(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码)
PP-TTS:流式语音合成原理及服务部署
1 流式语音合成服务的场景与产业应用
语音合成(Speech Sysnthesis),又称文本转语音(Text-to-Speech, TTS),指的是将一段文本按照一定需求转化成对应的音频的技术。
非流式合成适合语音输出,流式合成适合语音交互
语音合成分为非流式合成和流式合成,两者在实时性上有所不同。非流式语音合成,一次性输入文字,一次性输出语音,注重语音合成系统的整体运算速度,不适合做语音交互;流式语音合成,可以对输入文本进行分词断句、声学模型和声码器局部合成语音特征和音频,分段传回合成的音频,这种语音合成方式主要关注首包响应时间,首包响应时间越短,用户就会越快收到响应,用户等待时间减少,就不会因为等待回应而失去耐心,因此整体体验感更好,更适合作为语音交互场景的语音合成方案。
语音交互场景下,离线语音合成为更好的选择
目前,语音合成系统分为云端语音合成和离线语音合成。云端语音合成主要配套端到端或多层神经网络算法,语音输出质量高、算力强,但实时性更差,不适于语音交互;近年来,离线语音合成算法和算力得到逐步更新,一些参数化的合成方案质量也可达到一定的水平,适合于合成语音的交互类场景。
2 语音合成的基本流程
本教程主要讲解基于深度学习的语音合成技术,流水线包含 文本前端(Text Frontend)、声学模型(Acoustic Model) 和 声码器(Vocoder) 三个主要模块:
- 文本前端模块将原始文本转换为字符/音素
- 声学模型将字符/音素转换为声学特征,如线性频谱图、mel 频谱图、LPC 特征等
- 声码器将声学特征转换为波形
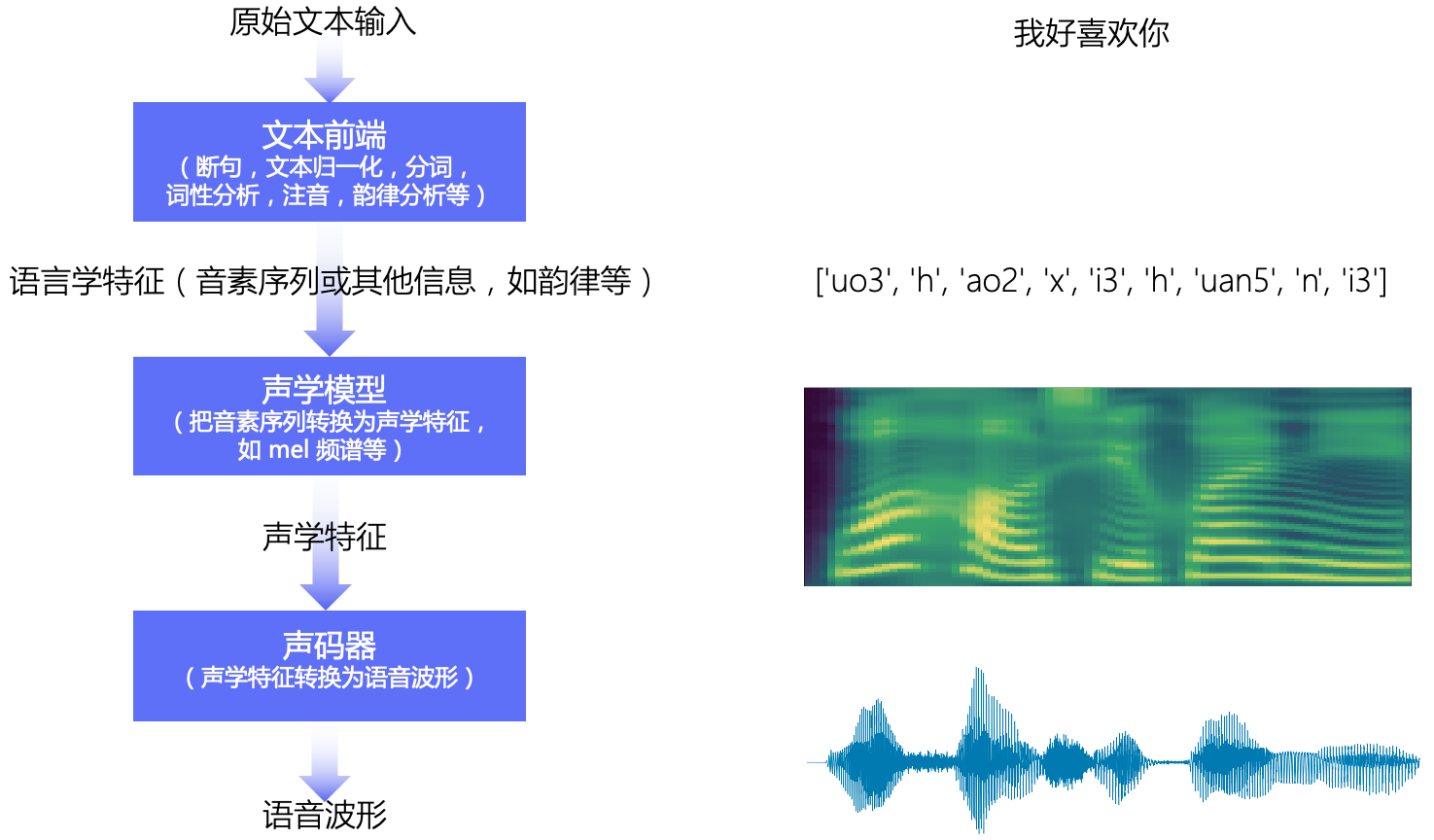
2.1 文本前端
文本前端模块主要包含: 分段(Text Segmentation)、文本正则化(Text Normalization, TN)、分词(Word Segmentation, 主要是在中文中)、词性标注(Part-of-Speech, PoS)、韵律预测(Prosody)和字音转换(Grapheme-to-Phoneme,G2P)等。
其中最重要的模块是 文本正则化 模块和 字音转换(TTS 中更常用 G2P 代指) 模块。
各模块输出示例:
• Text: 全国一共有112所211高校
• Text Normalization: 全国一共有一百一十二所二一一高校
• Word Segmentation: 全国/一共/有/一百一十二/所/二一一/高校/
• G2P(注意此句中“一”的读音):
quan2 guo2 yi2 gong4 you3 yi4 bai3 yi1 shi2 er4 suo3 er4 yao1 yao1 gao1 xiao4
(可以进一步把声母和韵母分开)
q uan2 g uo2 y i2 g ong4 y ou3 y i4 b ai3 y i1 sh i2 er4 s uo3 er4 y ao1 y ao1 g ao1 x iao4
(把音调和声韵母分开)
q uan g uo y i g ong y ou y i b ai y i sh i er s uo er y ao y ao g ao x iao
0 2 0 2 0 2 0 4 0 3 ...
• Prosody (prosodic words #1, prosodic phrases #2, intonation phrases #3, sentence #4):
全国#2一共有#2一百#1一十二所#2二一一#1高校#4
(分词的结果一般是固定的,但是不同人习惯不同,可能有不同的韵律)
2.2 声学模型
声学模型将字符/音素转换为声学特征,如线性频谱图、mel 频谱图、LPC 特征等。声学特征以 “帧” 为单位,一般一帧是 10ms 左右,一个音素一般对应 5~20 帧左右。声学模型需要解决的是 “不等长序列间的映射问题”,“不等长”是指,同一个人发不同音素的持续时间不同,同一个人在不同时刻说同一句话的语速可能不同,对应各个音素的持续时间不同,不同人说话的特色不同,对应各个音素的持续时间不同。这是一个困难的 “一对多” 问题。
# 卡尔普陪外孙玩滑梯
000001|baker_corpus|sil 20 k 12 a2 4 er2 10 p 12 u3 12 p 9 ei2 9 uai4 15 s 11 uen1 12 uan2 14 h 10 ua2 11 t 15 i1 16 sil 20
声学模型主要分为自回归模型和非自回归模型。自回归模型在 t 时刻的预测需要依赖 t-1 时刻的输出作为输入,预测时间长,但是音质相对较好;非自回归模型不存在预测上的依赖关系,预测时间快,音质相对较差。
主流声学模型:
- 自回归模型: Tacotron、Tacotron2 和 Transformer TTS 等
- 非自回归模型: FastSpeech、SpeedySpeech、FastPitch 和 FastSpeech2 等
2.3 声码器
声码器将声学特征转换为波形,它需要解决的是 “信息缺失的补全问题”。信息缺失是指,在音频波形转换为频谱图时,存在相位信息的缺失;在频谱图转换为 mel 频谱图时,存在频域压缩导致的信息缺失。假设音频的采样率是 16kHz, 即 1s 的音频有 16000 个采样点,一帧的音频有 10ms,则 1s 中包含 100 帧,每一帧有 160 个采样点。声码器的作用就是将一个频谱帧变成音频波形的 160 个采样点,所以声码器中一般会包含上采样模块。
与声学模型类似,声码器也分为自回归模型和非自回归模型:
- 自回归模型:WaveNet、WaveRNN 和 LPCNet 等
- 非自回归模型:Parallel WaveGAN、Multi Band MelGAN、Style MelGAN 和 HiFiGAN 等
更多关于语音合成基础的精彩细节,请参考之前的课程。
3 流式语音合成模型设计
语音合成的基本流程如下:

流式合成的核心思路:
将 整条音频输出 转换成以 chunk 的方式进行输出。能否进行流式合成,取决于模型的结构,一般文本前端、声学模型和声码器都可以做流式处理。
流式语音合成要求语音合成系统的实时率(Real Time Factor) RTF < 1,即合成 1s 的音频所需的时间要小于 1s,否则无法达到实时地流式合成。
为了使得语音合成系统的 RTF < 1,PaddleSpeech 选择的声学模型和声码器都是速度更快的非自回归模型,本教程以 FastSpeech2 和 HiFiGAN 为例搭建流式语音合成系统。
3.1 文本前端优化
- 若训练过程中没有使用韵律特征,可以以产生 sp、sil 等静音段处(对应文本输入的标点符号位置)作为子句的划分标准。
- 若训练过程中使用了韵律特征,可以以四级韵律划分为例(#1, #2,#3, #4),以产生 #4 处作为子句的划分标准。
PaddleSpeech TTS 流式推理按照标点符号,将长文本切为短文本,分句处理输入文本,在保证模型推理时间的前提下,还能防止因输入文本过长导致的语音效果不佳的问题(FastSpeech2 是 Transformer 结构,虽然有 Positional Embedding,但是若输入文本过长,末尾的音频质量会明显差于开头的音频质量)。
3.2 声学模型流式合成
3.2.1 自回归模型(以 Tacotron2 为例)
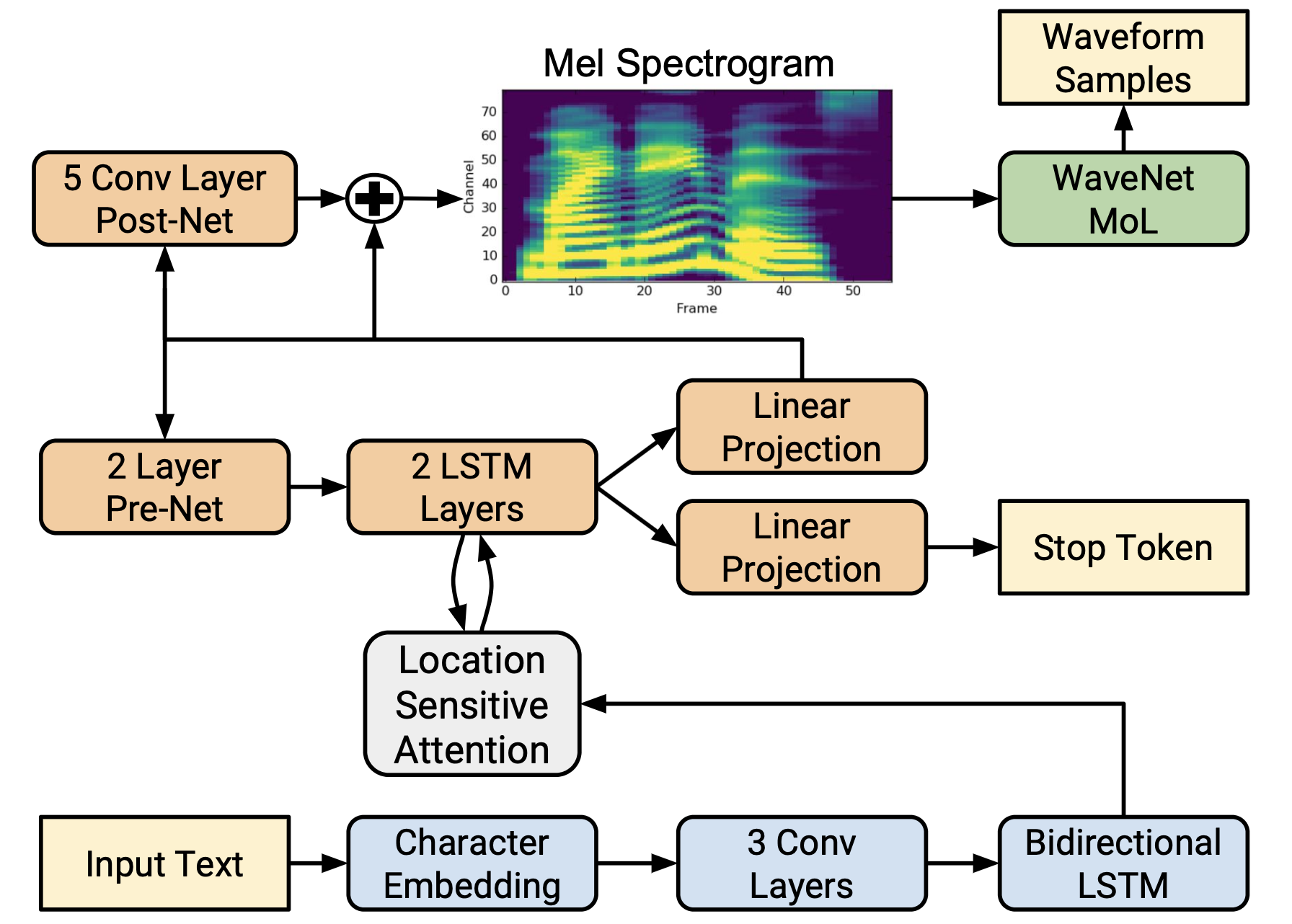
Tacotron2 结构主要分为 Encoder 和 Decoder :
- Encoder:
- Character Embedding
- ConvLayers
- Bidirectional LSTM
Encoder 计算量小,合成速度快。
- Decoder:
- LSTM Layers
- Layer PreNet
- Linear Projection
- Conv Layer PostNet
Decoder 计算量大,PreNet 逐帧输出,所有的帧计算完 concat 到一起,再输入到 PostNet。
Tacotron2 模型在进行前向计算时,主要时间消耗在 Decoder 部分,流式合成系统在 Decoder 部分进行流式计算,对 Mel 进行逐帧输出。
流式合成思路:
方案一:修改模型结构,砍掉 PostNet。
- PreNet 与 PostNet 使用的是相同的 Loss,PreNet 逐帧输出,累积到一定帧长后,输入到 Vocoder
- 代价是合成的效果相对于原版会有所下降,需要考虑在实际测试过程,这个代价是否可以接受
方案二:多级缓存。
- PreNet 输出的结果,先进入 Buffer 缓存,在达到了一定的长度之后,再输入到 PostNet
- 进入 PostNet 前对特征添加一定长度的 padding,可保持流式推理与非流式推理的结果一致
此处我们主要介绍方案二。
流式合成步骤:
- Input Text 经过 Encoder 计算后得到 Encoder Feature
- Encoder Feature 配合初始化的 Decoder State 和 Decoder Input 进入 Decoder 中进行解码得到当前帧 Mel 与下一帧计算所需的 Decoder State
- Decoder State 与上一帧 Mel 循环得到下一帧 Mel
- 单帧的 Mel 进入缓冲区(Buffer),累计到一定长度后送入 PostNet 中,进入 PostNet 前进行 Padding,将前后切片的部分特征填充到当前切片中
- 计算完成后移除 Padding 部分对应的输出,得到最终需要的 Mel 送入二级 Buffer 块中,累积到一定长度后进入声码器中进行计算得到音频
计算流程图如下图所示:

3.2.2 非自回归模型(以 FastSpeech2 为例)
FastSpeech2 模型由 Phoneme Embedding、Encoder、Variance adaptor 和 Decoder 等几个部分组成。其前向计算主要耗时集中在 Decoder 部分,因此我们选择对 Decoder 部分进行流式计算。

FastSpeech2 Encoder 和 Decoder 都是使用 FFT Block,FFT Block 中的 Multi-Head Attention 是全局依赖的,无法直接通过 chunk 的方式进行流式合成。
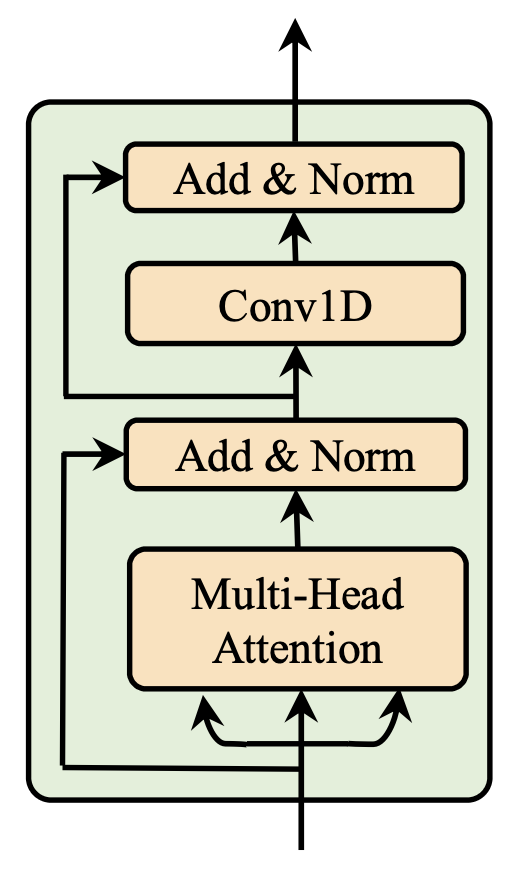
流式合成思路:
方案一: 用基于局部感受野的 Attention 替换依赖全局感受野的 Attention
方案二: 更换 FFT Block,用局部感受野的模块替换,如,以 Covn1D 为主体的模块
方案一
常见于基于 Transformer/Conformer 结构的流式 ASR 结构。
将 Decoder 的 Attention 更换成基于 chunk 的 attention,chunk 内部不会依赖于右侧的数值;同时将 Conv1D 结构更换成因果卷积(Causal Convolution),避免右侧上下文对计算的影响。基于 chunk 的 Attention 有多种选择方式,既可以是固定大小的 chunk,也可以是动态大小;可以只关注自己 chunk 内的数值,也可以只关注从开头到自己 chunk 内的数值。训练时使用基于动态 chunk 的 attention 结构,在推理过程中,可以直接使用切片后的 Encoder Feature 输入 Decoder 模块中解码,计算结果与整体合成的结果保持一致。
更多细节可参考:语音识别-流式服务-模型部分。
方案二
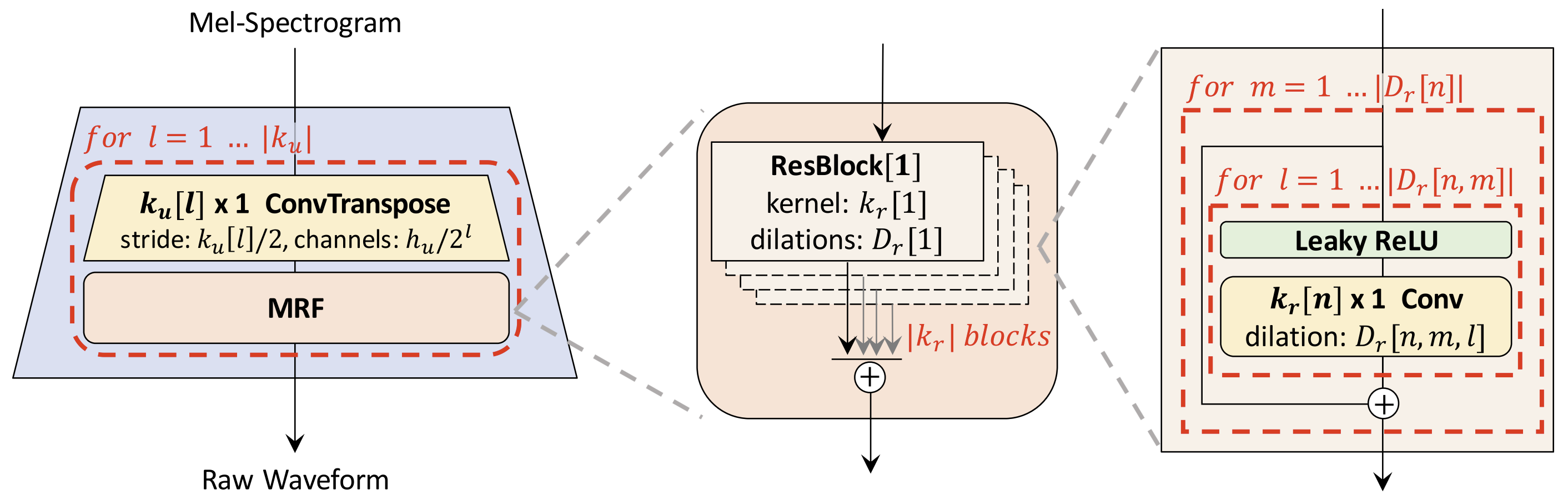
将 Decoder 的 FFT Block 替换成 Conv1D Residual Block(不限于图中结构),其模型结构如下图所示:
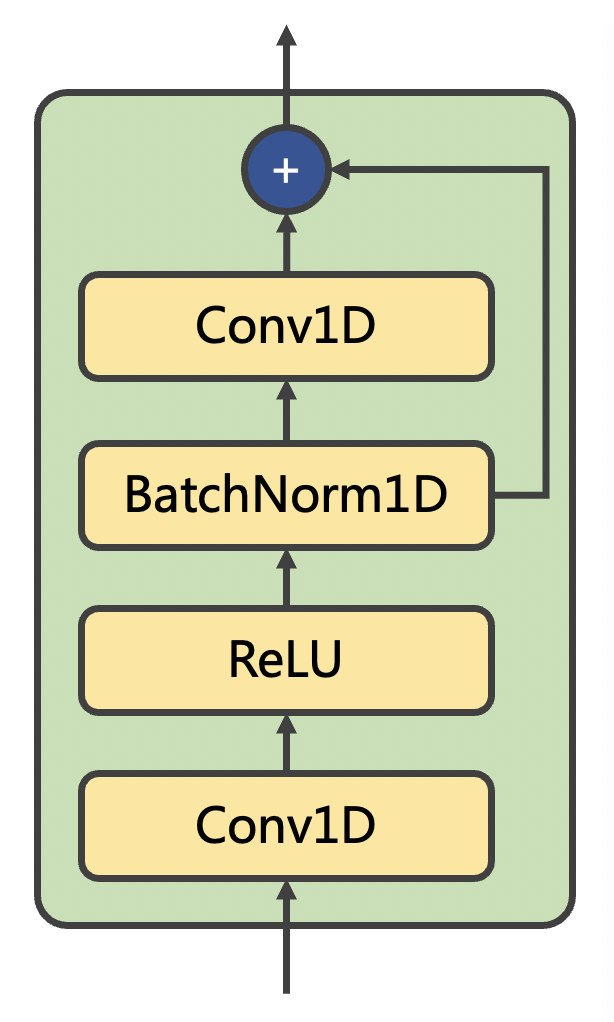
Conv1D Residual Block 结构并不会依赖于整个序列,而是依赖于局部序列,因此 Decoder 部分可以通过切片的方式进行流式合成,只要保证对局部的 chunk 输入,padding 足够多的前后信息,就可以使拼接起来的局部输出与输入完整信息得到的输出在数值上一致。
流式合成步骤如下:
- Input Text 经过 Phoneme Embedding 之后,通过 Encoder 模块的计算得到 Encoder Feature(图中简写为 EF)
- 对 Encoder Feature 进行切片,切片后的特征进行 Padding,将前后切片的部分特征填充到当前切片中
- 添加了前后 Padding 信息的 EF 经过 Decoder 计算得到 Decoder Feature(DF)
- 移除 Padding 部分对应的输出,则可以得到与整体计算结果一致的 DF
计算流程图如下图所示:
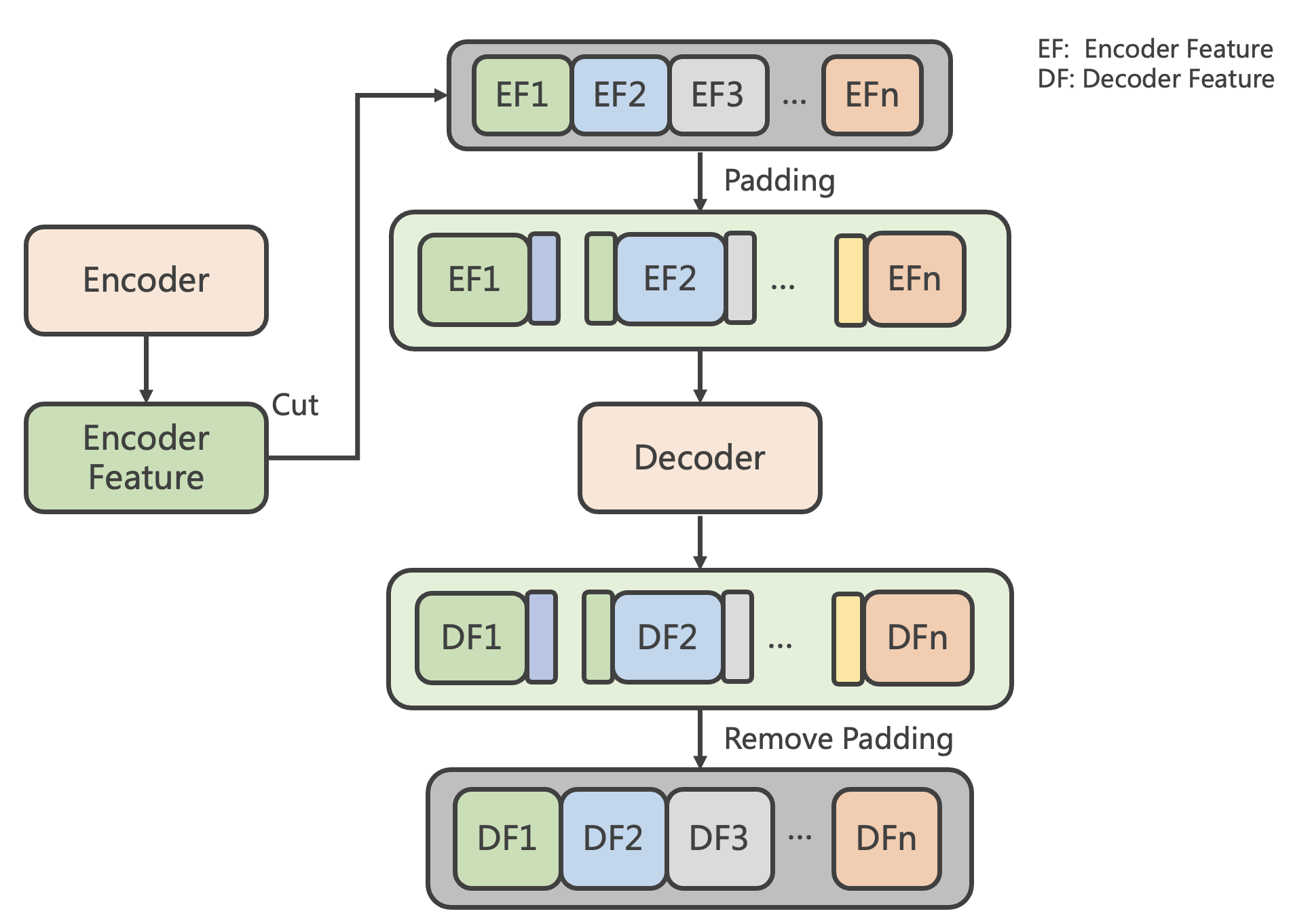
PaddleSpeech 流式语音合成的声学模型选择 FastSpeech2 的方案二,声学模型流式推理过程请参考:synthesize_streaming.py
3.3 声码器流式合成
声码器流式合成以 HiFiGAN 模型为例进行说明。基于 GAN 的声码器流式合成的原理与 FastSpeech2 流式合成的方案二类似,因为 GAN Vocoder 的生成器主要是由卷积块组成的,只要保证对局部的 chunk 输入,padding 足够多的前后信息,就可以使拼接起来的局部输出与输入完整信息得到的输出在数值上一致。
基于 GAN 的 Vocoder 模型主体结构分为两个部分,生成器(Generator)与判别器(Discriminator)。
在推理过程中仅需要使用生成器模块,生成器主体部分由 Conv1D、Conv1DTranspose 和 Residual Block 等模块组成。
语音合成的推理过程与 Vocoder 的判别器无关。
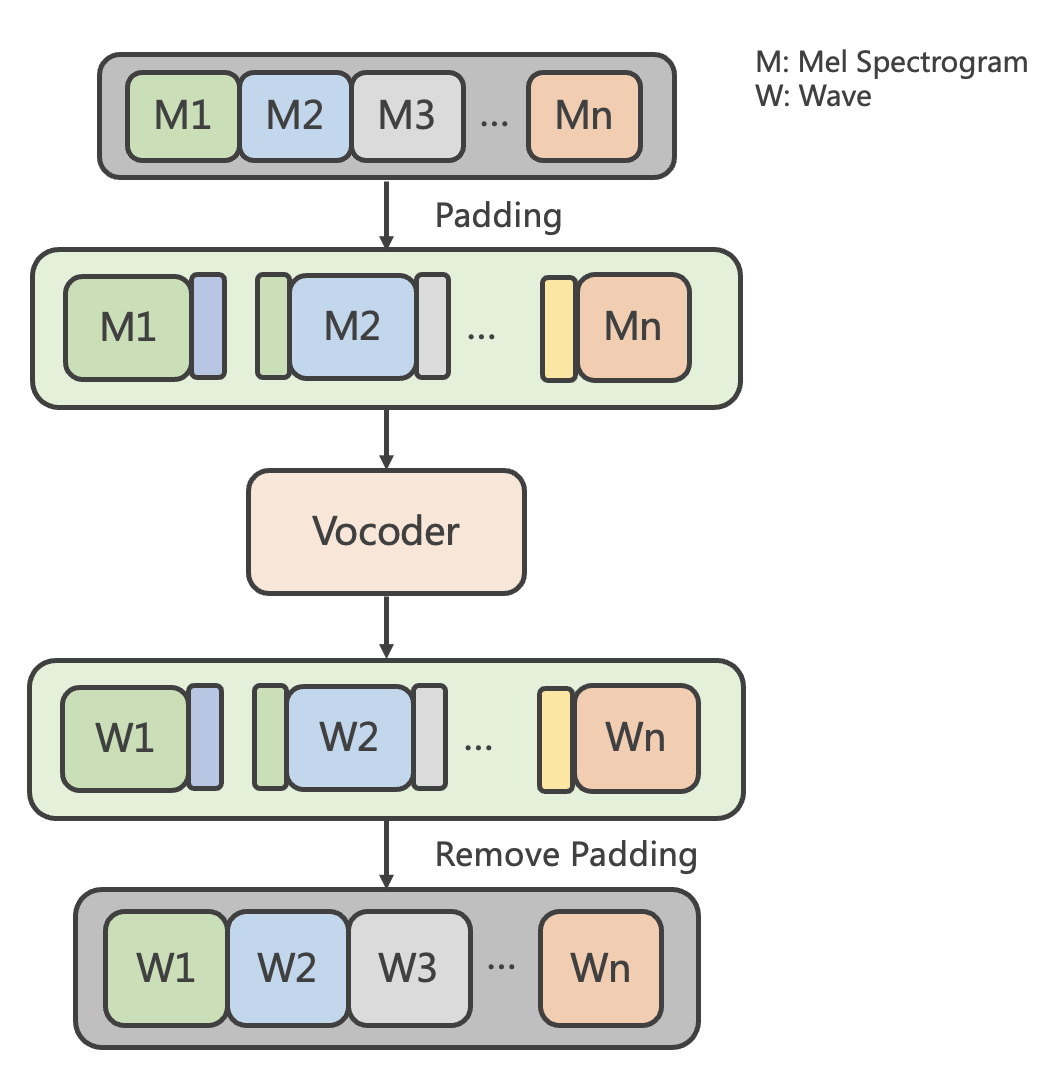
声码器流式合成时,Mel Spectrogram(图中简写 M)通过 Vocoder 的生成器模块计算得到对应的 Wave(图中简写 W)。
声码器流式合成步骤如下:
- 在进入 Vocoder 之前,对 Mel Spectrogram 进行切片,切片后的特征进行 Padding,将前后切片的部分特征填充到当前切片中
- 添加了前后 Padding 信息的 Mel 块输入给 Vocoder 计算得到添加了 Padding 的 Wave
- 移除 Padding 部分对应的 Wave 块,得到与整体计算数值一致的 Wave 块
计算流程图如下图所示:
不同模块 padding 的大小因感受野不同而变化,目前 PaddleSpeech 提供的模型配置,与整体计算数值一致的 padding 值:
- FastSpeech2_CNNDecoder: 12
- Multi Band MelGAN: 14
- HiFiGAN: 19
实际应用中,可根据推理速度上的需求,在不影响合成效果的前提下,适当降低 padding 值。
4 基于 ONNXRuntime 的语音合成推理引擎
ONNX 是一种针对机器学习所设计的开放式的文件格式,用于存储训练好的模型。它使得不同的深度学习框架(如 PaddlePaddle 、Pytorch、TensorFlow 等)可以采用相同格式存储模型数据。是一种便于在各个主流深度学习框架中迁移模型的中间表达格式。
ONNXRuntime 是微软推出的一款推理框架,用户可以非常便利的用其运行 ONNX 模型,它支持多种运行后端包括 CPU、GPU、TensorRT 和 DML 等。把深度学习框架训练好的模型转换成 ONNX 格式的模型,再利用 ONNXRuntime 引擎进行推理,会达到比用该深度学习框架原生推理引擎更快的速度,一般的交互式硬件只有质量一般的 CPU,并没有 GPU,利用 ONNXRuntime-CPU,可以多线程地运行神经网络推理流程,大大加快语音合成模型的推理速度,更好地满足流式语音合成的要求。
ONNX 模型的通用性,使开发者可以把模型替换成在其他深度学习框架训练好的模型,而不需要对流式语音合成服务的代码进行大的修改。极大地提升了语音合成服务代码的复用性。
使用 ONNXRuntime 进行流式推理,需要经过如下步骤:
- 动态图训练
- 动转静
- 静态图推理(保证静态图模型没问题)
- 静态图 Paddle2ONNX
- ONNXRuntime / ONNX 推理
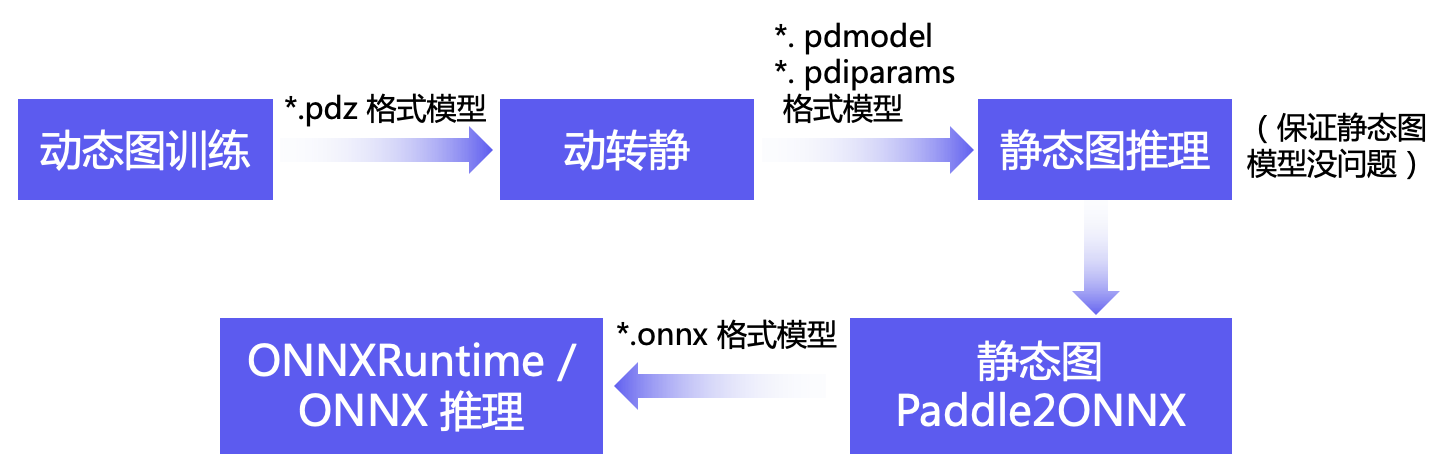
参考: tts3/run.sh (default FastSpeech2)和 tts3/run_cnndecoder.sh (FastSpeech2_CNNDecoder)
4.1 动态图训练
PaddlePaddle 在模型开发时,推荐采用动态图编程。 可获得更好的编程体验、更易用的接口、更友好的调试交互机制。
run.sh 的 stage0 数据预处理和 stage1 训练
if [ ${stage} -le 0 ] && [ ${stop_stage} -ge 0 ]; then
# prepare data
./local/preprocess.sh ${conf_path} || exit -1
fi
if [ ${stage} -le 1 ] && [ ${stop_stage} -ge 1 ]; then
# train model, all `ckpt` under `train_output_path/checkpoints/` dir
CUDA_VISIBLE_DEVICES=${gpus} ./local/train.sh ${conf_path} ${train_output_path} || exit -1
fi
4.2 动转静
若要使用 PaddleInference 推理引擎或者将 Paddle 模型转换成通用的 ONNX 模型,需要对 Paddle 的动态图模型进行动转静。
Paddle 动转静相关概念请参考 动态图转静态图。
run.sh 的 stage3
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
# synthesize_e2e, vocoder is pwgan
CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_output_path} ${ckpt_name} || exit -1
fi
run_cnndecoder.sh 的 stage3(完整推理) 和 stage5(流式推理)
# synthesize_e2e non-streaming
if [ ${stage} -le 3 ] && [ ${stop_stage} -ge 3 ]; then
# synthesize_e2e, vocoder is pwgan
CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_e2e.sh ${conf_path} ${train_output_path} ${ckpt_name} || exit -1
fi
# synthesize_e2e streaming
if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; then
# synthesize_e2e, vocoder is pwgan
CUDA_VISIBLE_DEVICES=${gpus} ./local/synthesize_streaming.sh ${conf_path} ${train_output_path} ${ckpt_name} || exit -1
fi
PaddleSpeech 在运行 synthesize_e2e.py 和 synthesize_streaming.py 脚本时,如果输入了 --inference_dir,会执行动转静、保存静态模型后 load、再用 load 的静态参数推理:
jit.to_static()jit.save()jit.load()
注意,FastSpeech2_CNNDecoder 用于流式合成时,在动转静时需要导出 3 个静态模型,分别是:
- fastspeech2_csmsc_am_encoder_infer.*
- fastspeech2_csmsc_am_decoder.*
- fastspeech2_csmsc_am_postnet.*
FastSpeech2_CNNDecoder 用于非流式合成时,可以只导出一个模型,参考 synthesize_e2e.py
4.3 静态图推理
静态图推理的目的是保证动转静导出的模型没问题,使用 PaddleInference 引擎进行推理。
run.sh 的 stage4
if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
# inference with static model
CUDA_VISIBLE_DEVICES=${gpus} ./local/inference.sh ${train_output_path} || exit -1
fi
run_cnndecoder.sh 的 stage4(完整推理) 和 stage6(流式推理)
# inference non-streaming
if [ ${stage} -le 4 ] && [ ${stop_stage} -ge 4 ]; then
# inference with static model
CUDA_VISIBLE_DEVICES=${gpus} ./local/inference.sh ${train_output_path} || exit -1
fi
# inference streaming
if [ ${stage} -le 6 ] && [ ${stop_stage} -ge 6 ]; then
# inference with static model
CUDA_VISIBLE_DEVICES=${gpus} ./local/inference_streaming.sh ${train_output_path} || exit -1
fi
4.4 Paddle2ONNX
可以使用 Paddle2ONNX 把 Paddle 的静态图模型转换成通用的 ONNX 模型格式。
run.sh 的 stage5
# paddle2onnx, please make sure the static models are in ${train_output_path}/inference first
# we have only tested the following models so far
if [ ${stage} -le 5 ] && [ ${stop_stage} -ge 5 ]; then
# install paddle2onnx
version=$(echo `pip list |grep "paddle2onnx"` |awk -F" " '{print $2}')
if [[ -z "$version" || ${version} != '0.9.5' ]]; then
pip install paddle2onnx==0.9.5
fi
./local/paddle2onnx.sh ${train_output_path} inference inference_onnx fastspeech2_csmsc
./local/paddle2onnx.sh ${train_output_path} inference inference_onnx hifigan_csmsc
./local/paddle2onnx.sh ${train_output_path} inference inference_onnx mb_melgan_csmsc
fi
run_cnndecoder.sh 的 stage7(完整推理) 和 stage9(流式推理)
# paddle2onnx non streaming
if [ ${stage} -le 7 ] && [ ${stop_stage} -ge 7 ]; then
# install paddle2onnx
version=$(echo `pip list |grep "paddle2onnx"` |awk -F" " '{print $2}')
if [[ -z "$version" || ${version} != '0.9.5' ]]; then
pip install paddle2onnx==0.9.5
fi
./local/paddle2onnx.sh ${train_output_path} inference inference_onnx fastspeech2_csmsc
./local/paddle2onnx.sh ${train_output_path} inference inference_onnx hifigan_csmsc
fi
# paddle2onnx streaming
if [ ${stage} -le 9 ] && [ ${stop_stage} -ge 9 ]; then
# install paddle2onnx
version=$(echo `pip list |grep "paddle2onnx"` |awk -F" " '{print $2}')
if [[ -z "$version" || ${version} != '0.9.5' ]]; then
pip install paddle2onnx==0.9.5
fi
# streaming acoustic model
./local/paddle2onnx.sh ${train_output_path} inference_streaming inference_onnx_streaming fastspeech2_csmsc_am_encoder_infer
./local/paddle2onnx.sh ${train_output_path} inference_streaming inference_onnx_streaming fastspeech2_csmsc_am_decoder
./local/paddle2onnx.sh ${train_output_path} inference_streaming inference_onnx_streaming fastspeech2_csmsc_am_postnet
# vocoder
./local/paddle2onnx.sh ${train_output_path} inference_streaming inference_onnx_streaming hifigan_csmsc
fi
4.5 ONNX / ONNXRuntime 推理
导出 ONNX 格式的模型后,就可以用 ONNX 引擎或者 ONNXRuntime 进行推理啦,此处我们选择 ONNXRuntime 作为推理引擎。采用 ONNXRuntime 作为推理引擎,FastSpeech2 + HIFIGAN 即使在低压 CPU 上也可以达到实时,满足流式合成的要求。
run.sh 的 stage6
# inference with onnxruntime, use fastspeech2 + hifigan by default
if [ ${stage} -le 6 ] && [ ${stop_stage} -ge 6 ]; then
./local/ort_predict.sh ${train_output_path}
fi
run_cnndecoder.sh 的 stage8(完整推理) 和 stage10(流式推理)
# onnxruntime non streaming
# inference with onnxruntime, use fastspeech2 + hifigan by default
if [ ${stage} -le 8 ] && [ ${stop_stage} -ge 8 ]; then
./local/ort_predict.sh ${train_output_path}
fi
# onnxruntime streaming
if [ ${stage} -le 10 ] && [ ${stop_stage} -ge 10 ]; then
./local/ort_predict_streaming.sh ${train_output_path}
fi
5 语音合成服务部署
5.1 非流式语音合成服务的启动和访问
安装好 PaddleSpeech 之后,可以通过命令行的形式快速启动和访问非流式语音合成服务。参考链接:demos/speech_server
启动及访问服务的流程如下图所示:
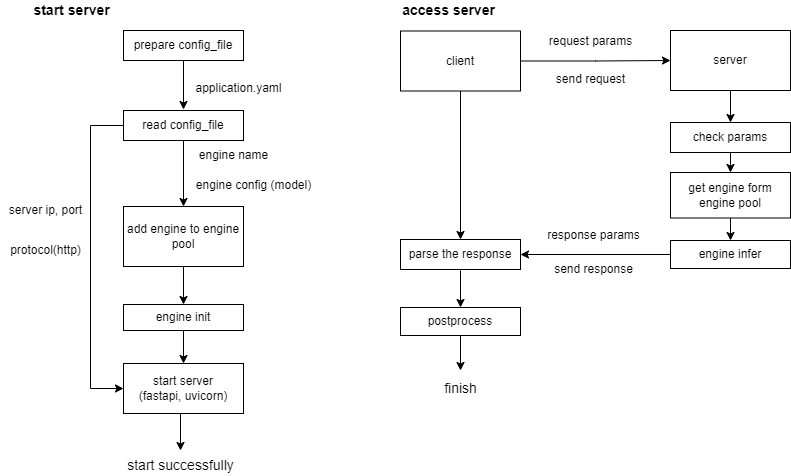
启动服务步骤:
- 准备服务对应的配置参数文件,文件内包含该服务启动使用的模型相关信息和服务端口,引擎选择的相关信息,详情可看 5.1.1 小节
- 根据配置文件中引擎的选择将对应的引擎加入到引擎池中(该步骤的目的是为了使得启动的服务入口可以支持多个语音服务)
- 根据配置文件中的模型配置对上述对应的引擎进行初始化
- 使用 fastapi 和 uvicorn 启动服务
访问服务步骤:
- client 端向 server 端发送 http 请求(在这个过程中,client 端会先向 server 端发送建立连接请求并和 server 端建立连接)
- server 端收到请求后先检查字段内容是否有效,然后去引擎池取对应的引擎
- 引擎进行推理生成合成音频,将其封装成设计的响应格式,返回响应到 client 端,并自动断开连接
- client 端收到响应后,对其结果进行后处理(保存音频操作)
5.1.1 准备服务配置文件
首先我们需要准备一个服务相关的 yaml 配置文件(application.yaml),配置文件内容如下:
host: 0.0.0.0 # server ip
port: 8090 # server port
protocol: 'http' # only support http
engine_list: ['tts_python'] # speech task_engine type, can choose tts_python or tts_inference.
################### speech task: tts; engine_type: python #######################
tts_python:
# am (acoustic model) choices=['speedyspeech_csmsc', 'fastspeech2_csmsc', 'fastspeech2_ljspeech', 'fastspeech2_aishell3', 'fastspeech2_vctk']
am: 'fastspeech2_csmsc'
am_config:
am_ckpt:
am_stat:
phones_dict:
tones_dict:
speaker_dict:
# voc (vocoder) choices=['pwgan_csmsc', 'pwgan_ljspeech', 'pwgan_aishell3', 'pwgan_vctk', 'mb_melgan_csmsc']
voc: 'pwgan_csmsc'
voc_config:
voc_ckpt:
voc_stat:
# others
lang: 'zh'
device: # set 'gpu:id' or 'cpu'
################### speech task: tts; engine_type: inference #######################
tts_inference:
# am (acoustic model) choices=['speedyspeech_csmsc', 'fastspeech2_csmsc']
am: 'fastspeech2_csmsc'
am_model: # the pdmodel file of your am static model (XX.pdmodel)
am_params: # the pdiparams file of your am static model (XX.pdipparams)
am_sample_rate: 24000
phones_dict:
tones_dict:
speaker_dict:
am_predictor_conf:
device: # set 'gpu:id' or 'cpu'
switch_ir_optim: True
glog_info: False # True -> print glog
summary: True # False -> do not show predictor config
# voc (vocoder) choices=['pwgan_csmsc', 'mb_melgan_csmsc','hifigan_csmsc']
voc: 'pwgan_csmsc'
voc_model: # the pdmodel file of your vocoder static model (XX.pdmodel)
voc_params: # the pdiparams file of your vocoder static model (XX.pdipparams)
voc_sample_rate: 24000
voc_predictor_conf:
device: # set 'gpu:id' or 'cpu'
switch_ir_optim: True
glog_info: False # True -> print glog
summary: True # False -> do not show predictor config
# others
lang: 'zh'
5.1.2 一键式启动服务
服务的配置文件(application.yaml)准备好后,执行下述命令可一键启动服务:
paddlespeech_server start --config_file application.yaml
显示如下表示启动服务成功:
[2022-02-23 11:17:32] [INFO] [server.py:64] Started server process [6384]
INFO: Waiting for application startup.
[2022-02-23 11:17:32] [INFO] [on.py:26] Waiting for application startup.
INFO: Application startup complete.
[2022-02-23 11:17:32] [INFO] [on.py:38] Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
[2022-02-23 11:17:32] [INFO] [server.py:204] Uvicorn running on http://0.0.0.0:8090 (Press CTRL+C to quit)
5.1.3 一键式访问 TTS 服务
使用如下指令可直接访问非流式 TTS 服务:
paddlespeech_client tts --server_ip 127.0.0.1 --port 8090 --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
结果显示如下表示访问服务成功:
[2022-02-23 15:20:37,875] [ INFO] - {
'description': 'success.'}
[2022-02-23 15:20:37,875] [ INFO] - Save synthesized audio successfully on output.wav.
[2022-02-23 15:20:37,875] [ INFO] - Audio duration: 3.612500 s.
[2022-02-23 15:20:37,875] [ INFO] - Response time: 0.348050 s.
5.1.4 服务接口定义
url: http://127.0.0.1:8090/paddlespeech/tts
请求方式:POST
请求示例如下,该示例包含所有字段:
{
"text": "您好,欢迎使用百度飞桨语音合成服务。",
"spk_id": 0,
"speed": 1.0,
"volume": 1.0,
"sample_rate": 0,
"save_path": "./output.wav",
}
成功返回示例如下:
{
"success": true,
"code": 0,
"message": {"global": "success" }
"result": {
"lang": "zh",
"spk_id": 0,
"speed": 1.0,
"volume": 1.0,
"sample_rate": 24000,
"duration": 3.6125,
"save_path": "./output.wav",
"audio": "LTI1OTIuNjI1OTUwMzQsOTk2OS41NDk4..."
}
}
更多非流式服务接口定义请参考:PaddleSpeech 语音服务接口定义
5.2 流式语音合成服务的启动和访问
安装好 PaddleSpeech 之后,可以通过命令行的形式来快速启动访问流式 TTS 服务。参考链接:demos/streaming_tts_server
流式 TTS 服务支持 http 和 webscoket 两种协议。
http 支持流式返回,可以满足目前的流式 TTS 的方案,即请求一次,返回流式数据,响应返回结束会自动断开连接。
而 websocket 支持双工,适用于需要长连接的场景,也可应用于目前的流式 TTS 的方案,可以在一次连接中请求多次,相比 http 请求多次而言,可减少建立连接的次数。
除此之外,流式 ASR 使用的是 websocket 协议,使用 webscoket 协议启动服务,可以同时启动包含流式 ASR 和流式 TTS 的服务。
启动流式 TTS 服务的整体流程与启动非流式 TTS 服务的整体流程一致。
访问流式 TTS 服务流程如下图所示:

访问 http 流式服务步骤:
- client 端向 server 端发送 http 请求(在这个过程中,client 端会先向 server 端发送建立连接请求并和 server 端建立连接)
- server 端收到请求后先检查字段内容是否有效,然后去引擎池取对应的引擎
- 引擎进行推理不断生成音频流,将音频片段转成 base64 返回,返回流结束后并自动断开连接
- client 端收到响应后,可以对其进行操作,例如播放音频
访问 websocket 流式服务步骤:
- client 端向 server 端发送握手请求,握手成功后 client 端和 server 端会建立 websocket 连接
- 建立 websocket 连接后,client 端首先向 server 端发送 start 请求,获取本次连接的标识 id(session)
- client 端收到 server 端对 start 请求的响应之后,client 端向 server 端发送语音合成请求
- server 端收到请求后先检查字段内容是否有效,然后去引擎池取对应的引擎
- 引擎进行推理不断生成音频流,将音频片段转成 base64 并封装成设计的响应格式,返回响应到 client 端
- client 端收到响应后,可以对其进行操作,例如播放音频
- client 端收到最后一个响应之后,向 server 端发送 end 请求,server 断开 websocket 连接(单请求情况,若多请求可以一直保持连接)
5.2.1 服务配置文件
无论是 http 协议还是 websocket 协议,启动服务都需要有服务配置 yaml 文件(tts_online_application.yaml)。
若想启动 http 协议的服务,将 protocol 设置为 http ;若想启动 websocket 协议的服务,将 protocol 设置为 websocket,配置文件内容如下:
host: 0.0.0.0
port: 8092
protocol: 'http'
engine_list: ['tts_online-onnx']
################### speech task: tts; engine_type: online #######################
tts_online:
# am (acoustic model) choices=['fastspeech2_csmsc', 'fastspeech2_cnndecoder_csmsc']
am: 'fastspeech2_csmsc'
am_config:
am_ckpt:
am_stat:
phones_dict:
tones_dict:
speaker_dict:
# voc (vocoder) choices=['mb_melgan_csmsc, hifigan_csmsc']
voc: 'mb_melgan_csmsc'
voc_config:
voc_ckpt:
voc_stat:
# others
lang: 'zh'
device: 'cpu' # set 'gpu:id' or 'cpu'
am_block: 72
am_pad: 12
voc_block: 36
voc_pad: 14
################### speech task: tts; engine_type: online-onnx #######################
tts_online-onnx:
# am (acoustic model) choices=['fastspeech2_csmsc_onnx', 'fastspeech2_cnndecoder_csmsc_onnx']
am: 'fastspeech2_cnndecoder_csmsc_onnx'
# am_ckpt is a list, if am is fastspeech2_cnndecoder_csmsc_onnx, am_ckpt = [encoder model, decoder model, postnet model];
# if am is fastspeech2_csmsc_onnx, am_ckpt = [ckpt model];
am_ckpt: # list
am_stat:
phones_dict:
tones_dict:
speaker_dict:
spk_id: 0
am_sample_rate: 24000
am_sess_conf:
device: "cpu" # set 'gpu:id' or 'cpu'
use_trt: False
cpu_threads: 4
# voc (vocoder) choices=['mb_melgan_csmsc_onnx, hifigan_csmsc_onnx']
voc: 'hifigan_csmsc_onnx'
voc_ckpt:
voc_sample_rate: 24000
voc_sess_conf:
device: "cpu" # set 'gpu:id' or 'cpu'
use_trt: False
cpu_threads: 4
# others
lang: 'zh'
am_block: 72
am_pad: 12
voc_block: 36
voc_pad: 14
voc_upsample: 300
5.2.2 一键式启动服务
服务的配置文件(application.yaml)准备好后,执行下述命令可一键启动服务:
paddlespeech_server start --config_file tts_online_application.yaml
显示如下表示启动服务成功:
[2022-04-24 21:00:17] [INFO] [server.py:75] Started server process [320]
INFO: Waiting for application startup.
[2022-04-24 21:00:17] [INFO] [on.py:45] Waiting for application startup.
INFO: Application startup complete.
[2022-04-24 21:00:17] [INFO] [on.py:59] Application startup complete.
INFO: Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
[2022-04-24 21:00:17] [INFO] [server.py:211] Uvicorn running on http://0.0.0.0:8092 (Press CTRL+C to quit)
5.2.3 一键式访问流式 TTS 服务
使用如下指令可一键式访问流式 TTS 服务:
访问 http 流式 TTS 服务 (–protocol http)
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8090 --protocol http --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
访问 websocket 流式 TTS 服务 (–protocol websocket)
paddlespeech_client tts_online --server_ip 127.0.0.1 --port 8090 --protocol websocket --input "您好,欢迎使用百度飞桨语音合成服务。" --output output.wav
结果显示如下表示访问服务成功:
[2022-04-24 21:08:21,702] [ INFO] - 句子:您好,欢迎使用百度飞桨语音合成服务。
[2022-04-24 21:08:21,703] [ INFO] - 首包响应:0.18863153457641602 s
[2022-04-24 21:08:21,704] [ INFO] - 尾包响应:3.1427218914031982 s
[2022-04-24 21:08:21,704] [ INFO] - 音频时长:3.825 s
[2022-04-24 21:08:21,704] [ INFO] - RTF: 0.8216266382753459
[2022-04-24 21:08:21,739] [ INFO] - 音频保存至:output.wav
5.2.4 服务接口定义
- 访问 http 流式 TTS 服务
url: http://127.0.0.1:8092/paddlespeech/tts/stareaming
请求方式:POST
请求示例如下,该示例包含所有字段(目前流式 TTS 服务只使用到 text 字段,其他字段暂不生效):
{
"text": "您好,欢迎使用百度飞桨语音合成服务。",
"spk_id": 0,
"speed": 1.0,
"volume": 1.0,
"sample_rate": 0,
"save_path": "./output.wav",
}
返回为音频经过 base64 编码的 string,如下:
LTI1OTIuNjI1OTUwMzQsOTk2OS41NDk4...
- 访问 websocket 流式 TTS 服务
url: ws://127.0.0.1:8092/paddlespeech/tts/stareaming
- 首先建立 websocket 连接,建立连接后发送开始请求,请求示例如下:
{
"task": "tts",
"signal": "start"
}
成功响应开始请求的示例如下,其中 status 为 0 表示可以开始发送请求,signal 表示 server 是否准备好, session 为 40 位的随机字符串,用来表示此次连接的编号。
{
"status": 0,
"signal": "server ready",
"session": "UloVFXg3xjb2nIP6xH58Ms8G98vnA1thHL6snKOy"
}
- server 端返回成功开始的响应后,client 端向服务端发送流式语音合成请求,请求示例如下。其中 text 字段表示待合成文本经过 base64 编码后的 string,下述 string 对应的文本为:您好,欢迎使用百度飞桨语音合成服务。
注意:流式 http request 直接传文本,websocket 传 base64 的 string,具体原因会在 FAQ 部分解释。
{
"text": "5oKo5aW977yM5qyi6L+O5L2/55So55m+5bqm6aOe5qGo6K+t6Z+z5ZCI5oiQ5pyN5Yqh44CC",
}
成功响应示例如下,其中 status 字段表示音频片段是否为最后一段,status 为 2 表示该音频片段为最后一片段,status 为 1 表示该音频片段不是最后一片段;audio 字段表示音频片段经过 base64 编码后的 string。
{
"status": 1,
"audio": "LTI1OTIuNjI1OTUwMzQsOTk2OS41NDk4...",
"session": "UloVFXg3xjb2nIP6xH58Ms8G98vnA1thHL6snKOy"
}
- client 端收到 server 返回的 status 为 2 的最后一个音频片段的响应后,发送结束连接的请求,请求示例如下,其中 session 表示此次连接的编号。
{
"task": "tts",
"signal": "end",
"session": "UloVFXg3xjb2nIP6xH58Ms8G98vnA1thHL6snKOy",
}
成功响应示例如下:
{
"status": 0,
"signal": "connection will be closed",
"session": "UloVFXg3xjb2nIP6xH58Ms8G98vnA1thHL6snKOy"
}
更多流式服务接口定义请参考:PaddleSpeech Streaming Server WebSocket API (仅 websocket)
5.3 Demo 演示
下例中,server 端和 client 端均运行在低配 Windows10 笔记本上,机器配置如下:
Python 版本:3.8.3
Paddle 版本:2.3.0rc
PaddleSpeech 版本:1.0.0
ONNXRuntime 版本:1.10.0
CPU:
- Intel® Core™ i5-8250U CPU @ 1.60GHz
- cpu 核数:4
- 逻辑 cpu (线程):8
内存:8G
FAQ
1. 为什么流式 http request 直接传文本,websocket 传 base64 的 string ?
因为 http 流式服务直接复用了非流式 TTS 服务的请求类,非流式请求类直接传文本是为了使请求看上去比较直观(直接显示文本),如果想改成传 base64 的 string 也可以(改下代码就行)。websocket 是考虑到网络中传 base64 可能会更快些,也可以直接传文本。(总体而言,传哪种类型并不是那么重要)
2. 为什么流式 TTS 服务既支持 http 协议又支持 websocket 协议 ?
http 支持流式返回,可以满足我们流式 TTS 的需求,比 websocket 建立连接要简单,比较直观,响应返回结束后会自动断开连接。
而 websocket 支持双工,可以一直建立连接,因此它不仅能支持目前的流式(一开始传入的就是确定好的文本,然后模型支持流式),也能支持分段输入的文本进行流式合成,例如一段文本返回一个响应(这样的情况模型可以不支持流式)。并且 websocket 可以支持流式语音识别,因此在我们的框架下,使用 websocket 协议,可以同时启动流式语音合成和流式语音识别的服务。
3. http 流式和 websocket 流式的区别和利弊 ?
http 适用于单次请求访问,每次请求之前都需要建立连接,相比 websocket 更直观,简洁,无需发送 start 请求和 end 请求。
websocket 适用于多次请求访问,它可以更好地支持长连接,相比 http 的多次请求而言,可以减少建立连接的次数,同时流式 ASR 也使用了 websocket 协议,因此使用 websocket 协议可以在一个服务中同时启动两个语音任务。仅针对流式 TTS 单请求而言,使用 http 和 websocket 差别不大。