变压器模型及其关键组件的概述。
一、介绍
在这篇博文中,我将讨论本世纪最具革命性的论文“注意力是你所需要的一切”(Vaswani et al.)。首先,我将介绍自我注意机制,然后介绍变形金刚的架构细节。在之前的博客文章《从Seq2Seq到注意力:革命性的序列建模》中,我讨论了注意力机制和Bahdanau注意力的起源。在本博客中,我将以之前的信息为基础。因此,如果您还没有查看上一篇文章,请去查看。Bahdanau注意力模型使用2个RNN和注意力机制为编码器的隐藏状态分配权重。在“注意力是你所需要的一切”论文中,作者已经摆脱了所有的RNN。他们引入了一种新的架构,它不使用递归,而是完全依赖于自我注意机制。让我解释一下什么是自我注意机制:
二、自我注意机制
自我注意机制使模型能够通过同时关注所有位置来捕获序列中不同位置之间的依赖关系。在上一篇博客中,我们讨论了使用查询和键值对来计算注意力分数。注意力分数决定了每个键值对对给定查询的重要性或相关性。自我注意扩展了这种机制,使其在单个序列内运行,而无需外部输入。

在上图中,您可以看到自我注意机制。让我从左到右解释一下这个数字。首先,我们有一个输入 x。我们将此输入与可训练的权重矩阵(Wq,Wk,Wv)相乘。作为输出,我们得到查询、键和值矩阵。我们使用查询和键矩阵来查找它们的相似性。上图仅取点积,但在变压器架构中我们也对其进行缩放。此点积的输出是注意力权重 (a)。以同样的方式,我们将计算所有输入 x(t) 的注意力权重。计算完所有注意力权重后,将应用 softmax 函数对点积进行归一化,从而生成总和为 1 的注意力权重。从 softmax 运算获得的注意力权重用于计算值向量的加权和。此加权总和表示输入序列中每个位置的自参与表示。自我注意的优势在于它能够对序列中的局部和全局依赖关系进行建模。它从整个序列中捕获上下文信息,从而更全面地了解不同位置之间的关系。
三、缩放点积
如上一段所述,我们不仅使用点积来查找相关性。但是我们也通过键维数(dk)的平方根的因子来缩放它。这有助于确保查询和键之间的点积对于大型 dk 不会变得太大。如果点积变得太大,则softmax输出将非常小。 为了避免这种情况,我们缩放点积。
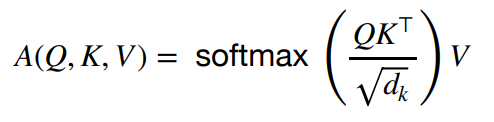
四、多头注意力
多头注意力只是自我注意机制的补充。它允许模型共同关注不同的位置,并同时学习输入序列的多种表示。通过并行执行多组注意力计算,多头注意力捕获了输入序列的不同方面,并增强了模型捕获复杂依赖关系的能力。每个注意力头都有不同的查询、键和值矩阵。
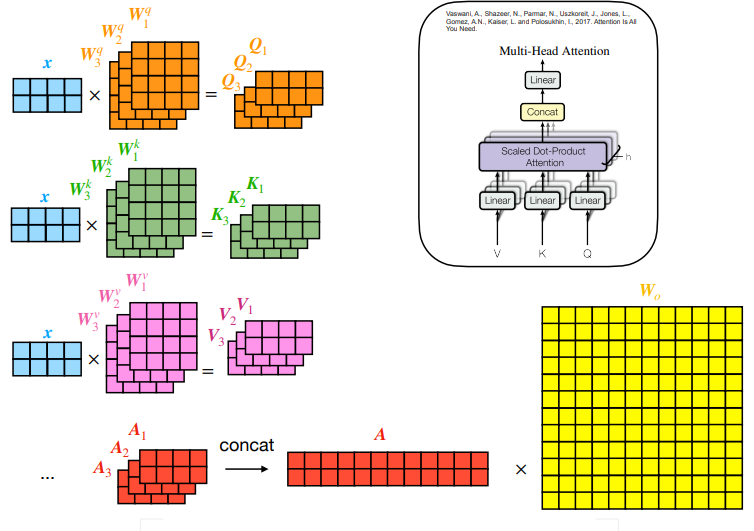
多头注意事项
来自不同注意力头的输出通过线性投影进行组合和转换,从而产生从多个角度整合信息的最终表示。
五、transformer架构
“注意力就是您所需要的一切”一文中介绍的转换器体系结构由几个关键组件组成,这些组件协同工作以实现有效的序列建模。主要组件是编码器、解码器、位置编码、残差连接、层归一化、多头注意力块、屏蔽多头注意力块和前馈网络。
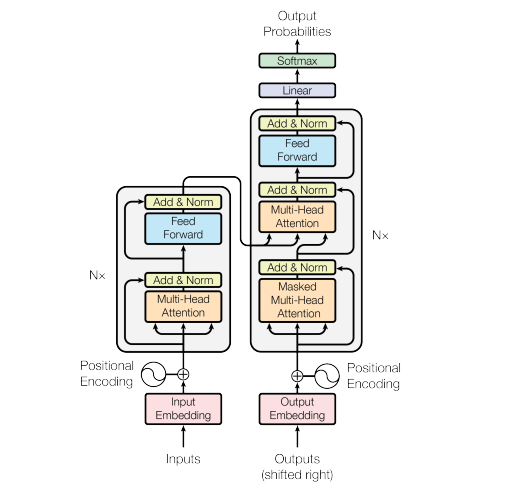
变压器架构
我们已经讨论了多头注意力块。蒙面多头注意力与此相同,但有一个变化。我们屏蔽后续序列元素。即,只允许参加当前职位之前和包括当前职位的职位。这是通过将那些的 softmax 值设置为负无穷大来实现的。
编码器:变压器架构中的左侧部分是编码器部分。它由一个多头注意力块、一个前馈网络、多个残差连接和层归一化组成。它接受输入序列的嵌入以及添加到其中的位置编码。在原始论文中,他们使用了6个编码器。
解码器:转换器架构中的正确部分是解码器部分。它由一个屏蔽的多头注意力块、一个简单的多头注意力块、一个前馈网络以及多个残差连接和层归一化组成。它接受输出序列的嵌入以及添加到其中的位置编码。在原始论文中,他们使用了6个解码器。
残差连接和层规范化: 残差连接(也称为跳过连接)是绕过神经网络中的一个或多个层的直接连接。在转换器架构的上下文中,残差连接用于将子层的输出连接到其输入,允许原始输入流过层不变层归一化是一种用于规范化神经网络层内的激活的技术。它旨在通过减少内部协变量偏移来提高训练稳定性和泛化,内部协变量偏移是指网络学习时激活分布的变化。层归一化独立应用于每个神经元或特征,在小批量维度上规范化其值。
前馈网络:在变压器架构中,前馈网络是一个组件,它在每个位置上独立运行,并且在每层内以相同方式运行。它负责转换自注意机制和位置前馈子层中输入序列的表示。在第一次变换之后,使用Relu激活函数将两个线性变换应用于自注意力机制的输出。
位置编码: 输入和输出序列的嵌入与位置编码连接。这些编码注入有关序列中元素的相对位置的信息。

用于位置编码的正弦和余弦函数
学习的位置嵌入和通过正弦和余弦函数嵌入在语言任务中产生几乎相等的结果。
我将在另一篇博客文章中介绍评估指标、训练方法、推理时的解码方法和其他次要细节,其中我将从头开始实现 Transformer 架构。
六、结语
总之,“注意力是你所需要的一切”论文介绍了一种称为变压器的开创性架构,它彻底改变了序列建模领域。这种架构在很大程度上依赖于自我注意的概念,允许它捕获输入序列中不同位置之间的依赖关系。Transformer的注意力机制使其能够对长期依赖关系进行建模,处理可变长度的输入,并在各种自然语言处理任务中实现最先进的性能。本文中介绍的体系结构已被许多语言模型使用,我将在以后的博客中讨论这些模型。在下一篇博文中,我将详细介绍自回归模型,如 GPT、GPT-2 和 GPT-3。
感谢您的阅读!
参考和引用