Speech-to-Text-WaveNet : End-to-end sentence level English speech recognition using DeepMind's WaveNet
来源:https://github.com/buriburisuri/speech-to-text-wavenet#version
这是一个完整的基于DeepMind公司WaveNet网络的英文语音识别案例。
尽管ibab和tomlepaine已经实施了tensorflow版本的WaveNet,但他们没有实现语音识别。 这就是我们决定自己实施的原因。
Deepmind最近的一些论文很难复制。 该文件还省略了有关实施的具体细节,我们必须以我们自己的方式填补空白。
下面是一些重要的笔记:
首先:论文中用于语音识别实验使用的数据集是TIMIT的数据集,而我们使用VTCK数据集。
第二:论文中在用于降采样的扩展卷积之后使用了一个平均池化层,我们从wav文件中提取MFCC特征并且移除了最后的平均池化层,因为原始数据在TitanX GPU上运行是不可能的。
第三:因为TIMIT数据集具有音素标签,训练模型的时候使用了两个损失项,音素分类和下一个音素预测。相反,我们使用了单一的CTC损失,因为VCTK提供了句子级别的标签。因此我们只使用扩大的conv1d图层而没有使用任何扩大的conv1d图层(As a result, we used only dilated conv1d layers without any dilated conv1d layers.)怎么个翻译?
最后:最后,由于时间限制,我们没有通过结合语言模型来进行BLEU评分和后处理等定量分析。
最终的体系结构如下图所示。
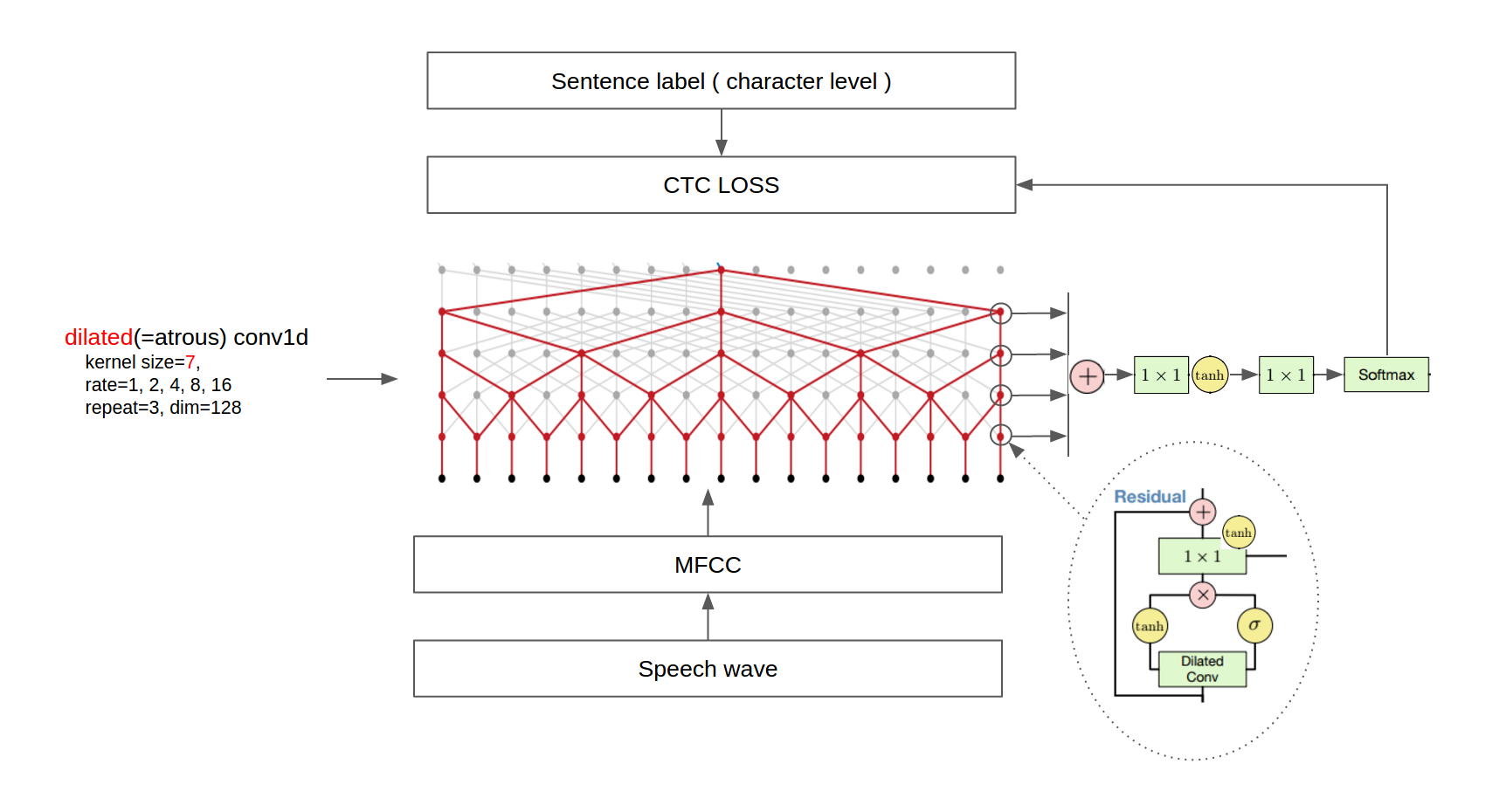
(Some images are cropped from [WaveNet: A Generative Model for Raw Audio](https://arxiv.org/abs/1609.03499) and [Neural Machine Translation in Linear Time](https://arxiv.org/abs/1610.10099))
版本:
但前版本0.0.0.2
依赖:版本必须正确匹配
1.TensorFlow==1.0.0
2.sugartensor==1.0.0.2
3.pandas>=0.19.2
4.scikits.audiolab==0.11.0
如果您遇到librosa库问题,请尝试通过以下命令安装ffmpeg。 (Ubuntu 14.04)
sudo add-apt-repository ppa:mc3man/trusty-media
sudo apt-get update
sudo apt-get dist-upgrade -y
sudo apt-get -y install ffmpeg
数据集:
我们使用VCTK,LibriSpeech和TEDLIUM发布2个语料库。 由上述三个语料构成的训练集合中句子总数为240612。 有效和测试集仅使用LibriSpeech和TEDLIUM corpuse构建,因为VCTK语料库没有有效的测试集。 下载完每个语料库后,将它们提取到'asset / data / VCTK-Corpus','asset / data / LibriSpeech'和'asset / data / TEDLIUM_release2'目录中。
在Tom Ko等人的论文中,音频得到了增强。 (感谢@migvel为您提供的信息)
数据集预处理:
TEDLIUM版本2数据集提供SPH格式的音频数据,所以我们应该将它们转换为librosa库可以处理的某种格式。 在“asset/data”目录中运行以下命令将SPH转换为.wav格式。
find -type f -name '*.sph' | awk '{printf "sox -t sph %s -b 16 -t wav %s\n", $0, $0".wav" }' | bash
如果你没有安装sox,需要按照以下命令安装:
sudo apt-get install sox
我们发现主要的瓶颈是训练时的磁盘读取时间,所以我们决定将整个音频数据预处理成小得多的MFCC特征文件。 我们强烈建议使用SSD而不是硬盘。
在控制台中运行以下命令以预处理整个数据集。
python preprocess.py
网络训练:
执行
python train.py ( <== Use all available GPUs )
or
CUDA_VISIBLE_DEVICES=0,1 python train.py ( <== Use only GPU 0, 1 )
python train.py ( <== Use all available GPUs )
or
CUDA_VISIBLE_DEVICES=0,1 python train.py ( <== Use only GPU 0, 1 )训练网络。 您可以在'asset / train'目录中看到结果ckpt文件和日志文件。 启动tensorboard --logdir asset / train / log来监控训练过程。
python train.py ( <== Use all available GPUs )
or
CUDA_VISIBLE_DEVICES=0,1 python train.py ( <== Use only GPU 0, 1 )我们已经在3个Nvidia 1080 Pascal GPU上训练了这个模型,历时40个小时,直到50个epoch,并且我们在验证损失最小时选择了这个epoch。 在我们的例子中,它是epoch是40.如果你面对内存不足的错误,请将train.py文件中的batch_size从16减少到4。
每一个epoch的CTC损失见下表:
python train.py ( <== Use all available GPUs )
or
CUDA_VISIBLE_DEVICES=0,1 python train.py ( <== Use only GPU 0, 1 )| epoch | train set | valid set | test set |
|---|---|---|---|
| 20 | 79.541500 | 73.645237 | 83.607269 |
| 30 | 72.884180 | 69.738348 | 80.145867 |
| 40 | 69.948266 | 66.834316 | 77.316114 |
| 50 | 69.127240 | 67.639895 | 77.866674 |
测试网络:
完成训练之后,你可以检查测试集的CTC损失通过运行下面这条命令:
python train.py ( <== Use all available GPUs )
or
CUDA_VISIBLE_DEVICES=0,1 python train.py ( <== Use only GPU 0, 1 )python test.py --set train|valid|test --frac 1.0(0.01~1.0)如果你想要使用数据集的一小部分数据进行快速评估,frac参数会非常有用。
将wave文件转换成英文文本:
执行
python recognize.py --file 来使得.wav文件转换成英文文本文件。结果可以在console中打印出来;如下:
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0000.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0001.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0002.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0003.flac
python recognize.py --file asset/data/LibriSpeech/test-clean/1089/134686/1089-134686-0004.flac结果如下:
he hoped there would be stoo for dinner turnips and charrats and bruzed patatos and fat mutton pieces to be ladled out in th thick peppered flower fatan sauce
stuffid into you his belly counsiled him
after early night fall the yetl lampse woich light hop here and there on the squalled quarter of the browfles
o berty and he god in your mind
numbrt tan fresh nalli is waiting on nou cold nit husband
真实值应当是:
HE HOPED THERE WOULD BE STEW FOR DINNER TURNIPS AND CARROTS AND BRUISED POTATOES AND FAT MUTTON PIECES TO BE LADLED OUT IN THICK PEPPERED FLOUR FATTENED SAUCE
STUFF IT INTO YOU HIS BELLY COUNSELLED HIM
AFTER EARLY NIGHTFALL THE YELLOW LAMPS WOULD LIGHT UP HERE AND THERE THE SQUALID QUARTER OF THE BROTHELS
HELLO BERTIE ANY GOOD IN YOUR MIND
NUMBER TEN FRESH NELLY IS WAITING ON YOU GOOD NIGHT HUSBAND
如前所述,没有语言模型,所以有些情况下大写字母,标点符号和单词拼写错误。
时间关系以下内容未翻译
pre-trained models
You can transform a speech wave file to English text with the pre-trained model on the VCTK corpus. Extract the following zip file to the 'asset/train/' directory.
Docker support
See docker README.md.
Future works
Language Model
Polyglot(Multi-lingual) Model
We think that we should replace CTC beam decoder with a practical language model
and the polyglot speech recognition model will be a good candidate to future works.
Other resources
ibab's WaveNet(speech synthesis) tensorflow implementation
tomlepaine's Fast WaveNet(speech synthesis) tensorflow implementation
Namju's other repositories
SugarTensor
EBGAN tensorflow implementation
Timeseries gan tensorflow implementation
Supervised InfoGAN tensorflow implementation
AC-GAN tensorflow implementation
SRGAN tensorflow implementation
ByteNet-Fast Neural Machine Translation
Citation
If you find this code useful please cite us in your work:
Kim and Park. Speech-to-Text-WaveNet. 2016. GitHub repository. https://github.com/buriburisuri/.
Authors
Namju Kim ([email protected]) at KakaoBrain Corp.
Kyubyong Park ([email protected]) at KakaoBrain Corp.
python train.py ( <== Use all available GPUs )
or
CUDA_VISIBLE_DEVICES=0,1 python train.py ( <== Use only GPU 0, 1 )
python recognize.py --file