解包操作符
Python 中,** 是一种操作符,称为解包操作符(unpacking operator)或关键字参数传递操作符(keyword argument unpacking operator)。
它的作用是将字典或关键字参数解包,并将解包后的键值对作为关键字参数传递给函数或方法。
具体来说,** 用于两个不同的上下文:
1.函数调用时的解包操作:
当在函数调用中使用 ** 时,它会解包一个字典并将其键值对作为关键字参数传递给函数。
示例:
def my_func(param1, param2):
print(param1, param2)
my_dict = {
'param1': 10, 'param2': 20}
my_func(**my_dict) # 等同于 my_func(param1=10, param2=20)
在上述示例中,my_dict 字典被解包并将其键值对作为关键字参数传递给 my_func 函数。
2.字典的合并操作:
当在字典合并中使用 ** 时,它可以将一个字典的键值对解包并合并到另一个字典中。
示例:
dict1 = {
'a': 1}
dict2 = {
'b': 2, **dict1} # 将 dict1 字典解包并合并到 dict2 字典
print(dict2) # 输出: {'b': 2, 'a': 1}
在上述示例中,dict1 将 dict1 字典解包,并将其键值对合并到 dict2 字典中。
总结来说, 解包操作符在函数调用中用于将字典解包为关键字参数,而在字典合并中用于将字典的键值对解包并合并到另一个字典中。它是一个有用的操作符,可以简化代码并提供更灵活的参数传递方式。
需要注意的是,在 Python 3.5 之前的版本中,字典解包操作符 ** 和关键字参数解包操作符 ** 并不存在,这些功能是在 Python 3.5 版本引入的。
关键字参数
在 Python 中,关键字参数(Keyword Arguments)是一种函数调用的参数传递方式,其中参数以key=value的形式传递给函数。它允许你根据参数的名称明确指定参数的值,而不必按照参数的位置进行传递。
关键字参数提供了以下优点:
1.可选性:可以只传递需要的参数,而不必传递所有参数。这使得函数调用更加灵活。
2.易读性:通过指定参数名称,函数调用变得更加清晰、易于阅读和理解,因为参数的目的和含义在调用时变得明显。
下面是一个使用关键字参数的示例:
def greet(name, age):
print(f"Hello, {name}! You are {age} years old.")
** 使用关键字参数进行函数调用 **
greet(name="Alice", age=30)
在上述示例中,函数greet接受两个参数name和age。通过使用关键字参数,我们明确指定参数的名称和对应的值。这使得函数调用更加清晰易读,不依赖于参数的位置顺序。
关键字参数在函数定义和函数调用时都支持。在定义函数时,可以使用参数名称指定默认值,使其成为可选参数。在调用函数时,可以通过关键字参数指定具体的参数值。
需要注意的是,关键字参数的使用应遵循一定的语法规则:关键字参数必须在位置参数之后传递,并且不能重复指定同一个参数。
总结来说,关键字参数是一种通过指定参数名称传递参数值的方法,它提供了可选性和易读性,使函数调用更加灵活和清晰易懂。
位置参数
在 Python 中,位置参数(Positional Arguments)是一种函数调用的参数传递方式。它是指按照函数定义时参数的位置顺序,依次传递参数值给函数。
位置参数的特点如下:
位置顺序:位置参数需要按照函数定义时参数的位置顺序进行传递。也就是说,第一个位置参数的值应该传递给第一个参数,第二个位置参数的值传递给第二个参数,依此类推。
必需性:位置参数是必需的,也就是说在函数调用中必须为每个位置参数提供一个对应的参数值,否则会导致调用错误。
下面是一个使用位置参数的示例:
def greet(name, age):
print(f"Hello, {
name}! You are {
age} years old.")
# 使用位置参数进行函数调用
greet("Alice", 30)
在上述示例中,函数 greet 接受两个位置参数 name 和 age。在函数调用时,我们按照位置顺序将对应的参数值传递给函数。即 “Alice” 对应 name 参数,30 对应 age 参数。
位置参数的值是根据位置对应的,因此参数的顺序非常重要。在函数定义时,参数的顺序决定了在调用时应该传递的值的顺序。
需要注意的是,如果函数定义中包含默认值参数(默认参数),并且在函数调用时没有为位置参数提供参数值,则将使用默认值。但是,位置参数传递仍然需要按照正确的顺序。
总结来说,位置参数是一种按照函数定义时参数位置顺序传递参数值的方式。它是函数调用中必需的参数,并且参数的顺序非常重要。
有序集合和无序集合区别
有序集合和无序集合的区别在于数据元素的有序性和唯一性。
-
有序集合(Ordered Collection):
有序集合是指元素按照特定顺序排列的集合类型。
有序集合中的元素可以根据它们在集合中的位置进行访问和迭代。
有序集合中的元素可以重复。
在 Python 中,有序集合的代表类型包括列表(list)和元组(tuple)。 -
无序集合(Unordered Collection):
无序集合是指元素没有特定顺序排列的集合类型。
无序集合中的元素不能根据位置进行访问和迭代,因为它们没有固定的顺序。
无序集合中的元素是唯一的,不会重复出现。
在 Python 中,无序集合的代表类型包括集合(set)和字典(dict)。
集合是一组唯一元素的集合,用于数学集合运算。
字典是由键值对组成的集合,用于表示映射关系。
需要注意的是,虽然列表(list)是有序集合,但它的顺序是可变的,可以通过索引操作进行修改。而元组(tuple)是不可变的有序集合,一旦创建后其元素的顺序就不可更改。
总结来说,有序集合是按照特定顺序排列的集合,可以重复;无序集合是元素没有特定顺序排列的集合,元素唯一。
反斜杠被解释为转义字符
报错
File “C:\Users\Administrator\Desktop\data\data\counts.py”, line 6 dirs=[“C:\Users\Administrator\Desktop\data\data\benign_processed”,“C:\Users\Administrator\Desktop\data\data\malware_processed”] ^ SyntaxError: (unicode error) ‘unicodeescape’ codec can’t decode bytes in position 2-3: truncated \UXXXXXXXX escape
解决办法:使用原始字符串(Raw String):在字符串前面加上字母r,可以创建一个原始字符串,其中反斜杠不会被看作转义字符。例如:
dirs = [r"C:\Users\Administrator\Desktop\data\data\benign_processed",
r"C:\Users\Administrator\Desktop\data\data\malware_processed"]
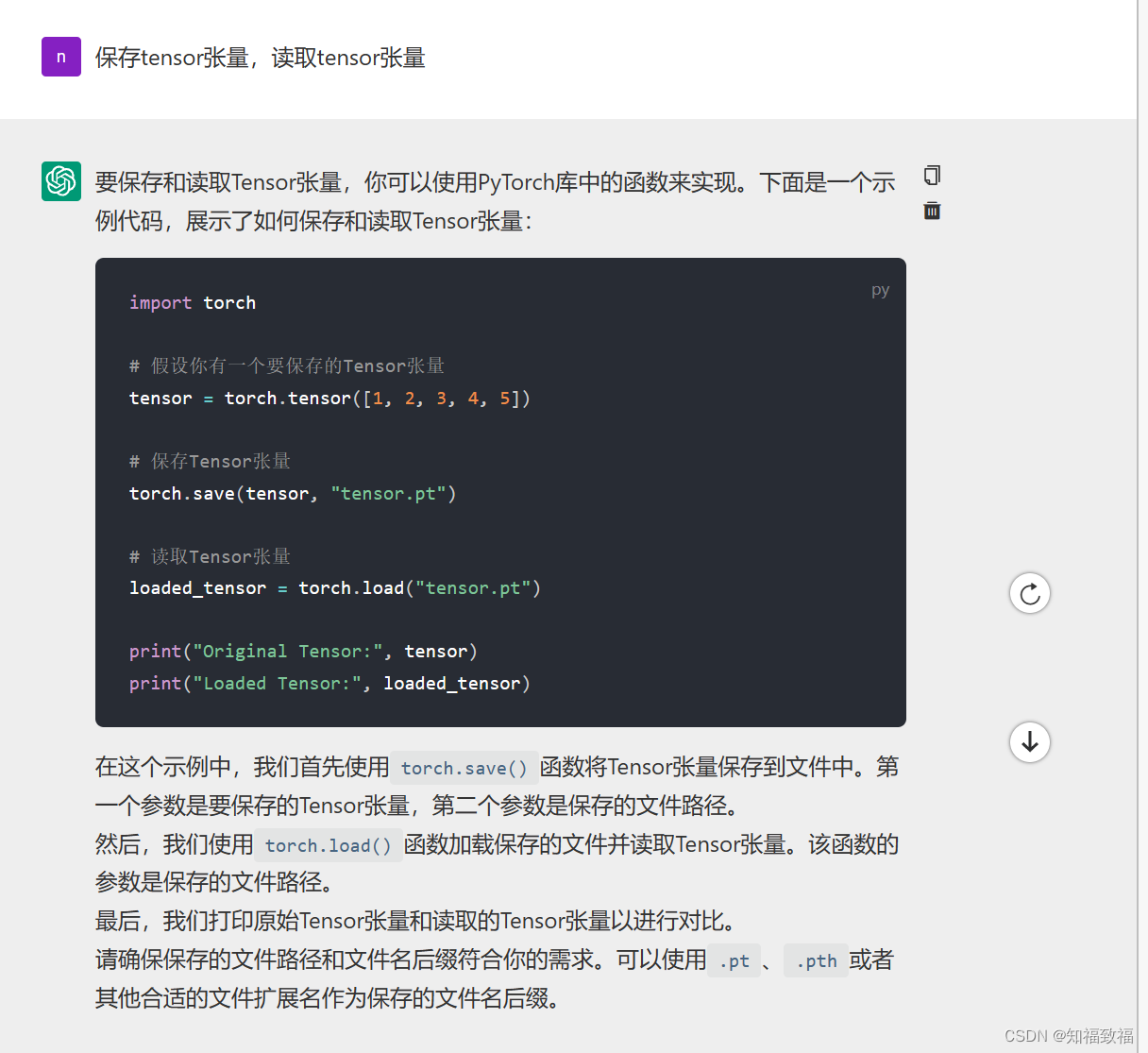
读取和保存tensor
数据集类别分布不均衡
当遇到数据集类别分布不均衡的情况时,你可以采取一些策略来解决这个问题。下面列出了一些常见的方法:
1.重采样(Resampling):重采样是调整数据集中各个类别样本数量的一种方法。可以分为两种类型:
2.过采样(Oversampling):通过增加少数类别的样本数量来平衡数据集。常用的过采样方法有随机复制样本、SMOTE(合成少数类别过采样技术)等。
3.欠采样(Undersampling):通过减少多数类别的样本数量来平衡数据集。常用的欠采样方法有随机删除样本、集群贪心算法等。
重采样方法要根据具体情况谨慎选择。过度的重采样可能导致过拟合问题,而欠采样则可能导致信息损失。可以尝试不同的重采样方法或其组合,并评估模型在平衡后的数据集上的性能。
4.生成合成样本(Synthetic Sample Generation):这是一种通过利用数据集中现有样本生成新的合成样本的方法。SMOTE(合成少数类别过采样技术)是一个常用的方法,它基于少数类别样本之间的线性插值,生成新的合成样本。生成的合成样本可以帮助增加训练数据,并改善少数类别的表示。
5.类别权重(Class Weights):在训练模型时,你可以调整不同类别的样本权重,使得模型在训练过程中更加关注少数类别。这可以通过设置损失函数或优化器中的类别权重来实现。常见的方法包括设置类别权重与其在数据集中的相对频率成反比,或者使用其他基于类别重要性的权重分配策略。
6.模型集成(Model Ensemble):将多个模型的预测结果结合起来,可以提高模型对少数类别的预测性能。可以使用投票、加权平均或堆叠等集成方法。通过使用多个不同的模型,每个模型对不同类别的预测性能可能会有所差异,以此提高整体的预测性能。
7.数据增强(Data Augmentation):对于少数类别的样本,可以应用各种数据增强技术来生成新的样本。例如,在图像分类任务中,可以进行随机裁剪、旋转、翻转、缩放等操作增加样本的多样性。这样可以增加少数类别的样本数量,并且还可以提升模型的鲁棒性和泛化能力。
需要根据具体情况选择合适的方法或它们的组合。尝试不同的方法时,应注意实施后进行充分的评估和验证,以确定是否改善了模型的性能,并酌情进行调整。
f-string 的用法——f-string 的用法
在 Python 中,字符串前面加上 f 是 f-string 的用法。f-string 是一种方便的字符串插值语法,用于将变量嵌入到字符串中。
在 f-string 中,可以在字符串中使用花括号 {} 来插入变量或表达式,并在运行时自动将其替换为对应的值。在花括号内部,可以使用变量名、表达式,以及调用函数等。
以下是一些示例:
name = “Alice”
age = 25
嵌入变量
greeting = f"Hello, {name}!"
print(greeting) # 输出: Hello, Alice!
嵌入表达式
message = f"{name} is {age + 1} years old."
print(message) # 输出: Alice is 26 years old.
嵌入函数调用
uppercase_name = f"{name.upper()}"
print(uppercase_name) # 输出: ALICE
使用 f-string 可以更简洁地将变量嵌入到字符串中,提高代码的可读性和可维护性。在 f-string 中,还可以结合格式化选项来控制变量的显示格式,例如指定小数位数、填充字符等。
请注意,f-string 是在 Python 3.6 版本引入的,需要确保你的 Python 版本高于等于 3.6 才能使用该特性。
惰性加载
Lazy loading(惰性加载)是一种延迟加载数据的策略,即在需要时才加载数据,而不是一次性加载整个数据集。这种策略可以提高内存效率并减少初始化时间,尤其适用于处理大型数据集或需要高内存消耗的情况。
在机器学习和深度学习中,数据集可能非常庞大,难以一次性全部加载到内存中。另外,某些任务(例如训练或预测)可能只需要访问数据集中的一部分,而不需要加载全部数据。在这些情况下,使用惰性加载可以带来一些好处。
惰性加载在实现上可以通过以下方式实现:
1.数据集划分:将整个数据集划分为多个小批次(batches)或数据块(chunks),每次只加载当前需要的批次或块。这样,只有在需要时才会加载数据,而不是一次性加载整个数据集。
2.迭代器或生成器:使用迭代器或生成器的方式逐个生成数据样本,而不是一次性返回全部样本。迭代器或生成器会在每次迭代时提供一个样本,然后根据需要读取下一个样本。这样可以按需加载数据,减少内存占用和初始化时间。
3.分布式加载:对于分布式系统,可以分布加载数据,将数据集分布在多个节点上进行并行加载和处理。这种方式可以提高数据加载和处理的速度。
惰性加载在处理大型数据集和节约内存方面具有重要的优势,尤其适用于限制内存资源的环境和需要高效处理大规模数据的任务。但需要注意,在使用惰性加载时,要注意数据的顺序和随机性,以及在迭代和训练过程中处理好数据加载和批处理的逻辑,以确保正确性和效率。
提取隐蔽特征
在某些任务中,一些类别的特征可能相对较为罕见或难以捕捉。由于这些特征在数据集中出现的频率较低,模型可能无法充分学习它们,从而导致对这些类别的辨别能力较弱。为了解决这个问题,提供更多的样本可以增加这些类别的训练样本数量,从而帮助模型更好地学习到这些隐蔽的特征。
通过增加少数类别的样本数量,可以提供更多的样本以增强模型对于隐蔽特征的学习能力。这可能包括数据采集、数据合成或者使用生成模型等技术,以便创造更多的样本。
值得注意的是,提供更多的样本并不仅仅是增加数据集中的样本数量,还需要确保增加的样本能够准确地代表这些类别的隐蔽特征。因此,在收集额外样本或生成合成样本时,需要谨慎选择数据来源和生成方法,以保证样本的质量和代表性。