Datawhale202211—李宏毅《机器学习》“神经网络训练不起来怎么办”
局部最小值与鞍点+批次与动量+自动调整学习速率+损失函数+批次标准化
文章目录
前言
本节内容非常实用,可以成为网络训练优化手册,未来也可以进一步增删改查。这里主要介绍5种网络优化的办法,主流的解决思路都涵盖了,全面有逻辑。
一、局部最小值与鞍点
What
在网络训练的过程中,会碰到经过几轮训练Loss不再变化的情况,甚至刚刚开始训练Loss就没有理想的变化,神经网络训不动了,我们就要问发生了什么,该怎么处理呢?
Why
首先我们会发现参数不再更新了,Loss当然就不会再有变化,再往深想就是gradient接近0,参数当然就不会再变化,但目前的值显然就不是我们需要的结果,接下来探讨数学层面的原理:
gradient=0与minima或maxma并非一一对应,local minima(local maxma)与saddle point处gradient都是0,它们被称为critical point。
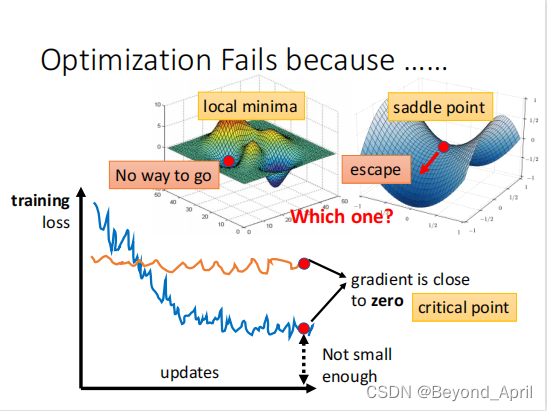
How(重点)
当然最重要的是遇到这样的情况我们该如何处理,接下来从数学层面讲起:
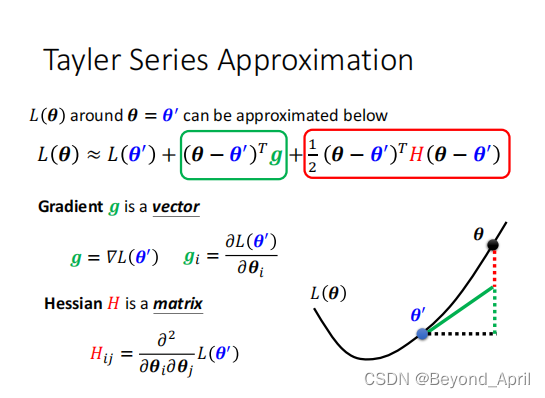
- 首先确定LOSS函数的形状,local min or local max or saddle point,进而确定现在的状态。
用泰勒展开式来表示据θ很小距离的θ′的函数形状,表达式如上图
- 第一项表示θ与θ′相距很近时,L(θ)与L(θ′)非常接近
- 第二项的核心是g,用来弥补θ与θ′的差距
- 第三项的核心是H矩阵,再一次弥补θ与θ′的差距
当g=0是,上式第二项可去掉,因此第三项决定函数形状
positive definite就是正定矩阵。这么看我们需要代入所有的v才能确定v^THv是大于0还是小于0,显然这很麻烦。但是相信大家都学过线性代数。正定矩阵的充分必要条件是特征值全>0。

分析Hessian矩阵:
- 如果其所有特征值都是正的,就说明是local minima(局部最小值点)。
- 如果其所有特征值都是负的,就说明是local maxima(局部最大值点)。
- 如果其所有特征值有正有负,就说明是saddle point(鞍点)。
手推示例

二、批次与动量
什么是batch size
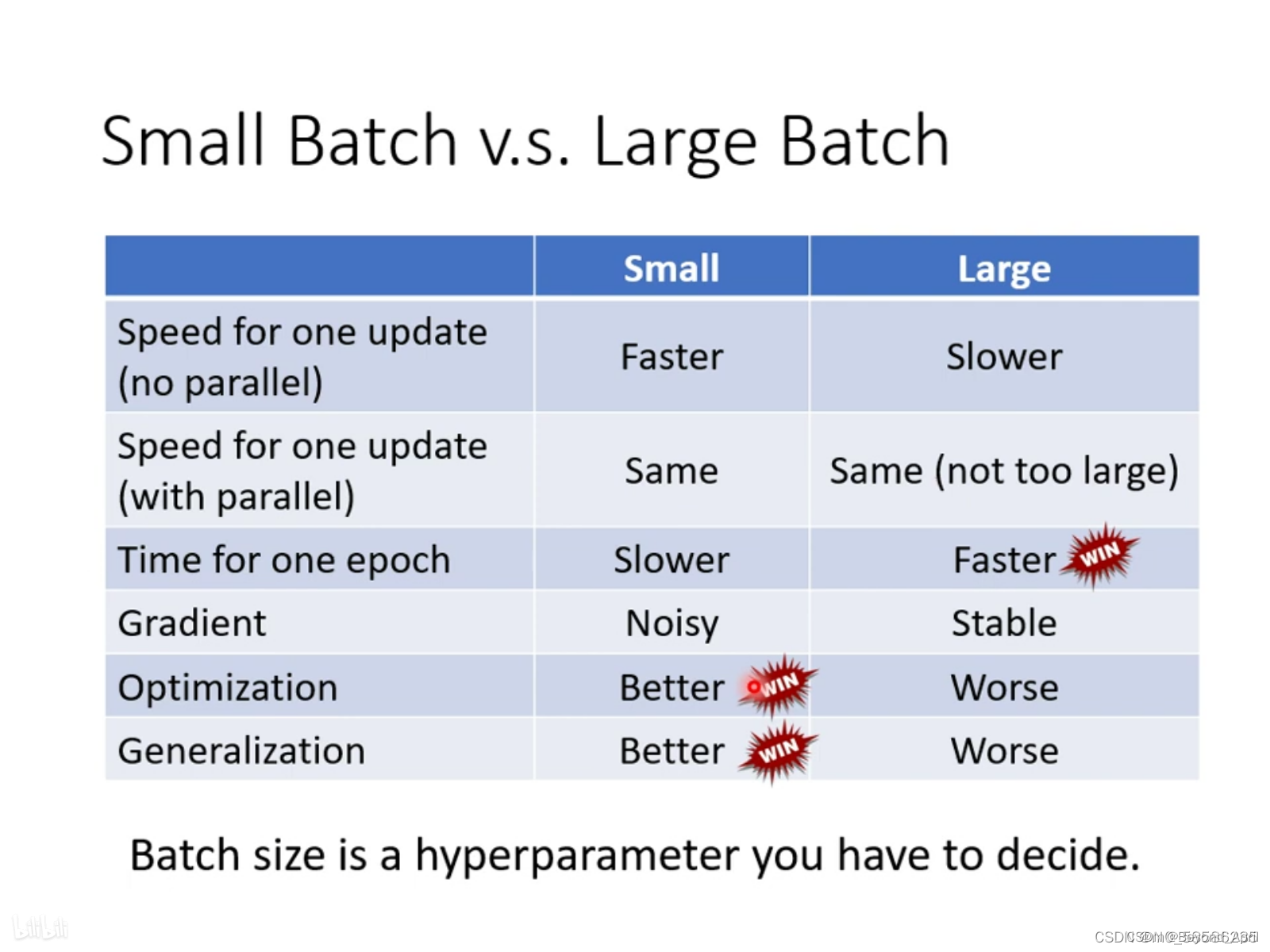
当采用较小的梯度进行梯度下降时可能会出现:
- 梯度在损失函数较为平缓段,下降速度十分缓慢
- 梯度下降停在鞍点
- 梯度下降停在局部最小值

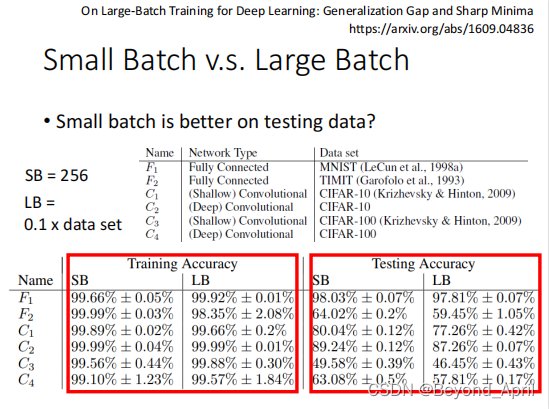
这是我们会使用小的batch size,让每一个数据都敏感地显示在最终结果上,具体定义可见上图举例。
怎么用batch
在使用batch的时候,不仅要看到本身的特点,还要和GPU的能力结合,对于较小的batch在平行计算的GPU下速度不会受到影响,所以batch size的大小与特性往往不一定和数量呈比例,需要取决于具体情况,经验会在这时起作用。
什么是动量

当前动量= λ * 上一步的动量-当前梯度
(λ为自定义参数,动量是一个与所有历史梯度有关的值)
每一步的动量方向,取当前动量方向与上一步梯度反方向中间的方向。
当加入动量进行运算后,就不会使梯度在损失函数梯度较小处变化较慢,或卡在局部最小值,或在局部最小值附近震荡。
三、自动调整学习速率
Why
学习率:决定梯度下降的步长因素
为什么要进行自动调整学习率呢?
因为,当训练一个network时,train到最后发现,loss不在下降,有两种原因:
- 卡到了local minima or saddle point
- gradient decent 始终上下徘徊
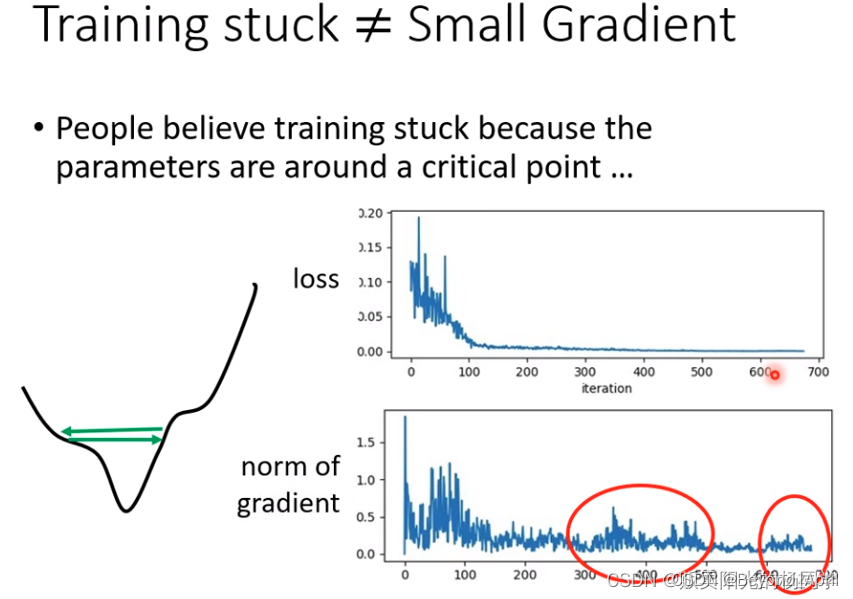
除了之前讨论过的问题,还可以考虑客制化learning rate - 在error surface中,遇到平滑面,learning rate 大,步伐大。
- 在error surface中,遇到斜坡面,learning rate 小,步伐小。
How
- Root Mean Square
1.下图θ下标表示第i个参数,上标表示RMS在第t个步骤
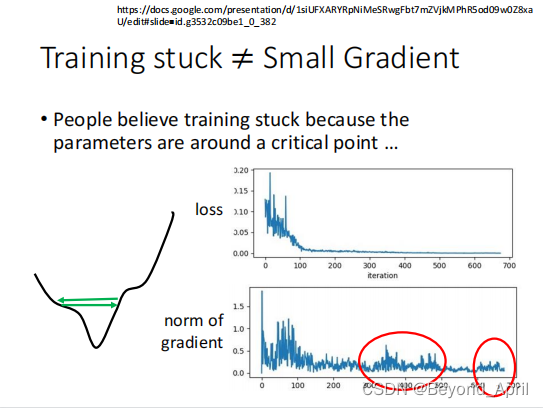
2.为什么能够实现自动调整learning rate?

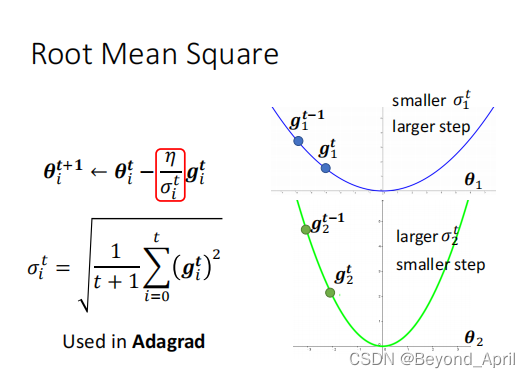
但是问题并没有完全解决,因为我们往往面对很多参数,哪怕是针对一个参数,也会随时间调整learning rate,需要进一步解决。
- PMSProp (plus版)
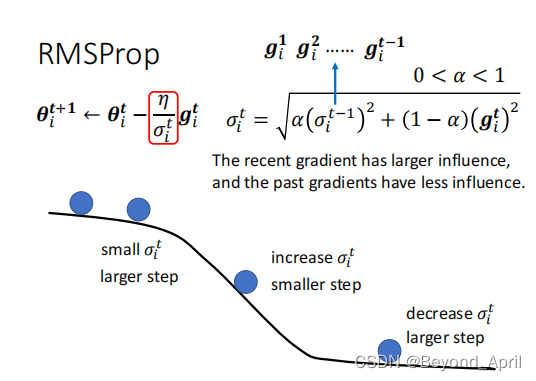
这里主要加入了一个超参数α,让整个过程更可控。
然后,今天最常用的optimization策略是什么呢?
Adam ,而Adam = RMSProp + Momentum
四、损失函数的影响
损失函数我们不止一次讨论过,其他相关问题可以找对应内容参考,这里我们主要介绍训练难以进行同样会受损失函数的影响。
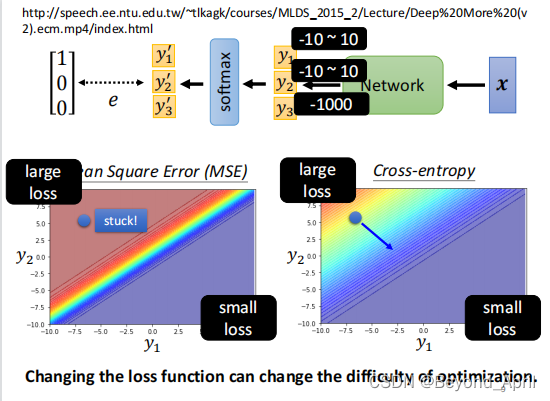
上图说明,在其他条件严格一致的分类问题中,不同的损失函数会得到相差很大的结果。
五、批次标准化
Why
本节我们探讨网络优化问题,之前的方法总是想在流程上使用更优的方法,这里我们提供另外一个思路——简化问题——标准化数据集。更有规律的数据集可以让训练更有效率。
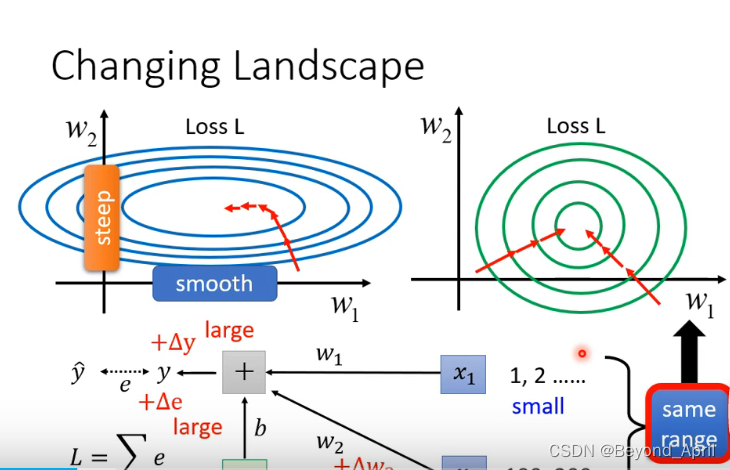
How
-
Feature Normalization
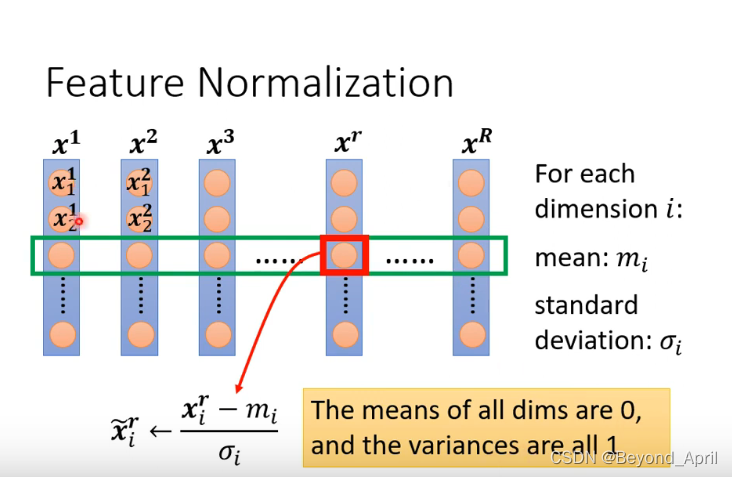
1.FN计算方法
dimension:维度

经过这样的计算,使同一纬度的值平均数为0,方差为1,这样可以使dimension都在0上下,来制造出一个比较好的Error Surface,最终让Loss收敛得更快一些。
2.DL应用
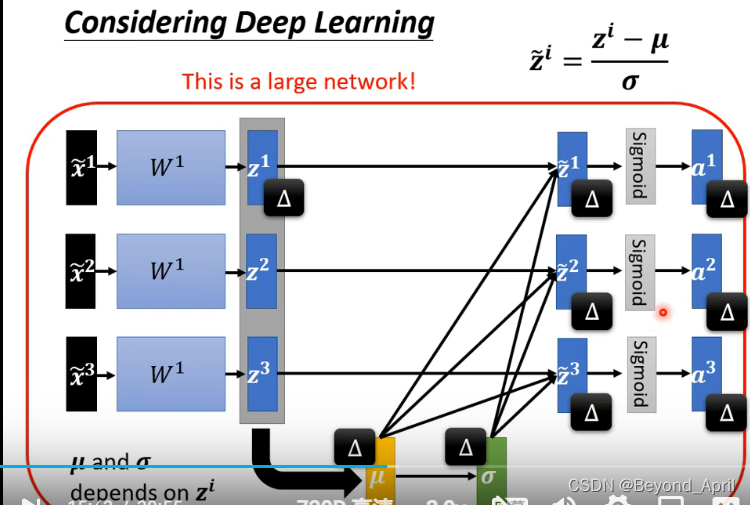
3.标准化中间结果
DL网络往往有很多层,按照之前的处理办法,可能直对一层输入有作用。因此我们需要对中间结果同样进行类似的计算,并注意这样会带来大量的计算量,因此我们可以分批次标准化。 -
Testing

该方法主要应对数据上传较慢的场景,这时不必等待所有数据上传完成再计算,而是采用分批次计算,不断更新结果。 -
Batch normalization 在CNN中的应用
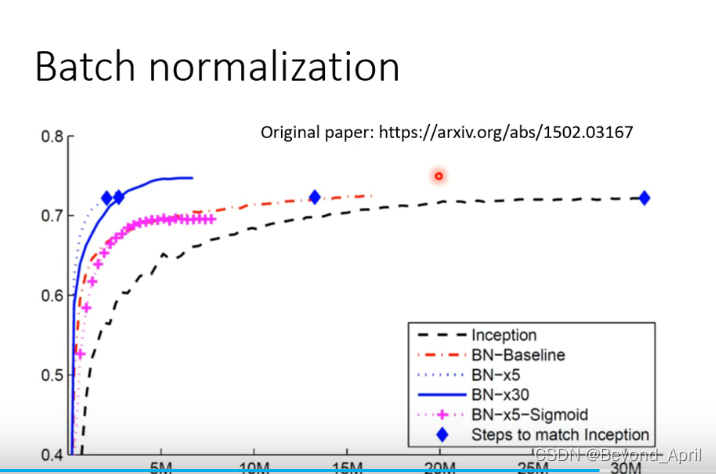
这里可以很好地看到进行BN后的高性能,哪怕是在使用更加复杂的激活函数仍然十分高效,可见做标准化的工作意义非凡!
**期待更多的方法可以服务标准化!!!**以下是知名的相关工作:

六、参考文档
来自Datawhale的投喂
李宏毅《机器学习》开源内容1:
https://linklearner.com/datawhale-homepage/#/learn/detail/93
李宏毅《机器学习》开源内容2:
https://github.com/datawhalechina/leeml-notes
李宏毅《机器学习》开源内容3:
https://gitee.com/datawhalechina/leeml-notes
来自官方的投喂
李宏毅《机器学习》官方地址
http://speech.ee.ntu.edu.tw/~tlkagk/courses.html
李沐《动手学深度学习》官方地址
https://zh-v2.d2l.ai/
来自广大网友的投喂
深度学习优化算法Adam
https://www.jianshu.com/p/3e363f5e1a79
损失函数的全面介绍
点这里
损失函数对网络有什么影响
https://blog.csdn.net/weixin_33809981/article/details/89752960
总结
1.本节受益匪浅,一方面是缕清很多概念的前世今生,为什么出现,怎样解决,之前虽然也听过这些方法但这次是一个非常清晰的总结。
2.目前只是理论介绍,而本节内容往往也可以当作目录来用,当我们实际训练中遇到问题来找合适的解决办法,希望后续能补充时间案例。
3.最近狠狠体会到手推公式的好处,并没有想想中那么困难但对理解大有裨益,往往也能理清很多相近的概念。
4.感谢Datawhale的小伙伴们特别是组内成员的坚持和帮助,要冲刺啦!!!