语音识别技术解析
一、基本知识
- 语音识别系统的基本框架:特征提取+模式匹配
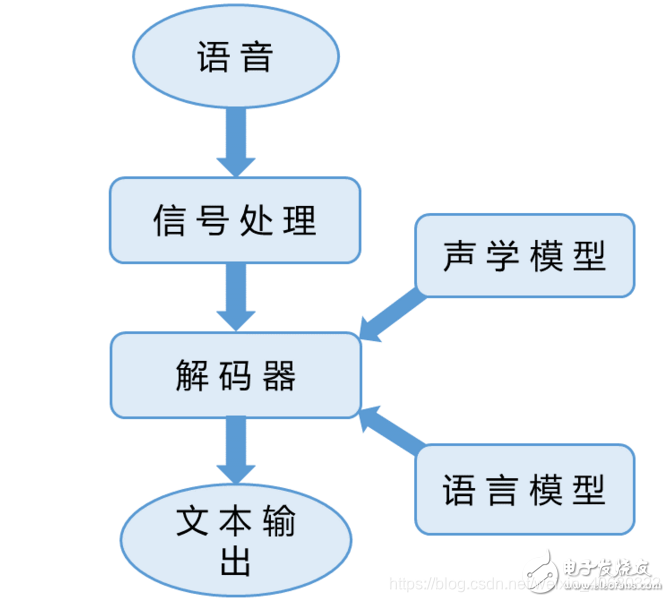
- 解码:基于搜索的模式匹配过程(语音识别的模式匹配是一个序列匹配问题,一般表现为一个搜索过程)。
- 解码器:实现解码的模块。
- 解码时所用的两个信息源:
-
- 声学模型:描述每个音素如何发音。
-
- 语言模型:描述单词的组合规律。
- 语音识别系统的标准配置:
- 2010年前:
(1)特征:Mel倒谱系数(MFCC);
(2)声学模型:GMM-HMM;
(3)语言模型:N元文法(N-Gram);
(4)解码:有限状态转移机(Finite State Transducer, FST)。 - 今天:语音识别已经过渡到了深度学习阶段,识别系统的基础框架不变,只是特征提取和声学建模的具体技术发生了改变。
二、MFCC特征提取:该特征主要描述与发音内容有关的声道信息,并模拟人耳的听觉特性,增加对低频段信息的敏感度。
三、GMM-HMM声学模型(概率模型)
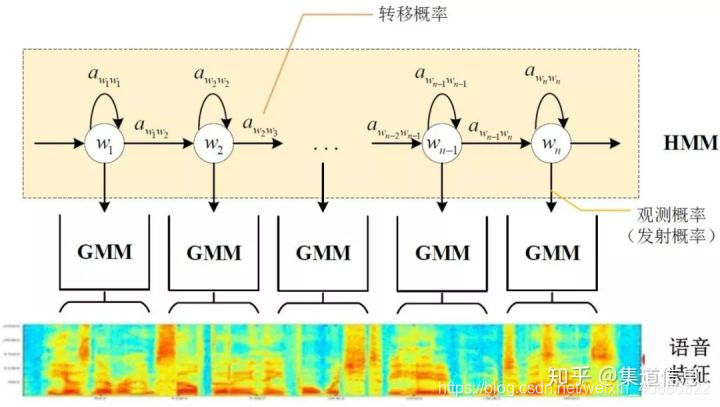
- HMM模型:描述发音动态特性
动态特性:语音信号在时间顺序上的发展演进过程。 - GMM模型:描述短时静态特性。
静态特性:语音信号在某个短时平稳状态(对应HMM模型的一个状态)下的分布规律。 - 一段语音的生成过程:
- HMM模型把发音过程抽象为一个状态序列。从初始状态一步步转移到结束状态,每次转移对应一个转移概率。
- 在进入某个状态后,以GMM模型为概率分布函数生成属于该状态的所有语音帧。每次语音生成过程都对应一个生成概率。
- 语音信号与模型的匹配程度:
给定一段语音,计算出由该模型生成该语音的概率。
四、N-Gram语言模型
- 作用:描述语言中词与词的搭配规律。
e.g. 3-Gram:
我/吃/水果0.1
我/吃/鱼0.2
… …
五、解码过程
- 解码本质:给定一段语音,在所有可能句子中搜索,找到和该语音最匹配的句子。(考虑两个因素:a. 声学模型对语音信号的生成概率;b. 语言模型给出的词间搭配概率。)
- 一般搜索策略:剪枝搜索
- 语音特征向量依次输入解码器;
- 每接收一个新的语音帧,解码器需要考虑加入一个新的音素或单词(搜索空间扩展);
- 每次扩展后只保留当前匹配度最高的候选句子。
- FST(提高解码效率):将一个输入序列(语音帧序列)映射到输出序列(词序列),并将声学模型和语言模型的概率集成到这一映射过程中。
