人工智能与机器学习
人工智能是计算机科学的一个分支,它企图了解智能的实质,并生产出一种新的能以人类智能相似的方式做出反应的智能机器,该领域的研究包括机器人、语言识别、图像识别、自然语言处理和专家系统等。人工智能从诞生以来,理论和技术日益成熟,应用领域也不断扩大,可以设想,未来人工智能带来的科技产品,将会是人类智慧的“容器”。人工智能可以对人的意识、思维的信息过程的模拟。人工智能不是人的智能,但能像人那样思考、也可能超过人的智能。
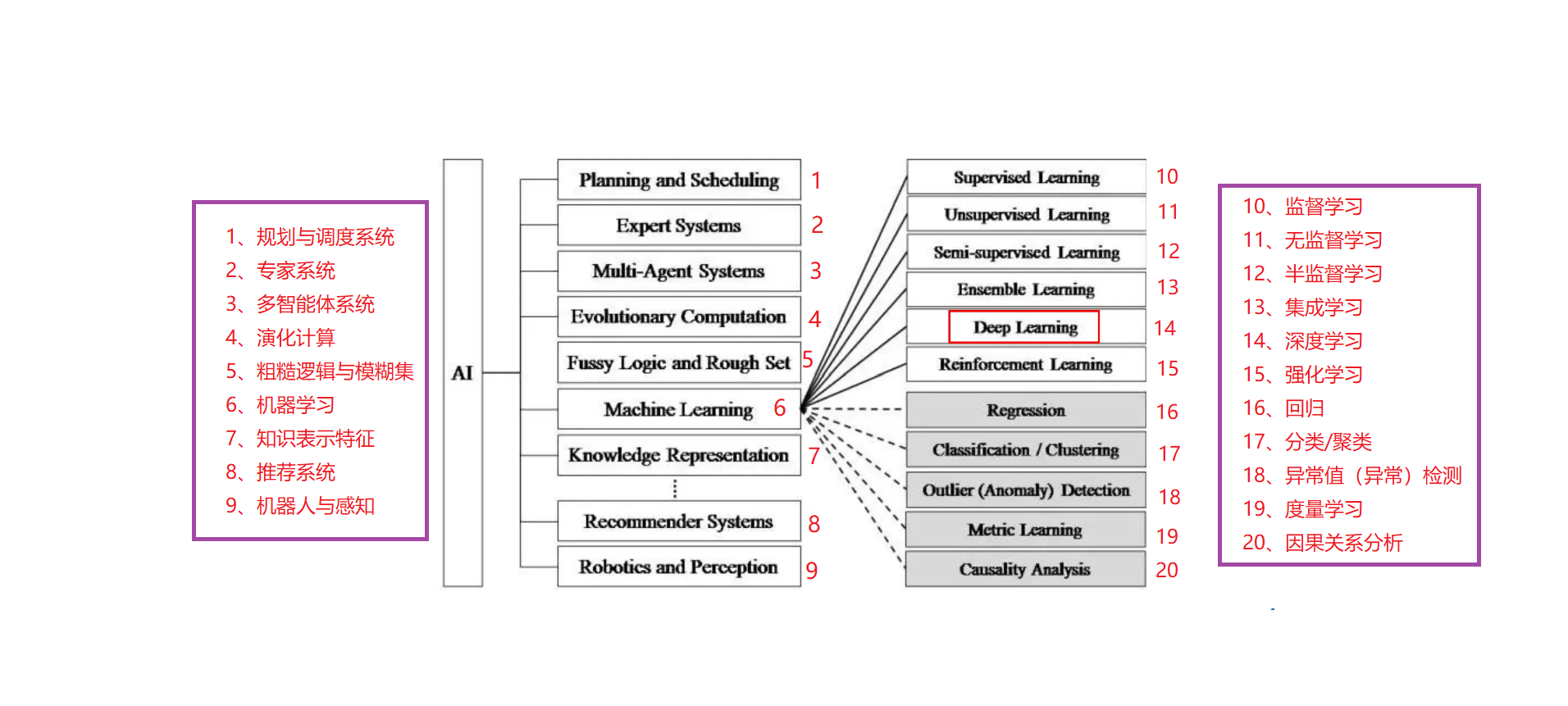
人工智能的发展历程:

逻辑推理:1956年达特茅斯会议之后的十几年里人工智能迎来了第一次高峰,大部分早期研究员都通过人类的经验,基于逻辑或事实归纳出来一些规则,然后通过编写程序来让计算机完成一个任务。
知识工程:70年代,研究者意识到知识对于人工智能系统的重要性。特别是对于一些复杂的任务,需要专家来构建知识库。专家系统可以简单理解为“知识库+推理机”,是一类具有专门知识和经验的计算机智能程序系统。
机器学习:对于人类的很多智能行为比如语言理解、图像理解等,我们很难知道其中的原理,也无法描述这些智能行为背后的“知识”。也就导致了很难通过知识和推理的方式来实现这些行为的智能系统。为了解决这类问题,研究者开始重点转向让计算机从数据中自己学习。
人工智能技术层次递进过程

机器学习的起源: 20世纪50年代的感知机数学模型。
- 发展:20世纪90年代中期以来,机器学习得到迅速发展并逐步取代传统专家系统成为人工智能的主流核心技术,使得人工智能逐步进入机器学习时代。
机器学习与深度学习的区别:机器学习是一种实现人工智能的方法,深度学习是一种实现机器学习的技术。
人工智能领域专有名词
人工智能发展历程
机器学习的定义
机器学习的定义1
机器学习之父: Arthur Samuel 发明了“机器学习”这个词,将其定义为:不需要确定性编程就可以赋予机器某项技能的研究领域。
“机器学习是这样的领域,它赋予计算机学习的能力,(这种学习能力)不是通过**显著式编程**获得的。”
——Arthur Samue
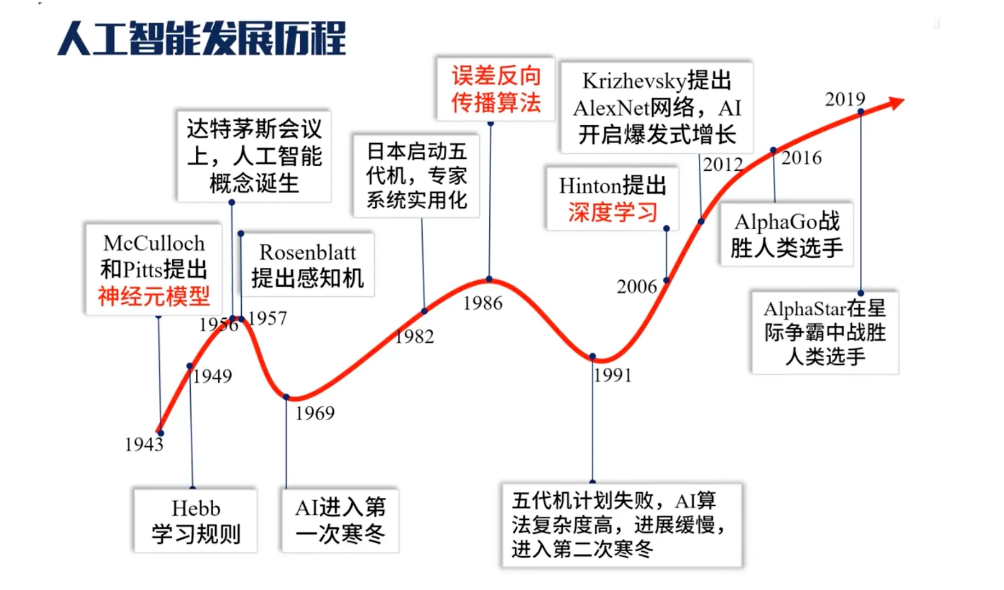
那么,什么是显著式编程呢?它和非显著式编程有什么区别呢?
显著式编程是什么呢?
计算机通过既定逻辑代码执行程序,对于输入层内容输入进入代码逻辑层,通过既定的逻辑顺序得到的结果并返回至输出层。
例如:
机器人去教室外面为我们冲一杯咖啡:
首先我们发指令给这个机器人让他左转,然后走几步。机器人按照预先设定的程序执行每一步指令。
我们让计算机识别菊花与玫瑰花:
我们会事先通过代码告诉计算机:黄色代表菊花,红色代表玫瑰花。那么,计算机识别到黄色就表示菊花,识别到红色就表示玫瑰花。
由此我们可以得出:显著式编程需要我们帮助程序预先了解好执行环境,并让其根据原先既定的逻辑一步步执行下去。
非显著性编程是什么呢?
计算机通过数据、经验自动的学习归纳,完成人类交给的任务。
在执行中,程序往往有一个“收益函数”与"激活函数"对一个当前发生事件进行权重分析并做出下一步行为执行的决策。
以上面的例子为例:
当机器人帮我们去冲咖啡:
人类规定机器人可以采取一系列行为,规定机器人在特定的环境下做这些行为所带来的收益称为 “ 收益函数 ” 。如:机器人自己摔倒,收益函数为负值;机器人自己摔倒,收益函数为负值;机器人自己取到咖啡,收益函数值为正值。
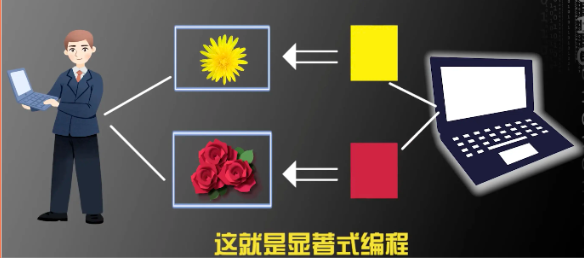
当我们通过计算机识别菊花与玫瑰花:
让计算机自己去总结菊花和玫瑰的区别:花瓣很长、颜色是黄的很可能是菊花,花瓣是圆的颜色是红的很可能是玫瑰花,即计算机可以通过大量的图片,总结出菊花是黄色,玫瑰是红色。
这个规律形成过程中。我们事先并不约束计算机必须总结出什么规律,而是让计算机自己挑出最能区分菊花和玫瑰的一些规律。
由此,在识别图像时,当程序看到一个黄色的,计算机基于菊花的收益函数为正值,且观察到花瓣是长的,收益函数同样为正值,得到此刻的收益值达到激活函数的菊花权重要求,可以推导出得到该花瓣为菊花。
所以在非显著性编程中,我们规定了行为和收益函数后,让计算机自己去找最大化收益函数的行为。计算机采用随机化的行为,只要我们的程序编得足够好,计算机是可能找到一个最大化收益函数的行为模式,并通过“激活函数”作为某个行为的执行条件。
两种编程方式的对比
可以看到,非显著式的编程可以让计算机通过数据、经验自动的学习来完成我们交给的任务。
机器学习关注的就是这种非显著式的编程。
机器学习的定义2
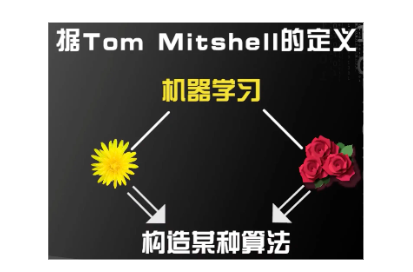
1998年 Tom Mitshell在他的书《Machine Learning》中的定义:
“A computer program is said to learn from experience Ewith respect to some task T and some performance measure P, if its performance on T, as measured by P, improves with experience E. ”
“一个计算机程序被称为可以学习,是指它能够针对杲个任务T和某个性能指标P,从经验E中学习。这种学习的特点是,它在T上的被P所衡量的性能,会随着经验E的增加而提高。”
——Tom Mitshell 《Machine Learning》
如何表述这个概念呢?我们将其上述提到的计算机识别玫瑰花与菊花的程序来划定Tom Mitshell提到的任务T和经验E和性能指标P。其中:
-
任务T (Task):编写计算机程序识别,菊花和玫瑰;
-
经验E (Experience):列举一大椎菊花和玫瑰的图片(数据集);
-
性能指标 P(Performance Measure):计算机的测试集验证结果与在运行的规定时间内识别正确的概率。这是针对任务T与经验E设计的机器学习算法,通过该算法可以得到经验E的知识推出符合任务T的最佳拟合模型,据经验E来提高性能指标P的过程(典型的最优化问题)。性能则体现在现有的模型对新数据的处理能力(准确率 Performance Measure)
针对不同的任务T所设计的机器学习算法会有不同。
测试集:计算机在训练完模型后会划定一定样本作为测试集,基于已完成的模型将其用作数据集中的图像识别,验证图像模型在该测试集中测试成功的概率,即为测试集验证结果,[自己出试卷自己考自己,看看自己会对几道题]
所以由Tom Mitshell的定义可以得出,机器学习 是 通过构造针对于任务T与经验E设计,得到的一个符合最佳拟合度的性能指标P的数据模型。
同时,针对于任务E与经验E设计的机器学习算法中,该算法的特点是随着经验E的数量越来越多,性能指标P也会越来越高(就像学习只会越学越聪明,这过程可能会出现数据波动,因为学了可能也会忘,但只需要反复训练还是会不断提升)。
Tom Mitshell提出的定义同样基于非显著式编程,显著式编程一开始就定死了程序的输入和输出。识别率不会随着样本数量的增加而变化。
那么我们现在再来尝试介绍一下机器人冲咖啡的过程的任务T、经验E和性能指标P的设计概念:
任务T:设计程序让机器人冲咖啡
经验E:机器人多次尝试的行为和这些行为产生的结果在规定时间内成功
性能测度P:冲好咖啡的次数
小结
通过前面的两个定义的介绍,我们了解到数学在现代机器学习中占有重要的作用。
机器学习是人工智能的一个重要分支,是实现智能化的关键
经典定义:是一种通过经验来改善计算机系统自身(模型)的性能的方式。现代的机器学习的方式也主要是参考定义2设计的。
现有的机器学习框架的主要是基于以下几点进行设计:
- **经验:**在计算机系统中,即为数据(集)。对应于历史数据,如互联网数据、科学实验数据等。
- **系统:**对应于数据模型,如决策树、支持向量机等。
- **性能:**则是模型对新数据的处理能力,如分类和预测性能等。
- **主要目标:**数据的智能分析与建模。预测未知、理解系统
人工神经网络及其发展
正式开始介绍神经网络之前,我们先来看几个简单的数学问题:
- 3 是正数还是负数?
- (1,1)属于坐标轴上的哪个象限?
在充分调用各种感官和90义务教育的知识积累后,我们回答这些问题似乎太容易, 容易到让我们感觉这些问题本身都没有太大意义。
可一旦想要理解人类大脑通过何种机制解决这些问题:视觉神经在这些问题中是如何起作用?信息如何在神经原接流转?
如何让计算机也具备回答这些问题的能力,事情就变得不那么简单了。
神经网络是一种仿生模型,即模仿人类的神经网络实现对事件进行处理分析,得到一个最佳的问题的解决方案。
因此我们先来了解一下生物神经源的结构与工作原理
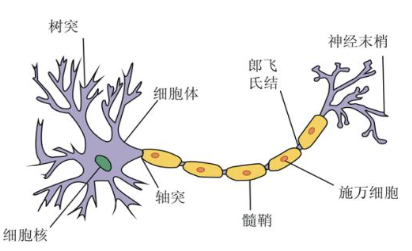
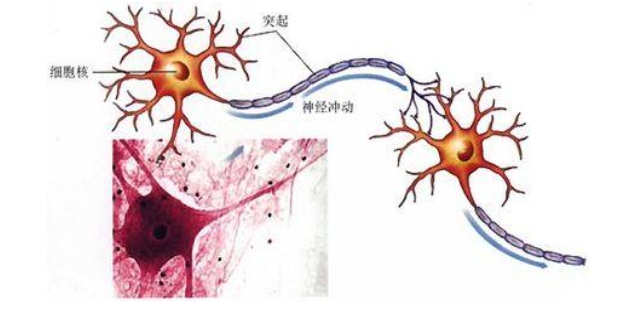
一个神经源是一个可以接收发射脉冲信号的细胞,在细胞体核心之外有树突和轴突;
树突接收其他神经元的脉冲信号,而轴突将神经元的输出脉冲传递给其他神经源;一个神经源传递给不同神经元的输出是相同的,并且在突出部分发生信息的交换传递中无数个生物神经元的组合交互就形成了生物神经网络,使人具备了处理复杂信息的能力

人工神经网络概念
那么,人工神经网络也试图模仿生物神经网络的工作原理对应的神经源形式。人工神经网络(Aritificial Neural Network,ANN)是理论化的人脑神经网络的数学模型,是基于模仿大脑神经网络结构和功能而建立的一种信息处理系统。它实际上是一个由大量简单元件相互连接而成的复杂网络,具有高度的非线性,能够进行复杂的逻辑操作和非线性关系实现的系统。
人工神经网络也被称为“神经网络”或“人工神经系统”。通常缩写人工神经网络并将它们称为“ANN”或简称为“NN”。
对于一个被视为神经网络的系统,它必须包含一个带标签的图结构,图中的每个节点都执行一些简单的计算。从图论中,我们知道图由一组节点(即顶点)和一组将节点对连接在一起的连接(即边)组成。
在下图中,我们可以看到此类 NN 图的示例。
一个简单的神经网络架构。输入呈现给网络。每个连接通过网络中的两个隐藏层承载一个信号。最后一个函数计算输出类标签。
每个节点执行一个简单的计算。然后,每个连接将信号(即计算的输出)从一个节点传送到另一个节点,用权重标记,指示信号被放大或减弱的程度。一些连接具有放大信号的正权重,表明信号在进行分类时非常重要。其他的具有*负权重,*降低了信号的强度,从而指定节点的输出在最终分类中不太重要。我们称这样的系统为人工神经网络
人工神经网络的构造原则
- 由一定数量的基本单元分层联接构成;
- 每个单元的输入、输出信号以及综合处理内容比较简单;
- 网络的学习和知识存储体现在各单元之间的联接强度上。

人工神经网络应用领域与发展历史
语音识别:Siri的智能语音识别;
自动驾驶:当今人工智能主流研究方向;
搜索引擎优化、推荐算法、语言翻译:百度、谷歌、推荐算法;
人机博弈算法:AlphaGo围棋算法;
智能家居、安放:人脸识别、智能化监控设备。
从机器学习角度看人工智能的发展历史
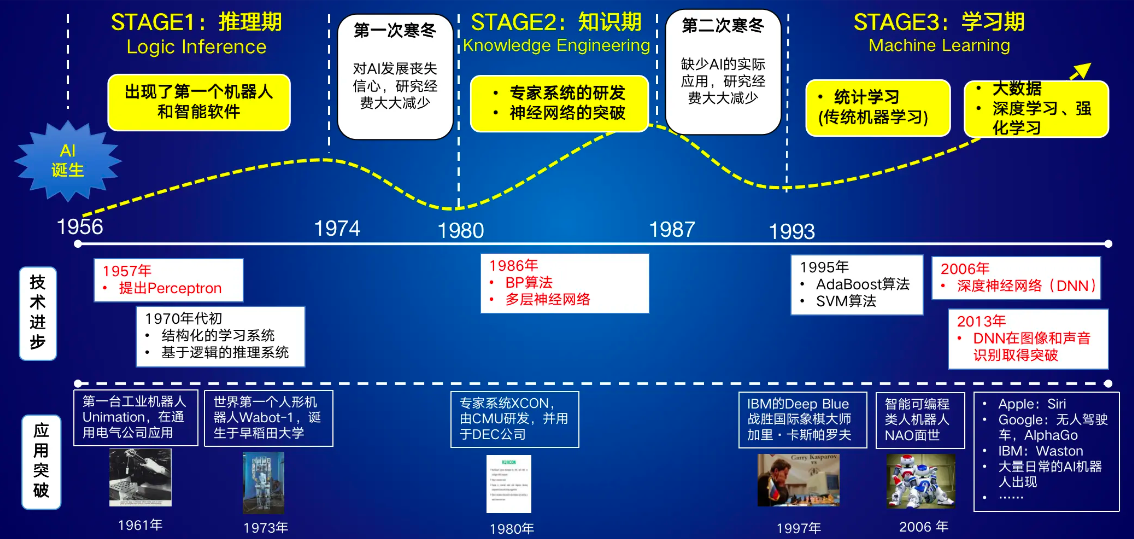
机器学习中的三大流派
-
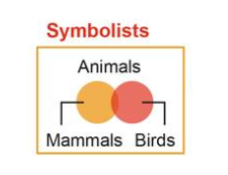
符号主义(Symbolists)
-
认知即计算,通过对符号的演绎和逆演绎进行结果预测
-
代表算法:逆演绎算法(Inverse deduction)
-
代表应用:知识图谱
-
-
联结主义(Connectionist)
-
对大脑进行仿真
-
代表算法:反向传播算法(Backpropagation)、深度学习(Deep learning)
-
代表应用:机器视觉、语音识别

-
-
行为主义(Analogizer)
-
新l旧知识间的相似性
-
代表算法:核机器(Kernel machines)、近邻算法(Nearest Neightor)
-
代表应用:Netflix推荐系统

-
同时还划分两个研究学派:
-
人工智能仿生学派:
- 人工智能模拟的是人类大脑对于世界的认识,研究大脑认知机理总结大脑处理信息的方式,即为实现人工智能的先决条件
-
人工智能的数理学派:
- 在现在以及可预见的未来,我们无法完全了解人脑的认知机理,计算机与人脑具有截然不同的物理属性和体系结构。
神经网络的发展概述
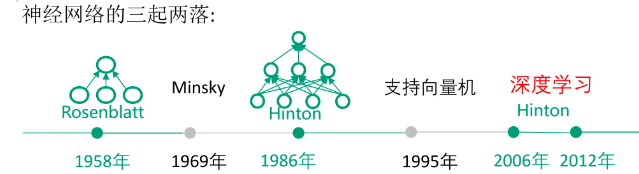

深度学习有悠久的发展历史,但在2010年后才逐渐成熟。
深度学习的三驾马车
现代深度学习的顶级专家:
- 吴恩达:2011年,吴恩达在谷歌成立了“Google Brain”项目,这个项目利用谷歌的分布式计算框架计算和学习大规模人工神经网络。这个项目重要研究成果是,在16000个CPU核心上利用深度学习算法学习到的10亿参数的神经网络,能够在没有任何先验知识的情况下,仅仅通过观看无标注的YouTube的视频学习到识别高级别的概念。
- 2008年,吴恩达入选“the MIT Technology Review TR35”,即《麻省理工科技创业》杂志评选出的科技创新35俊杰,入选者是35岁以下的35个世界上最顶级的创新者之一
- “计算机和思想奖”的获得者。
- 2013年,吴恩达入选《时代》杂志年度全球最有影响力100人,成为16位科技界代表之一。、
- 李飞飞:ImageNet和ImageNet Challenge的发明者,为深度学习和AI的最新发展做出了贡献。除了她的技术贡献外,她还是倡导STEM(科学、技术、工程和数学教育)和AI(人工智能)多样性的领导者。
- lan Goodfellow:因提出了生成对抗网络(GANs)而闻名,他被誉为“GANs之父”,甚至被推举为人工智能领域的顶级专家。


深度学习主导了第三次人工智能热潮,得益于ABC三点:
- Algorithm(算法):深层神经网络训练算法日趋成熟,识别精度越来越高;
- Big data(大数据):有足够多的大数据来做神经网络的训练;
- Computing(算力):深度学习处理器芯片的计算能力较强。
神经网络的发展历程
1943年:模型M-P神经元模型的提出
McCulloch-Pitts神经元模型
MP模型作为人工神经网络的起源,开创了人工神经网络的新时代,也奠定了神经网络模型的基础。
-
美国心理学家McCulloch和数学家Pitts,提出的模拟人类神经元网络进行信息处理的数学模型

-
神经元的特点:多输入单输出;突触(传递神经冲动的地方)兼有兴奋和抑制两种性能;能时间加权和空间加权;可产生脉冲;脉冲进行传递;非线性
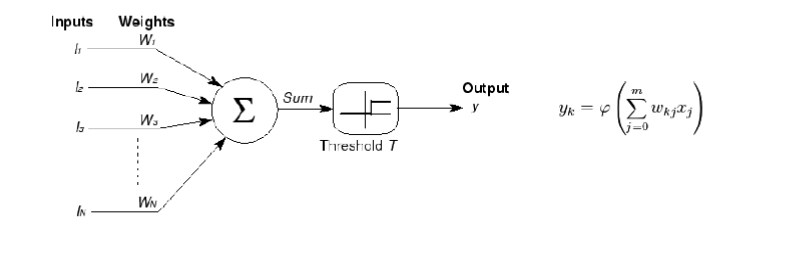
-
简单的线性加权的方式来模拟这个过程,其中l为输入,W为权重,加权的和经过一个阈值函数后作为输出。
1949年:Hebb假设
在1949年出版的《行为的组织》中,赫布(Hebb)提出了其神经心理学理论。

Hebb假设:当细胞A的轴突到细胞B的距离近到足够激励它,且反复地或持续地刺激B,那么在这两个细胞或一个细胞中将会发生某种增长过程或代谢反应,增加A对细胞B的刺激效果;
赫布(Hebb)规则与“条件反射”机理一致,为以后的神经网络学习算法奠定了基础,具有重大的历史意义。
1958年:Rosenblatt感知机(Perceptron)算法
1958年,一位心理学家Rosenblatt发明了该感知器,所以被后人取名为**Rosenblatt感知器**。
Rosenblatt第一次将M-P模型用于对输入的多维数据进行二分类,使用梯度下降法从训练样本中自动学习更新权值;
1962年,该方法被证明最终收敛,理论与实践效果引起第一次神经网络的浪潮

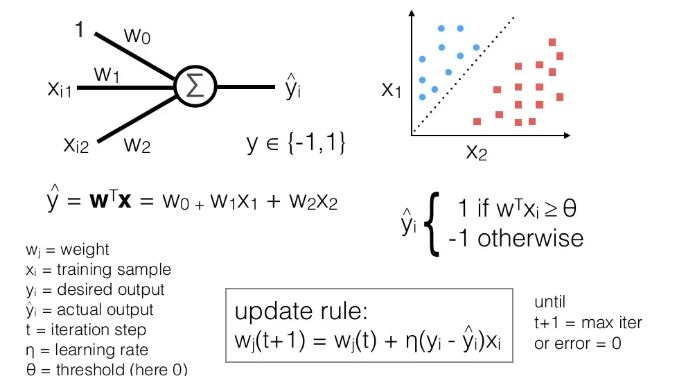
感知器的提出引起了大量科学家对人工神经网络研究的兴趣,对神经网络的发展具有里程碑式的意义。
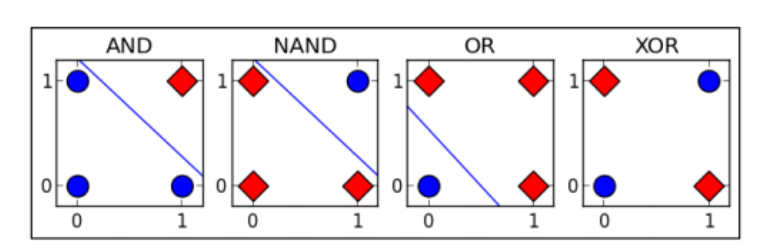
1969年:XOR问题的质疑
1969年,美国数学家及人工智能先驱Minsky和Papert,在其著作中证明了感知器本质上是一种线性模型,无法解决最简单的XOR(亦或)问题,“线性不可分的问题”;
宣判了感知器的死刑,神经网络的研究也陷入了10余年的停滞(进入第一个寒冬),人们对神经网络的研究也停滞了将近20年。

1982-1984年:寒冬期的发展阶段
- 真理的果实总是垂青于能够坚持研究的科学家。尽管人工神经网络ANN的研究陷入了前所未有的低谷,但仍有为数不多的学者致力于ANN的研究。
- 1982年,著名物理学家约翰·霍普菲尔德发明了Hopfield神经网络。Hopfield神经网络是一种结合存储系统和二元系统的循环神经网络。Hopfield网络也可以模拟人类的记忆,根据激活函数的选取不同,有连续型和离散型两种,分别用于优化计算和联想记忆。但由于容易陷入局部最小值的缺陷,该算法并未在当时引起很大的轰动。
- 1984年,辛顿与年轻学者谢诺夫斯基等合作提出了大规模并行网络学习机,并明确提出隐藏单元的概念,这种学习机后来被称为玻尔兹曼机(Boltzmann machine)。他们利用统计物理学的概念和方法,首次提出的多层网络的学习算法,称为玻尔兹曼机模型。

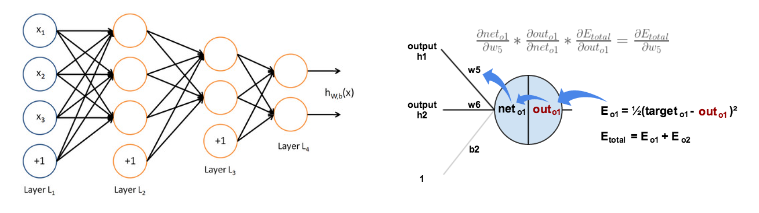
1986-1989年:MLP和BP算法的提出
- 1986年,Rumelhart,Hilton等人发明了适用于多层感知器(Multi-Layer Perceptron,MLP)和误差反向传播算法(Back Propagation,BP)算法,并采用Sigmoid函数进行非线性映射,有效解决了非线性分类和学习的问题。BP算法引起了神经网络的第二次热潮
- 1989年,Robert Hecht-Nielsen证明了MLP的万能逼近定理,即对于任何闭区间内的一个连续函数f,都可以用含有一个隐含层的BP网络来逼近该定理的发现极大的鼓舞了神经网络的研究人员。
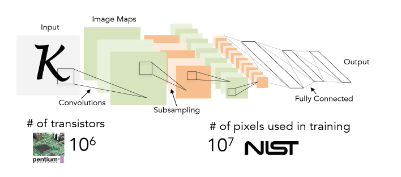
1989年,LeCun发明了卷积神经网络-LeNet,并将其用于数字识别,且取得了较好的成绩,不过当时并没有引起足够的注意。
在1989年以后由于没有特别突出的方法被提出,且NN一直缺少相应的严格的数学理论支持,神经网络热潮退去。
第二次寒冬来自于1991年,BP算法被指出存在梯度消失问题,即在误差梯度后向传递的过程中,后层梯度以乘性方式叠加到前层,由于Sigmoid函数的饱和特性,后层梯度本来就小,误差梯度传到前层时几乎为0,因此无法对前层进行有效的学习,该发现对此时的NN发展雪上加霜,该问题直接阻碍了深度学习的进一步发展。。
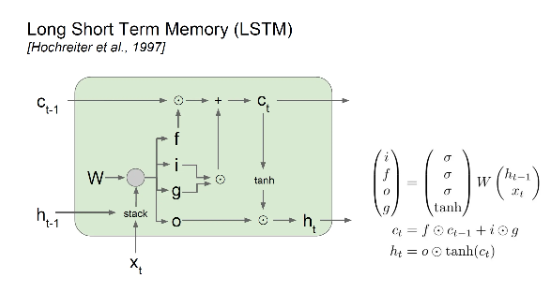
1997年,LSTM模型被发明,尽管该模型在序列建模上的特性非常突出,但由于正处于NN的下坡期,也没有引起足够的重视。

1986-2006年:统计学习占领主流
- 1986年,ID3,ID4,CART等改进的决策树方法相继出现,到目前仍然是非常常用的一种机器学习方法。该方法也是符号学习方法的代表
- 1995年,SVM支持向量机算法被统计学家V.Vapnik和C.Cortes发明了SVM提出。该方法的特点有两个:由非常完美的数学理论推导而来(统计学与凸优化等),符合人的直观感受(最大间隔)。不过,最重要的还是该方法在线性分类的问题上取得了当时最好的成绩、
- 1997年,AdaBoost被提出,该方法是PAC(Probably Approximately Correct)理论在机器学习实践上的代表,也催生了集成方法这一类。该方法通过一系列的弱分类器集成,达到强分类器的效果。
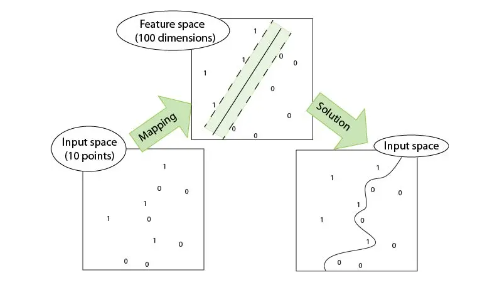
- 2000年,Kernel SVM被提出,核化的SVM通过一种巧妙的方式将原空间线性不可分的问题,通过Kernel映射成高维空间的线性可分问题,成功解决了非线性分类的问题,且分类效果非常好。至此也更加终结了ANN时代。
- 2001年,随机森林被提出,这是集成方法的另一代表,该方法的理论扎实,比AdaBoost更好的抑制过拟合问题,实际效果也非常不错。
- 2001年,一种新的统一框架-图模型被提出,该方法试图统一机器学习混乱的方法,如朴素贝叶斯,SVM,隐马尔可夫模型等,为各种学习方法提供一个统一的描述框架
支持向量机算法诞生(SVM算法)等各种浅层机器学习模型被提出,SVM也是一种有监督的学习模型,应用于模式识别,分类以及回归分析等。支持向量机以统计学为基础,和神经网络有明显的差异,支持向量机等算法的提出再次阻碍了深度学习的发展。
1995年:统计学习-SVM
- V.Vapnik和C.Cortes两人发明了SVM。
- 它是一种二类分类模型,其基本模型定义为特征空间上的间隔最大的线性分类器,即支持向量机的学习策略便是间隔最大化,最终可转化为一个凸二次规划问题的求解。

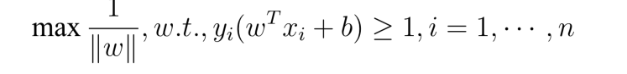
统计学习的优点
-
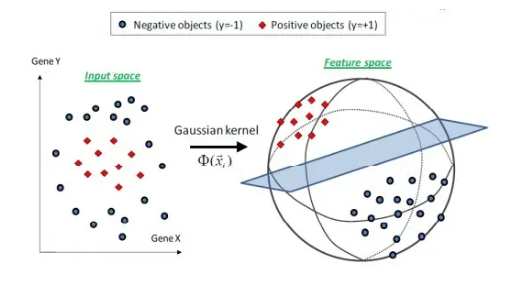
SVM利用内积核函数代替向高维空间的非线性映射;
-
SVM是一种有坚实理论基础的新颖的小样本学习方法;
-
SVM的最终决策函数只由少数的支持向量所确定,计算的复杂性取决于支持向量的数目,而非样本空间的维数,避免“维数灾难”;
-
少数支持向量决策,简单高效,鲁棒性好(稳定性好)。
-
G.Hinton等人提出了Deep Belief Network,它是一种生成模型,通过训练其神经元间的权重,使得整个神经网络按照最大概率来生成训练数据。
-
使用非监督贪婪逐层方法去预训练获得权值,不用靠经验提取数据特征,经过底层网络自动提炼
2006-2017年:崛起阶段
- **2006年,杰弗里·辛顿以及他的学生鲁斯兰·萨拉赫丁诺夫正式提出了深度学习的概念。**他们在世界顶级学术期刊《Science》发表的一篇文章中详细的给出了“梯度消失”问题的解决方案——通过无监督的学习方法逐层训练算法,再使用有监督的反向传播算法进行调优。该深度学习方法的提出,立即在学术圈引起了巨大的反响,斯坦福大学、纽约大学、加拿大蒙特利尔大学等成为研究深度学习的重镇,至此开启了深度学习在学术界和工业界的浪潮。
- 2011年,ReLU激活函数被提出,该激活函数能够有效的抑制梯度消失问题。2011年以来,微软首次将DL应用在语音识别上,取得了重大突破。微软研究院和Google的语音识别研究人员先后采用深度神经网络DNN技术降低语音识别错误率至20%~30%,是语音识别领域十多年来最大的突破性进展。

- 2012年,DNN技术在图像识别领域取得惊人的效果,在ImageNet评测上将错误率从26%降低到15%。在这一年,DNN还被应用于制药公司的DrugeActivity预测问题,并获得世界最好成绩。2012年,在著名的ImageNet图像识别大赛中,杰弗里·辛顿课题组为了证明深度学习的潜力,**首次参加ImageNet图像识别比赛,其通过构建的CNN网络AlexNet一举夺得冠军,且碾压第二名(SVM方法)的分类性能。**也正是由于该比赛,CNN吸引到了众多研究者的注意。深度学习算法在世界大赛的脱颖而出,也再一次吸引了学术界和工业界对于深度学习领域的注意。
- 随着深度学习技术的不断进步以及数据处理能力的不断提升,2014年,Facebook基于深度学习技术的DeepFace项目,在人脸识别方面的准确率已经能达到97%以上,跟人类识别的准确率几乎没有差别。这样的结果也再一次证明了深度学习算法在图像识别方面的一骑绝尘。
- **2016年3月,由谷歌(Google)旗下DeepMind公司开发的AlphaGo(基于深度学习算法)**与围棋世界冠军、职业九段棋手李世石进行围棋人机大战,以4比1的总比分获胜;2016年末2017年初,该程序在中国棋类网站上以“大师”(Master)为注册帐号与中日韩数十位围棋高手进行快棋对决,连续60局无一败绩。
- 2017年,基于强化学习算法的AlphaGo升级版AlphaGo Zero横空出世。其采用“从零开始”、“无师自通”的学习模式,以100:0的比分轻而易举打败了之前的AlphaGo。此外在这一年,深度学习的相关算法在医疗、金融、艺术、无人驾驶等多个领域均取得了显著的成果。所以,也有专家把2017年看作是深度学习甚至是人工智能发展最为突飞猛进的一年。

ANN(神经网络)的未来
forever Or dispear?
-
进入21世纪,纵观机器学习发展历程,研究热点可以简单总结为2000-2006年的流形学习、2006年-2011年的稀疏学习、2012年至今的深度学习。未来哪种机器学习算法会成为热点呢?
-
吴恩达曾表示,“在继深度学习之后,迁移学习将引领下一波机器学习技术”。但最终机器学习的下一个热点是什么,谁又能说得准呢。
迁移学习:迁移学习是一种机器学习的方法,指的是一个预训练的模型被重新用在另一个任务中。
贝尔实验室的5年之约
1995年里,来自贝尔实验室的两个有趣的赌约。对赌双方分别是:前贝尔实验室负责人Larry Jackel,和支持向量机(Support Vector Machine)的创建者之一Vladimir Vapnik。
第一个赌约: Larry Jackel认为,最迟到2000年,我们就会有一个关于神经网络为什么有效的成熟理论解释。
第二个赌约:Vladimir Vapnik则认为,到了2000年,大家不会再使用神经网络的结构。(毕竟人家是支持向量机的创建者之一,自然更加认可支持向量机)
而对赌结果呢?——两个人都输了。我们至今仍旧没有一个成熟的解释,可以告诉我们为什么神经网络的使用效果这么好;与此同时,我们也仍在使用神经网络架构。
对人工智能的思考
总而言之,在人工智能的旗帜下,不同的人实际上在干不同的事:有构建脑模型的,有模拟人类行为的,有开拓计算机应用领域的,有设计新算法的,有总结思维规律的。虽然这些研究都有价值且有联系,但它们不可以彼此替代,而把它们混为一谈则容易导致思想混乱。
专用人工智能确实取得突破性的进展,但另一方面是通用人工智能的研究与应用依然任重道远,要在通用人工智能方面取得巨大突破还需要尽洪荒之力。
目前人工智能是有智能没智慧,有智商没情商,会计算不会算计,有专才无通才。
——谭铁牛《关于人工智能发展的思考》. 2016中国人工智能大会(CCAl 2016)
写在后面的话
如果你觉得本系列文章对你用帮助,别忘了点赞关注作者哦!你的鼓励是我继续创作分享加更的动力!愿我们都能一起在顶峰相见。欢迎来到作者的公众号:“01编程小屋” 做客哦!关注小屋,学习编程不迷路!