次迭代中都创建新的进程,那么进程的创建和销毁开销将会成为性能瓶颈,从而增加整体执行时间。
(2)进程间通信开销:在多进程编程中,进程之间需要进行通信和同步操作。这包括数据传输、共享内存等,而这些操作会引入一定的开销。在每次迭代中都涉及进程间通信,会增加额外的开销,导致执行时间增加。
(3)上下文切换开销:在多进程编程中,由于操作系统需要进行进程间的上下文切换,这也会引入一定的开销。在每次迭代中都涉及进程的切换,会增加上下文切换的次数,从而增加执行时间。
(4)全局解释器锁(GIL)限制:如果你使用的是 CPython 解释器,并且每个进程都在执行 CPU 密集型任务(如计算),那么由于 GIL 的存在,同一时间只能有一个进程执行 Python 字节码,其他进程将被阻塞。这就意味着多个进程无法真正并行执行计算任务,反而会带来额外的进程切换和通信开销,从而增加整体执行时间。
综上所述,如果添加进程的目的是为了加速计算任务,但是在 CPU 密集型场景中,由于进程的创建和销毁开销、进程间通信开销、上下文切换开销以及 GIL 的限制,可能会导致执行时间增加。在这种情况下,考虑使用其他并发模型,如多线程或异步编程,可以更好地利用计算资源和提高性能。
3、两个for循环,10个进程花费500秒,10个线程花费60秒,为什么进程比线程慢这么多?
进程和线程的性能差异可能受到以下几个因素的影响:
(1)资源消耗:进程的创建和销毁通常比线程更昂贵,因为进程之间需要独立的内存空间和系统资源。创建和销毁进程需要更多的开销,包括内存分配、文件描述符的复制和清理等。因此,在每次迭代中创建和销毁多个进程可能会导致较高的资源消耗,从而增加执行时间。
(2)上下文切换开销:进程之间的上下文切换比线程之间的上下文切换更昂贵。上下文切换是指操作系统从一个执行单元(进程或线程)切换到另一个执行单元的过程。在多进程情况下,由于进程之间独立的内存空间和资源,上下文切换需要更多的开销,包括保存和恢复进程的状态等。因此,在每次迭代中进行多个进程的切换可能会导致较高的上下文切换开销,从而增加执行时间。
(3)全局解释器锁(GIL):如果你使用的是 CPython 解释器,并且每个线程都在执行 CPU 密集型任务(如计算),那么由于 GIL 的存在,同一时间只能有一个线程执行 Python 字节码,其他线程将被阻塞。但是,在多线程情况下,线程切换的开销通常比进程切换的开销小得多。因此,当涉及到 CPU 密集型任务时,线程可以更好地利用计算资源,而进程由于 GIL 的限制可能无法充分利用多核处理器,导致性能较低。
综上所述,进程比线程慢的原因可能是进程的创建和销毁开销、进程间的上下文切换开销以及全局解释器锁(GIL)的影响。在特定场景下,线程可能更适合执行 CPU 密集型任务,而进程适合执行 I/O 密集型任务或并行处理。然而,对于不同的应用和环境,性能差异可能会有所不同,因此选择合适的并发模型需要考虑具体的需求和条件。
三、使用其他方式优化image_gray函数
1、原函数优化
原函数的代码是用于计算一张图片的平均灰度值。它通过打开图片,遍历每个像素点并计算其灰度值,最后求得平均灰度值并返回。
代码中的逻辑是正确的,但为了提高计算效率,可以考虑使用一些优化技巧,如减少不必要的循环次数、使用向量化计算等。咋们改造如下:
def image_gray(img):
# 打开图片
img = Image.open(img)
# 将图像转换为灰度图
img_gray = img.convert("L")
# 获取图像的像素数据
pixels = list(img_gray.getdata())
# 计算平均灰度值
total_gray = sum(pixels)
avg_gray = total_gray / len(pixels)
return avg_gray
在优化后的代码中,主要做了以下改进:
(1)使用图像的 convert 方法将图像转换为灰度图像,避免了在循环中判断像素的模式。
(2)使用 getdata 方法获取图像的像素数据,返回一个包含所有像素值的列表。
(3)使用 sum 函数计算像素值的总和,而不需要显式地进行循环累加。
(4)直接使用列表的长度作为像素点的总数,避免了在循环中进行计数。
这些优化措施可以提高计算效率和性能。注意,具体的优化方式还取决于图像的大小和处理需求,可以根据实际情况进行调整和改进。
2、优化效果
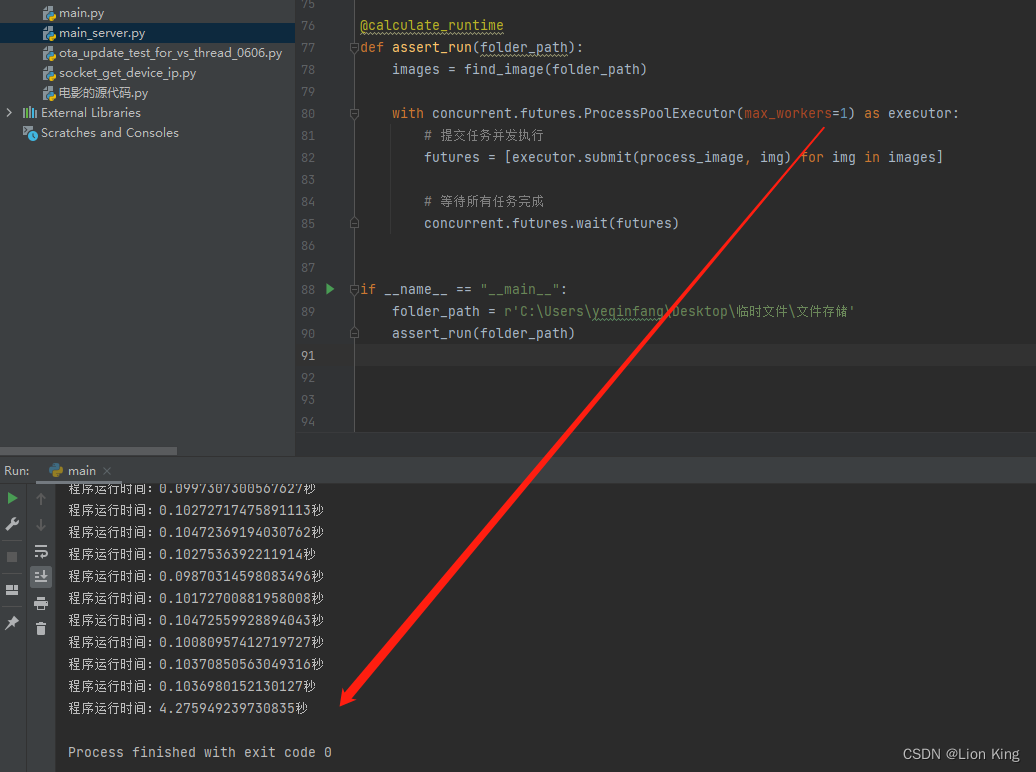
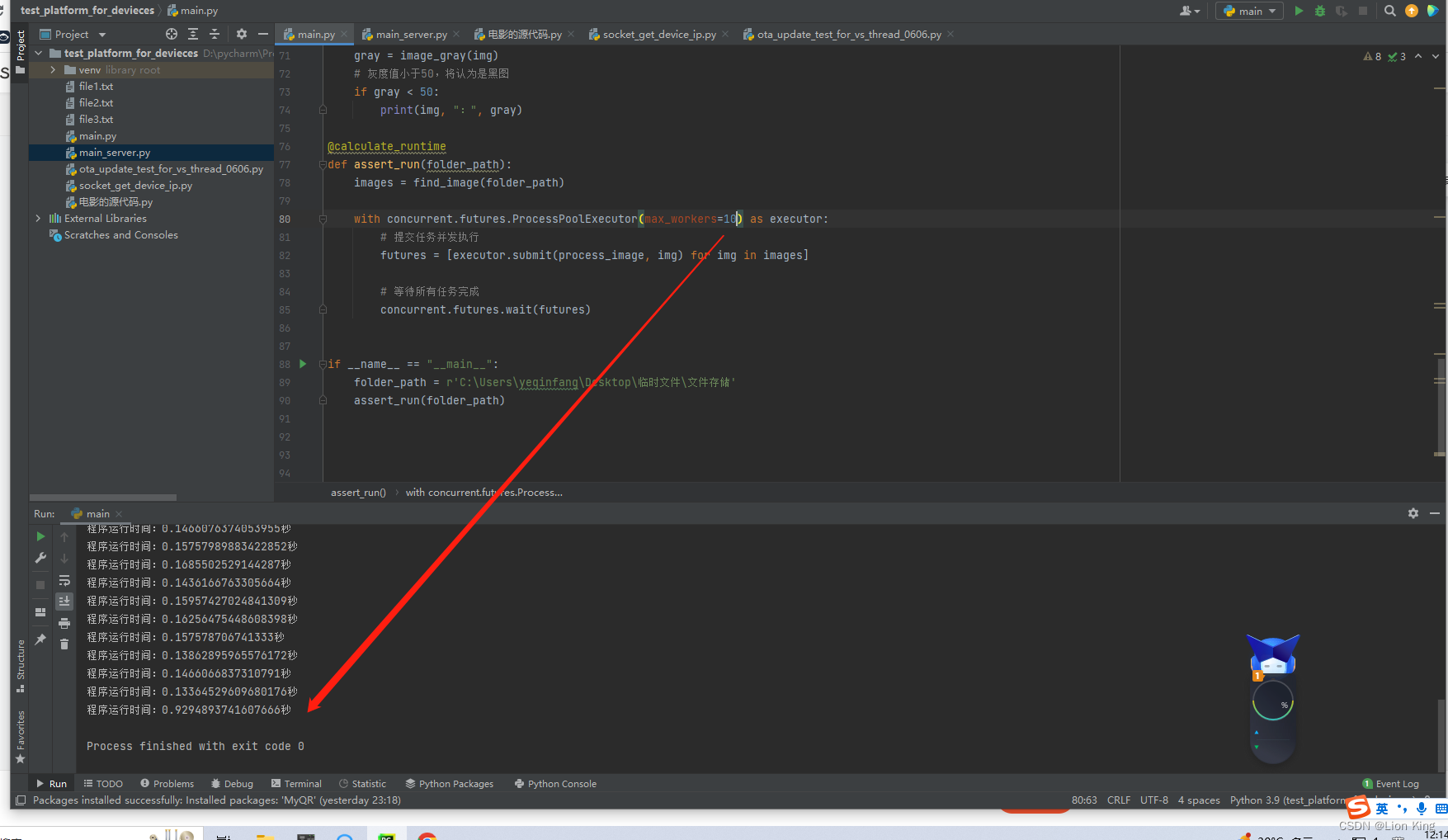
单线程的情况下,处理40张图片只花了4秒钟。10个进程的情况下,只花不到1秒,至此,本项目优化结束。
import os
from PIL import Image
import time
import concurrent.futures
def calculate_runtime(func):
def wrapper(*args, **kwargs):
start_time = time.time()
result = func(*args, **kwargs)
end_time = time.time()
runtime = end_time - start_time
print(f"程序运行时间:{runtime}秒")
return result
return wrapper
# @calculate_runtime
# def image_gray(img):
# # 打开图片
# img = Image.open(img)
#
# # 计算平均灰度值
# gray_sum = 0
# count = 0
# for x in range(img.width):
# for y in range(img.height):
# if img.mode == "RGB":
# r, g, b = img.getpixel((x, y))
# gray_sum += (r + g + b) / 3
# elif img.mode == "L":
# gray_value = img.getpixel((x, y))
# gray_sum += gray_value
# count += 1
#
# avg_gray = gray_sum / count
# return avg_gray
@calculate_runtime
def image_gray(img):
# 打开图片
img = Image.open(img)
# 将图像转换为灰度图
img_gray = img.convert("L")
# 获取图像的像素数据
pixels = list(img_gray.getdata())
# 计算平均灰度值
total_gray = sum(pixels)
avg_gray = total_gray / len(pixels)
# print(avg_gray)
return avg_gray
@calculate_runtime
def find_image(folder_path):
# 定义一个列表存储图片路径
images = []
# 遍历文件夹下的所有文件
for root, dirs, files in os.walk(folder_path):
for file in files:
file_path = os.path.join(root, file)
# 处理每个文件,将其添加到列表中
images.append(file_path)
return images[0:40]
def process_image(img):
gray = image_gray(img)
# 灰度值小于50,将认为是黑图
if gray < 50:
print(img, ":", gray)
@calculate_runtime
def assert_run(folder_path):
images = find_image(folder_path)
with concurrent.futures.ProcessPoolExecutor(max_workers=1) as executor:
# 提交任务并发执行
futures = [executor.submit(process_image, img) for img in images]
# 等待所有任务完成
concurrent.futures.wait(futures)
if __name__ == "__main__":
folder_path = r'C:\Users\yeqinfang\Desktop\临时文件\文件存储'
assert_run(folder_path)