1、声纹识别embedding向量提取
参考:
https://aistudio.baidu.com/aistudio/projectdetail/4353348
https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/speaker_verification/README_cn.md
https://aistudio.baidu.com/aistudio/projectdetail/4353348
-
注意
1)安装paddlespeech,参考:
https://blog.csdn.net/weixin_42357472/article/details/131269539?spm=1001.2014.3001.55022)运行代码过程中下载模型报错RuntimeError: Download from https://paddlespeech.bj.bcebos.com/vector:
可以自己离线下载下来,根据提示下载链接https://paddlespeech.bj.bcebos.com/vector/voxceleb/sv0_ecapa_tdnn_voxceleb12_ckpt_0_2_0.tar.gz,paddlespeech模型一般放在C:\Users\loong.paddlespeech\models下;注意这边模型目录结构一般是如下,并且tar包也要放在一块才可以

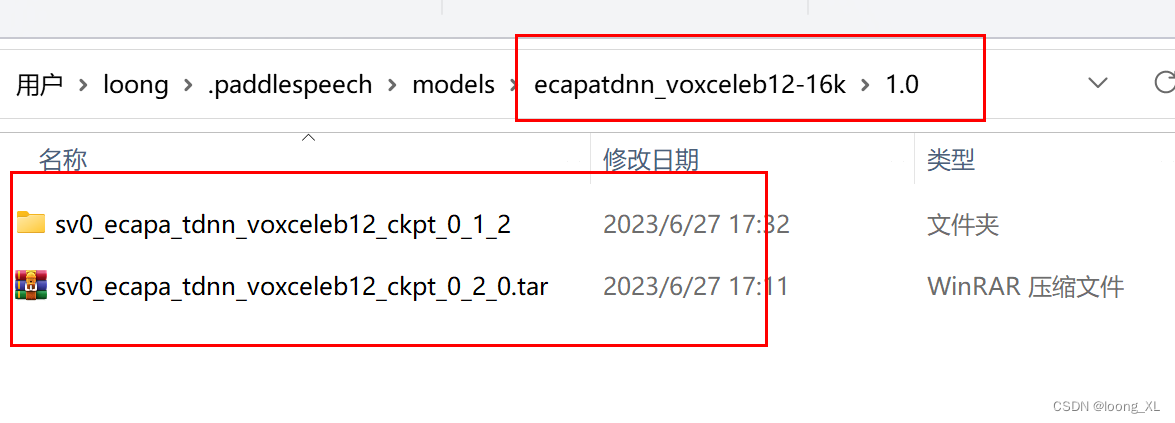
使用
** paddlespeech提取向量维度是192
1)命令行使用:
paddlespeech vector --task spk --input zh.wav
paddlespeech vector --task score --input "./85236145389.wav ./123456789.wav"
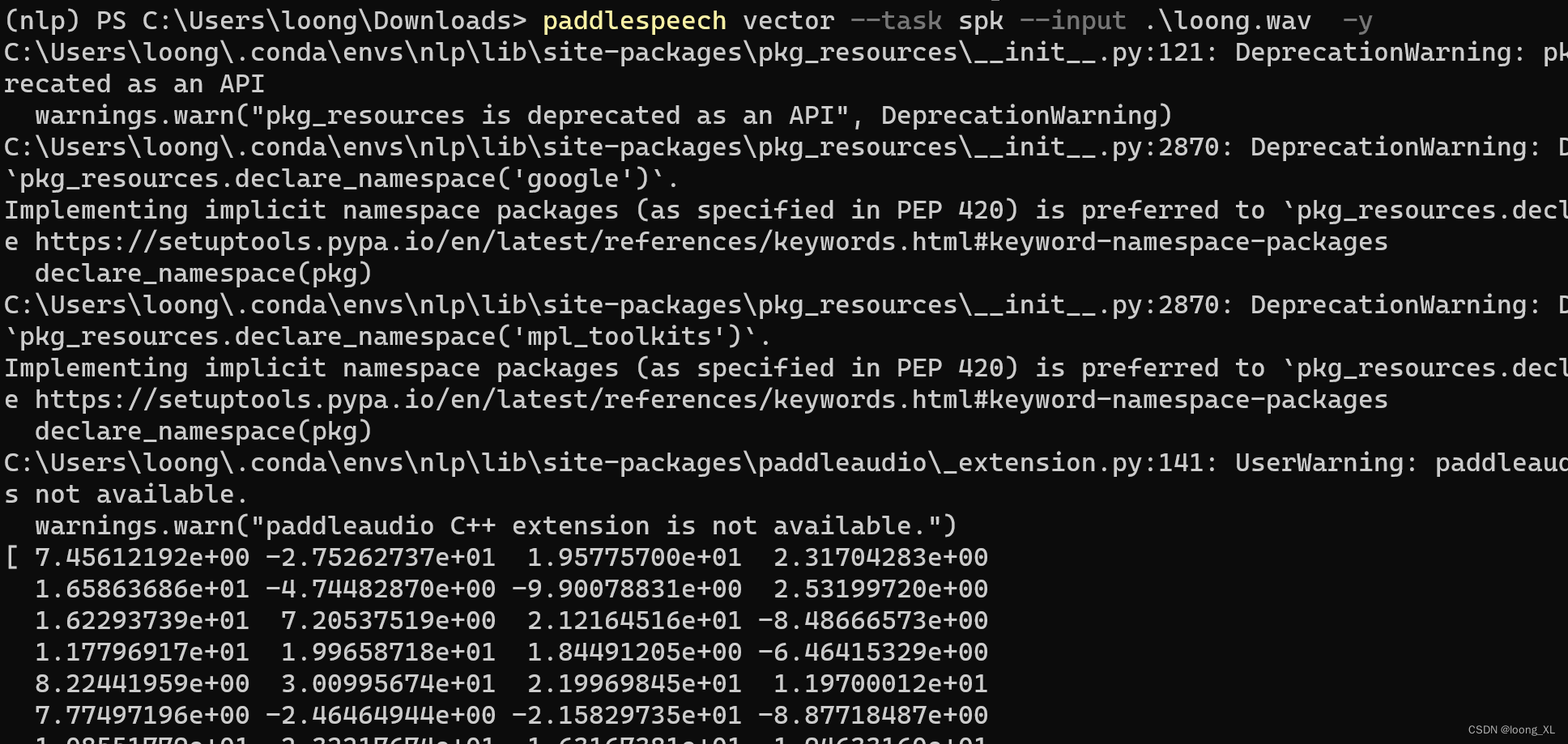
2)向量提取代码使用:
from paddlespeech.cli.vector import VectorExecutor
vec = VectorExecutor()
result = vec(audio_file="zh.wav")
from paddlespeech.cli.vector import VectorExecutor
vector_executor = VectorExecutor()
audio_emb = vector_executor(
model='ecapatdnn_voxceleb12',
sample_rate=16000,
config=None, # Set `config` and `ckpt_path` to None to use pretrained model.
ckpt_path=None,
audio_file='./85236145389.wav',
device=paddle.get_device())
print('Audio embedding Result: \n{}'.format(audio_emb))
3)声纹相似度计算:
import paddle
from paddlespeech.cli.vector import VectorExecutor
vector_executor = VectorExecutor()
audio_emb = vector_executor(
model='ecapatdnn_voxceleb12',
sample_rate=16000,
config=None, # Set `config` and `ckpt_path` to None to use pretrained model.
ckpt_path=None,
audio_file='./85236145389.wav',
device=paddle.get_device())
print(audio_emb.shape)
print('Audio embedding Result: \n{}'.format(audio_emb))
test_emb = vector_executor(
model='ecapatdnn_voxceleb12',
sample_rate=16000,
config=None, # Set `config` and `ckpt_path` to None to use pretrained model.
ckpt_path=None,
audio_file='./123456789.wav',
device=paddle.get_device())
print(test_emb.shape)
print('Test embedding Result: \n{}'.format(test_emb))
# score range [0, 1]
score = vector_executor.get_embeddings_score(audio_emb, test_emb)
print(f"Eembeddings Score: {score}")
底层相似度计算用的CosineSimilarity,结果越大越好
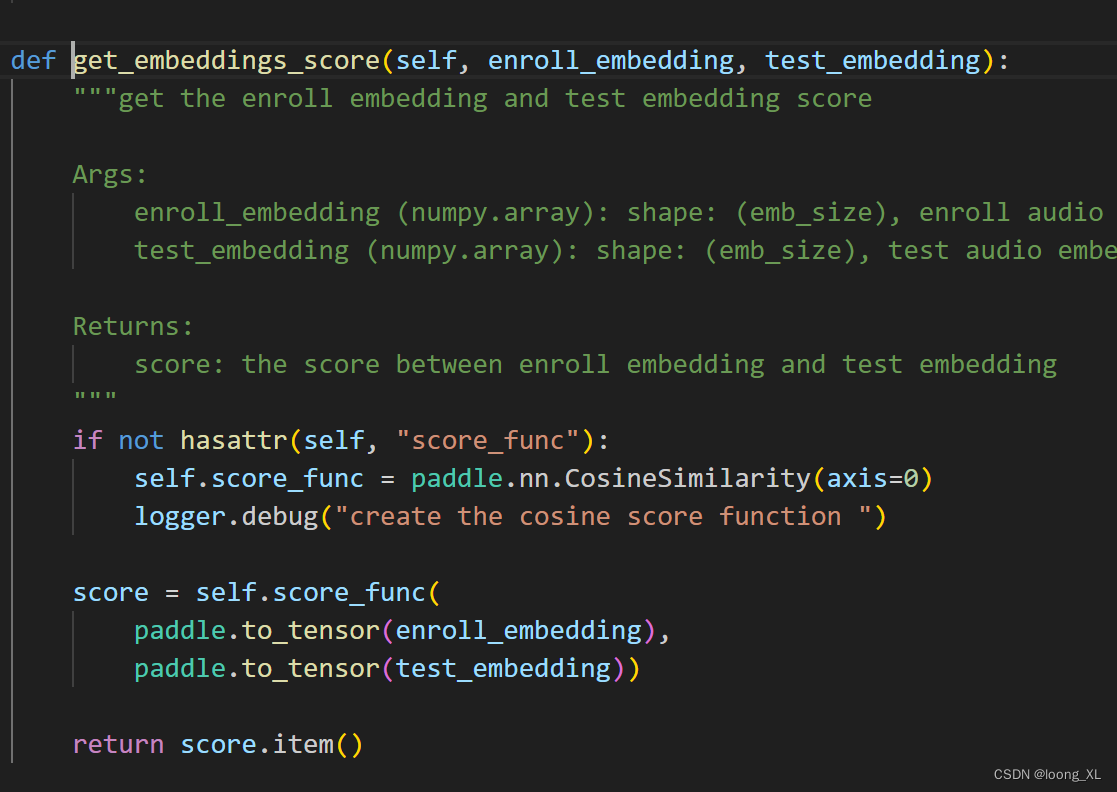
2、TTS文本合成语音
参考:
https://aistudio.baidu.com/aistudio/projectdetail/5237474
https://www.jianshu.com/p/a7522ca6dec4
https://github.com/PaddlePaddle/PaddleSpeech/blob/develop/demos/text_to_speech/README_cn.md
1)过程中需要下载的TTS 声学相关模型(网络不好的话下面链接可以离线下载):
PaddleSpeech支持的声学模型:
['speedyspeech_csmsc-zh', 'fastspeech2_csmsc-zh', 'fastspeech2_canton-canton', 'fastspeech2_ljspeech-en', 'fastspeech2_aishell3-zh', 'fastspeech2_vctk-en', 'fastspeech2_cnndecoder_csmsc-zh', 'fastspeech2_mix-mix', 'fastspeech2_male-zh', 'fastspeech2_male-en', 'fastspeech2_male-mix', 'tacotron2_csmsc-zh', 'tacotron2_ljspeech-en', 'pwgan_csmsc-zh', 'pwgan_ljspeech-en', 'pwgan_aishell3-zh', 'pwgan_vctk-en', 'pwgan_male-zh', 'mb_melgan_csmsc-zh', 'style_melgan_csmsc-zh', 'hifigan_csmsc-zh', 'hifigan_ljspeech-en', 'hifigan_aishell3-zh', 'hifigan_vctk-en', 'hifigan_male-zh', 'wavernn_csmsc-zh', 'fastspeech2_mix-zh', 'fastspeech2_mix-en', 'pwgan_male-en', 'pwgan_male-mix', 'hifigan_male-en', 'hifigan_male-mix']
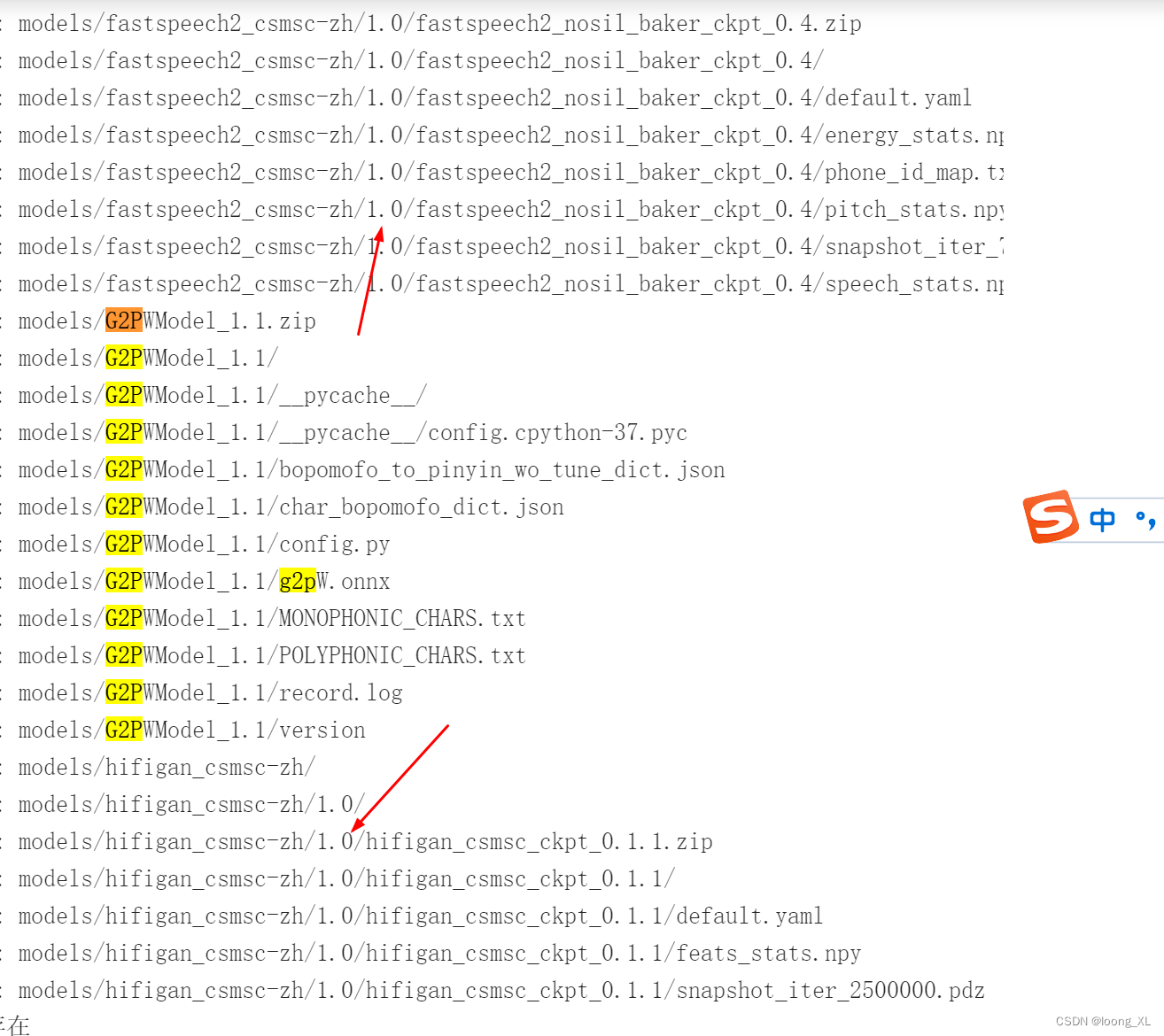
https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_nosil_baker_ckpt_0.4.zip
https://paddlespeech.bj.bcebos.com/Parakeet/released_models/hifigan/hifigan_csmsc_ckpt_0.1.1.zip
https://paddlespeech.bj.bcebos.com/Parakeet/released_models/g2p/G2PWModel_1.1.zip
https://paddlespeech.bj.bcebos.com/Parakeet/released_models/fastspeech2/fastspeech2_canton_ckpt_1.4.0.zip ##粤语模型
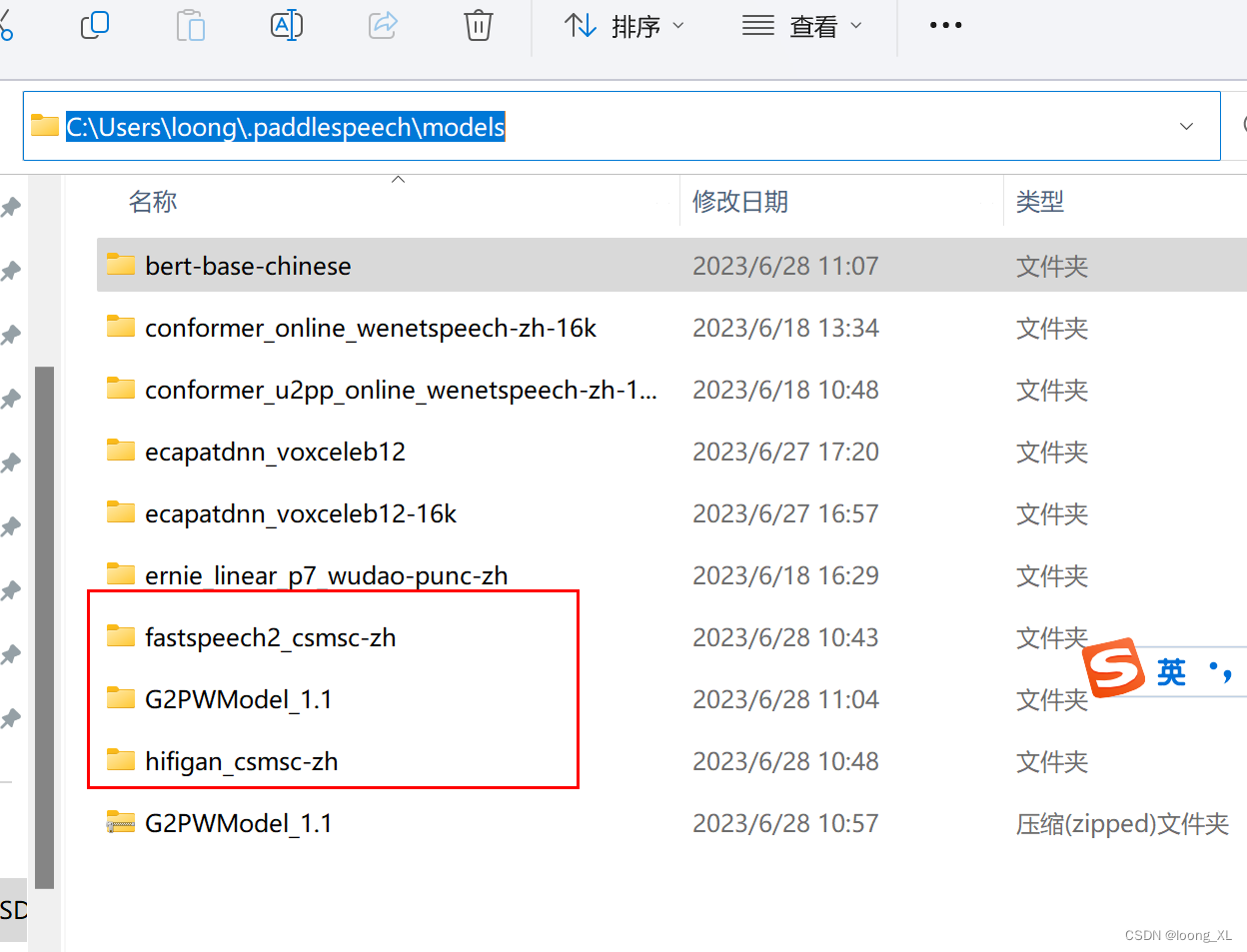
fastspeech2_csmsc-zh、hifigan_csmsc-zh这两个模型要放在1.0文件夹下,记得压缩包也要放进去;G2PWModel直接放在models目录下
*** am=‘fastspeech2_csmsc’, # TTS任务的声学模型
voc=‘hifigan_csmsc’, # TTS任务的声码器
G2PWModel是音素模型***
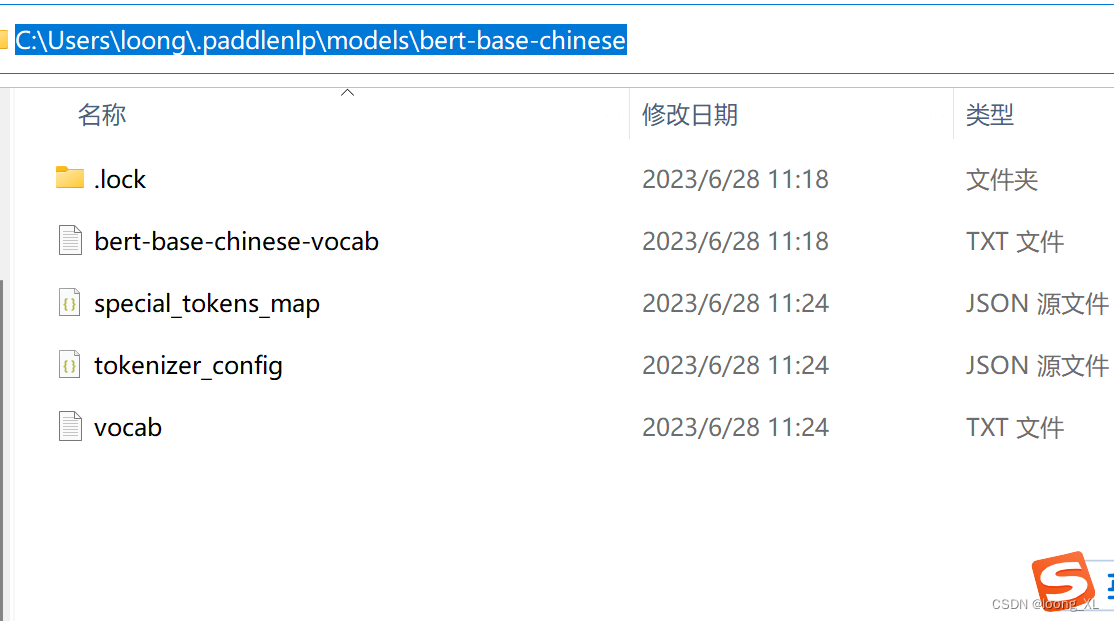
2)需要使用nl bert相关包下载:
默认放在如下地址:
https://bj.bcebos.com/paddle-hapi/models/bert/bert-base-chinese-vocab.txt
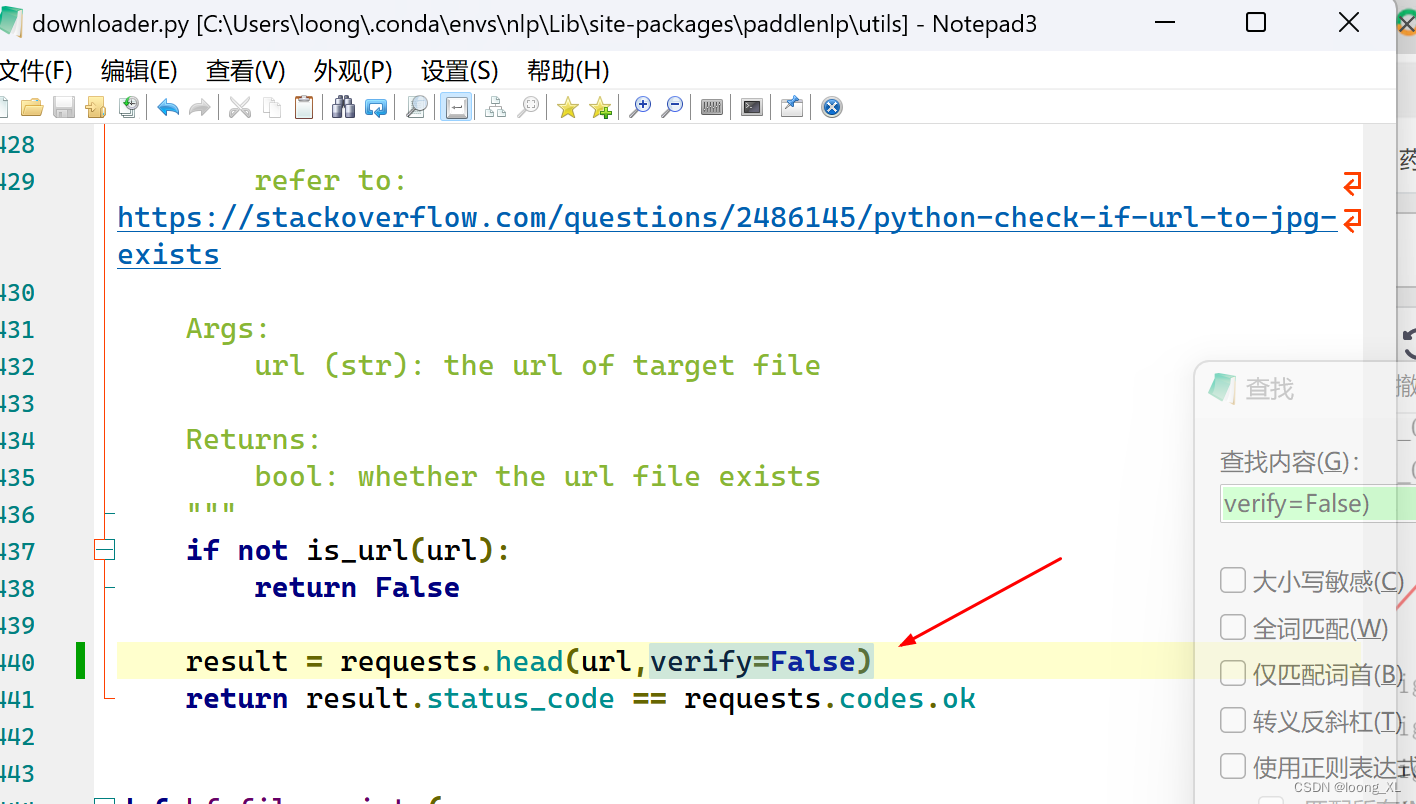
如果下载报ssl等问题,可以修改***Lib\site-packages\paddlenlp\utils下downloader.py对应requests位置添加verify=False(191、440行)
requests.get('*****‘’,verify=False)
使用
1)命令行
paddlespeech tts --input "湖北十堰竹山县的桃花摇曳多姿,和蓝天白云一起,构成一幅美丽春景。" --output output1.wav --am fastspeech2_csmsc --voc hifigan_csmsc --lang zh --spk_id 174

2)代码
from paddlespeech.cli.tts import TTSExecutor
tts_executor = TTSExecutor()
wav_file = tts_executor(
text='湖北十堰竹山县的桃花摇曳多姿,和蓝天白云一起,构成一幅美丽春景。',
output='output.wav', # 输出音频的路径
am='fastspeech2_csmsc', # TTS任务的声学模型
voc='hifigan_csmsc', # TTS任务的声码器
lang='zh', # TTS任务的语言
spk_id=174, # 说话人ID
)
粤语合成
from paddlespeech.cli.tts import TTSExecutor
tts_executor = TTSExecutor()
wav_file = tts_executor(
text='湖北十堰竹山县的桃花摇曳多姿,和蓝天白云一起,构成一幅美丽春景。',
output='output5.wav', # 输出音频的路径
# am='fastspeech2_csmsc', # TTS任务的声学模型
am="fastspeech2_canton",
voc='hifigan_csmsc', # TTS任务的声码器
lang='canton', # TTS任务的语言
spk_id=2, # 说话人ID
)