一. 整体架构的优化
hive计算引擎不仅仅支持MapReduce,并且还支持Tez, Spark等.根据不同的计算引擎又可以使用不同的资源调度和存储系统。
整体架构优化点:
1.根据不同业务需求进行日期分区,并执行动态分区.
相关参数设置:
0.14中默认hive.exec.dynamic.partition=true
2.为了减少磁盘存储空间以及I/O次数.对数据进行压缩
相关参数设置:
job输出文件按照BLOCK以Gzip方式压缩
mapreduce.output.fileoutputformat.compress=true
mapreduce.output.fileoutputformat.compress.type=BLOCK
mapreduce.output.fileoutputformat.compress.codec=org.apache.hadoop.io.compress.GzipCodecmap输出结构也以Gizp进行压缩.
mapreduce.map.output.compress=true
mapreduce.map.output.compress.codec=org.apache.hadoop.io.compress.GzipCodec对hive输出结果和中间结果进行压缩。
hive.exec.compress.output=true
hive.exec.compress.intermediate=true3、hive中间表以SequenceFile保存,可以节约序列化和反序列化的时间
相关参数设置:
hive.query.result.fileformat=SequenceFile二.Map 阶段的优化
hive的操作符:
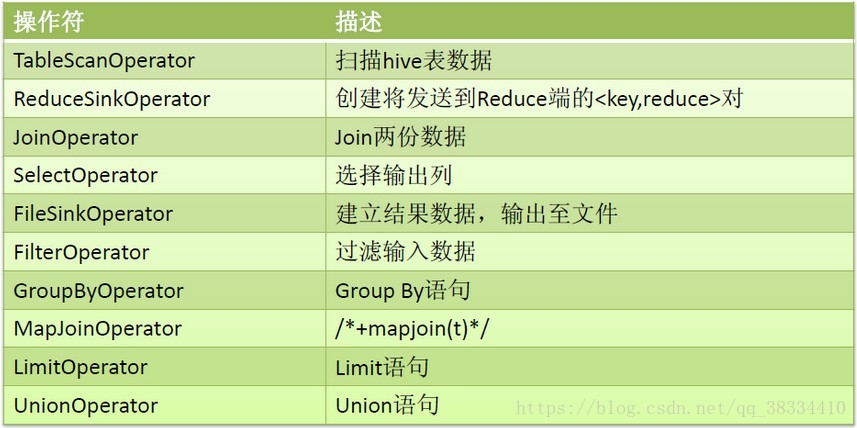
执行流程为:
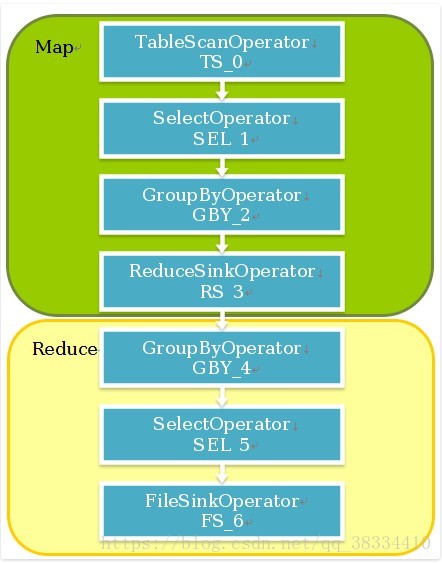
reduce切割算法:
相关参数设置,默认为:
hive.exec.reducers.max=999
hive.exec.reducers.bytes.per.reducer=1G
reduce task num=min{reducers.max,input.size/bytes.per.reducer},可以根据实际需求来调整reduce的个数。
三. Job优化
1.本地执行
默认关闭了本地执行模式,小数据可以使用本地模式,加快执行速度.
相关参数:
hive.exec.mode.local.auto=true
默认本地执行的条件是,hive.exec.mode.local.auto.inputbytes.max=128MB, hive.exec.mode.local.auto.tasks.max=4,reduce task最多1个。 性能测试:
数据量(万) 操作 正常执行时间(秒) 本地执行时间(秒)
170 group by 36 16
80 count 34 6
2.map join
默认map join是打开的. hive.auto.convert.join.noconditionaltask.size=10MB
装载到内存的表必须是通过scan的表(不包括group by等操作),如果join的两个表都满足上面的条件,/mapjoin/指定表格不起作用,只会装载小表到内存,否则就会选那个满足条件的scan表。
四. SQL优化
整体的优化策略如下:
去除查询中不需要的column
Where条件判断等在TableScan阶段就进行过滤
利用Partition信息,只读取符合条件的Partition
Map端join,以大表作驱动,小表载入所有mapper内存中
调整Join顺序,确保以大表作为驱动表
对于数据分布不均衡的表Group by时,为避免数据集中到少数的reducer上,分成两个map-reduce阶段。第一个阶段先用Distinct列进行shuffle,然后在reduce端部分聚合,减小数据规模,第二个map-reduce阶段再按group-by列聚合。
在map端用hash进行部分聚合,减小reduce端数据处理规模。