计算机的核心作用就是计算、存储,其中数据结构与算法直接决定了计算机的计算效率。所以学好数据结构与算法是做好计算机软件工作非常基础的能力。日常工作中遇到最多的莫过于排序、搜索,本文将针对这两类算法做个探索。
1 时间复杂度
在介绍具体的算法之前,先看下不同的时间复杂度的区别如下图所示。

2 排序算法
排序算法常见的主要有交换排序、插入排序、选择排序、计数排序等

一般算法都是优先考虑时间复杂度,故下面先根据时间复杂度进行分类分析
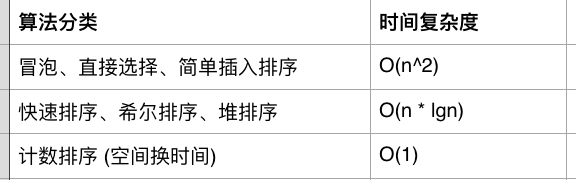
2.1 对于冒泡排序、直接选择排序、简单插入排序,都是需要两两比较的,唯一的不同就是比较完之后处理方式的不同,以及比较顺序的不同,故时间复杂度都为O(n^2)。
(1)冒泡排序:从第1个数开始,两两比较后大数往右移,完了再从第1个数开始新的一轮比较,直到整个序列是有序的。
(2)直接选择排序:从现有无序序列中选出最小的1个数放在序列的首位,然后再从剩余的数中继续选出最小的,直到整个序列有序。选择的时候做两两比较。
(3)简单插入排序:从现有无序的序列中选择一个数,插入到有序序列的合适位置,插入的时候才做两两比较。
2.2 对于快速排序,核心是通过二分法,随机取一个数,比他小的放在左边,比他大的放在右边,递归完成。这样做的好处就是无需每次都两两比较,比较范围会越来越小。时间复杂度为O(n * logn)
2.3 如果可以不受空间的约束,可以考虑通过空间换时间,获得时间复杂度更好的排序算法,就是计数算法。计数算法就是把待排序的数当作数组的索引,放入对应的数组中,按索引从小到大取数即可。
日常较通用的就是交换排序与快速排序算法了。
3 搜索算法
参考
https://www.jianshu.com/p/908f0366e1dc
https://www.jianshu.com/p/95d224c4d13e
https://blog.csdn.net/hao65103940/article/details/89032538
https://blog.csdn.net/yang_yulei/article/details/26066409
搜索、排序不分家,一般搜索都会涉及排序,当然也有无序搜索。总体而言有这么几种常用的搜索算法:顺序搜索、插值搜索、树表搜索等。各种搜索算法的时间复杂度如下所示。
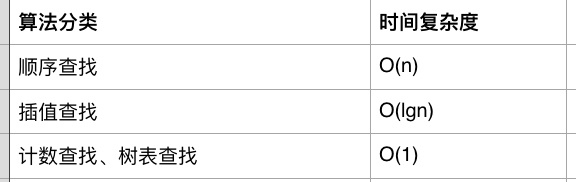
3.1 树表查找
首先从最复杂的树表查找开始讲,说到树查找,不得不先说说广度优先搜索、深度优先搜素。其实这两种搜索算法只是一种图的遍历方式,工程上不见得就是最优的算法,除了要遍历所有的节点还要额外的空间。
广度优先搜索:类似于层序遍历,可以借助队列实现。大致的算法实现步骤如下
1)选择一个顶点作为起始顶点,放入队列中
2)从队列首部取出一个顶点,标记为已读,同时将该顶点的所有相连依次放入队列尾部
3)重复步骤2
深度优先搜索:深度优先搜索更像是一条路走到黑,走不去回到上个路口选择另外一条路继续走,可以借助堆栈实现。
选定一个顶点作为起始顶点,能前进则前进,若不能前进则后退一步继续前进,或者再后退一步选择另一条路前进,依次类推,直到所有顶点都被遍历
对于一颗树而言,最常见的就是二叉树,当然也有多叉树,比如B-tree、B+tree等,总体而言,常见的有二叉树、平衡二叉树、2-3树、红黑树、B-tree、B+tree等,下面一一介绍。
3.1.1 二叉树
左子树的节点值要小于根节点,右子树的节点值要大于根节点。当二叉树的左右两颗子树分布不均匀的时候,要查找某个叶子节点时,需要遍历比较多的节点。只有当左右两颗子树分布均匀的时候,遍历层数才最小,也就是当二叉树平衡的时候。
最差的情况下查找时间复杂度为O(n),最好的时候也是平衡的时候为O(logN)
3.1.2 平衡二叉树
根节点两边子树的最大高度差为1。对于数这种数据结构,树的最大高度就是最大查找次数,所以尽量要减少树的高度,让树保持平衡。
3.1.3 2-3树(2叉-3叉树)
2叉表示1个键值2条链接到子树,3叉表示2个键值3条链接到子树。2-3树是为了高效自平衡的。一颗完美平衡的2-3树,所有空链接(叶子节点)到根节点的距离都是相同的。
2-3树插入节点的方式:先找插入节点的位置,若节点有空(即2叉节点),则直接插入;若节点没有空(即3叉节点),则先插入使其暂时容纳这个元素,然后分裂此节点,把中间元素移到其父节点中,对父节点亦如此处理。(中键一直往上移,直到找到空位,在此过程中若没有空位就先搞个临时的,再分裂)
2-3树在最坏情况下,仍有较好的性能,每个操作中处理每个节点的时间都不会超过一个很小的常数,且这个操作都只会访问同一条路径上的节点。所以任何查找或者插入操作时间成本都不会超过对数级别。
3.1.4 红黑树
平衡二叉树,当插入或者减少节点时容易打破平衡,红黑树就是一种自平衡的二叉树。是对2-3树的标准化,具备标准的2叉树特性,同时又能够自平衡。
红黑树就是用红色链接表示3叉节点的2-3树,所以红黑树的自平衡就转化为了2-3树的自平衡,红黑树插入节点就转为了2-3树插入节点。我们将3叉节点表示为由一条左斜的红色链接相连的两个2叉节点,就是红黑树,所有的红色链接必须左斜。
红黑树的另一种定义是满足下列条件的二叉查找树:
1)红链接均为左链接
2)没有任何一个节点同时和两条红链接相连
3)该树是完美黑色平衡的,即任意空链接到根节点的路径上的黑链接数量相同
3.1.5 B-tree
b-tree是一种平衡多路查找树,为了优化外存储(磁盘等)的查找效率而产生的一种数据结构。磁盘IO的单位是磁盘块,所以要尽量减少IO次数,每个磁盘块中尽量存储多的键值对以及该索引键两边的磁盘块地址,即B-tree是一颗多叉树,尽量减少树的总层高,减少IO次数,提高查询效率。
3.1.6 B+tree
b+tree作为b-tree的一种优化结构,b-tree的每个树节点会存储键-值,b+tree只会存储键,只有叶子节点才会存储键-值,这样b+tree的每个节点就可以存储更多的索引键,进一步降低了树的高度,查询效率会更高。
InnoDB用的就树B+tree索引(分为聚集索引:叶子节点包括了键与整行的数据;辅助索引:叶子节点只有键没有整行数据,需要根据索引键进一步查询聚集索引才能查出整行数据),层高在2~4层,根节点常驻内存,所以一般磁盘IO数为1~3。同时B+tree的叶子节点组成了有序列表,便于区间查找。b+tree与b-tree都属于多叉树。
Innodb存储结构,一个表只有一个聚集索引(主键索引),其他索引都是二级索引,都是非聚集索引。
3.2 插值查找
最经典的就是二分查找,前提是对于有序表。比较适用于静态表,对于动态表的效果不好,因为要不停地排序,时间复杂度会提高。对于动态表的查找可以用平衡二叉树的方式查找,比如红黑树等。
除了二分查找,还有升级版的斐波拉契查找等,就是事先定义一个初始化的查找点,而不是笼统地从(二分)中间位置查找。
插值查找时间复杂度一般为O(logN)
3.3 顺序查找
顺序查找就是字面意思,逐个查找,时间复杂度为O(N)
3.4 哈希查找
如果不在乎空间,可以空间换时间,使用计数查找,之间使用键值作为数值的索引,时间复杂度为O(1)。如果不在乎时间,可以使用顺序查找。而哈希查找正是一个折中,使用适度的空间与时间在这两者之间达到了平衡。通过哈希函数,可以灵活调整查找时间复杂度。当函数非常离散时就相当于是计数查找,当不离散时,就是个链表,相当于顺序查找。
更多算法请听下回分解。
更多精彩内容,欢迎关注
知乎:https://www.zhihu.com/people/mei-an-63
微信:
