搜索
深度优先搜索(DFS)和广度优先搜索(BFS)都是常见的图搜索算法。它们的目的是访问和遍历图中的所有节点,并找到满足特定条件的节点。虽然这两种算法的实现方式不同,但它们都有以下的特点。
首先,DFS 和 BFS 都是无向图或者有向图的通用算法。其次,它们都需要使用一个队列来存放待处理的节点。在 DFS 中,该队列被称为堆栈,而在 BFS 中,该队列被称为队列。无论是哪一种方法,都会访问每个节点,并跟踪已经访问过的节点。
深度优先搜索
深度优先搜索是一种用于查找或遍历树或图的算法。该算法会沿着树的深度遍历树的分支,尽可能深的搜索子树。当节点所对应的分支都已经被访问过了,算法会回溯到之前的节点,继续搜索其他的分支。这样,DFS 会将图中的所有节点遍历一遍。具体实现时,可以使用递归或者栈来实现。
基本套路就是:
- 首先,将节点标记为已访问
- 然后,对于每个未访问的邻居,重复步骤 1
- 最后,回溯到之前的节点
总而言之,DFS 的核心思想是沿着某个路径一直走到底,直到不能再走为止,然后返回最近的一个未访问过的节点,并尝试其他的路径。
广度优先搜索
广度优先搜索是一种用于查找或遍历树或图的算法。该算法从起点开始遍历整张图,首先访问起点的所有邻居节点,然后访问邻居节点的邻居节点,以此类推。换句话说,该算法会先访问距离起点为 1 的所有节点,然后是距离起点为 2 的所有节点,以此类推。
基本套路就是:
- 创建一个队列 Q,将起点入队
- 将起点标记为已访问
- 重复以下步骤,直到队列为空:
- 弹出队首元素 v
- 对于 v 的所有未访问的邻居 w,将其标记为已访问并入队
核心思想就是按照距离从小到大的顺序访问所有节点,并将每个节点标记为已访问过,以确保不重不漏地访问整张图。
此外按照我们的搜索类型,我们还可以将搜索分为连通性搜索和状态搜索
连通性搜索
不需要用重新构造新的节点,在原有的节点的基础上进行搜索的情况,可以归纳为连通性搜索情况。
状态搜索
状态搜索,在这里是指,需要在搜索的过程当中,不断构造新的节点,改变现有状态的一种搜索。
在这一过程当中,存在指数级的状态空间,因此存在大量的优化,例如双向BFS搜索,或者启发式搜索。例如PSO,遗传算法等等,算法竞赛当中常见的有IDA* 和 A*
例题
1. 深度优先搜索(DFS)
1.1 Leetcode 22题 括号生成
链接:https://leetcode.cn/problems/generate-parentheses/
思路如下:
首先,构造用于存储搜索结果的列表 res。接下来,定义一个名为 dfs 的辅助函数,该函数接收三个参数:当前要搜索的字符串 s、左括号数量 left 和右括号数量 right。在函数中,我们需要进行以下操作:
1)如果 left 和 right 都等于 n,则将 s 加入结果集 res,并返回。
2)如果 left 小于 n,则将字符 ‘(’ 加入 s 中,执行递归调用 dfs(s+‘(’, left+1, right)。
3)如果 right 小于 left,则将字符 ‘)’ 加入 s 中,执行递归调用 dfs(s+‘)’, left, right+1)。
最终,我们将调用 dfs 函数,将空字符串和左右括号数量都初始化为 0。通过这种方式,我们可以生成所有由 n 对括号组成的有效括号字符串。
代码实现:
class Solution:
def generateParenthesis(self, n: int) -> List[str]:
res = []
def dfs(s, l, r):
if l == n and r == n:
res.append(s)
return
if l < n:
dfs(s + "(", l + 1, r)
if r < l:
dfs(s + ")", l, r + 1)
dfs("", 0, 0)
return res
1.2 Leetcode 46题 全排列
链接:https://leetcode.cn/problems/permutations/
思路如下:
首先,构造用于存储搜索结果的列表 res。接下来,定义一个名为 dfs 的辅助函数,该函数接收两个参数:当前要搜索的序列 nums和一个用于存储已选数字的集合 visited。在函数中,我们需要进行以下操作:
1)如果 visited 中元素的数量等于 nums 中元素的数量,则将 nums 加入结果集 res,并返回。
2)对于 nums 中的每个元素 num,如果 num 不在 visited 中,则将其加入 visited 中,并执行递归调用
dfs(nums, visited),然后将 num 从 visited 中移除。最终,我们将调用 dfs 函数,并将空列表和空集合作为初始参数。通过这种方式,我们可以生成输入序列的所有排列。
代码实现:
class Solution:
def permute(self, nums: List[int]) -> List[List[int]]:
res = []
path = []
used = set()
def dfs(path, used):
if len(path) == len(nums):
res.append(path[:])
return
for num in nums:
if num not in used:
path.append(num)
used.add(num)
dfs(path, used)
path.pop()
used.remove(num)
dfs(path, used)
return res
1.3 Leetcode 77题 组合
链接:https://leetcode.cn/problems/combinations/

代码实现:
class Solution:
def combine(self, n: int, k: int) -> List[List[int]]:
res = []
path = []
def dfs(start):
if len(path) == k:
res.append(path[:])
return
for i in range(start, n+1):
path.append(i)
dfs(i+1)
path.pop()
dfs(1)
return res
2. 广度优先搜索(BFS)
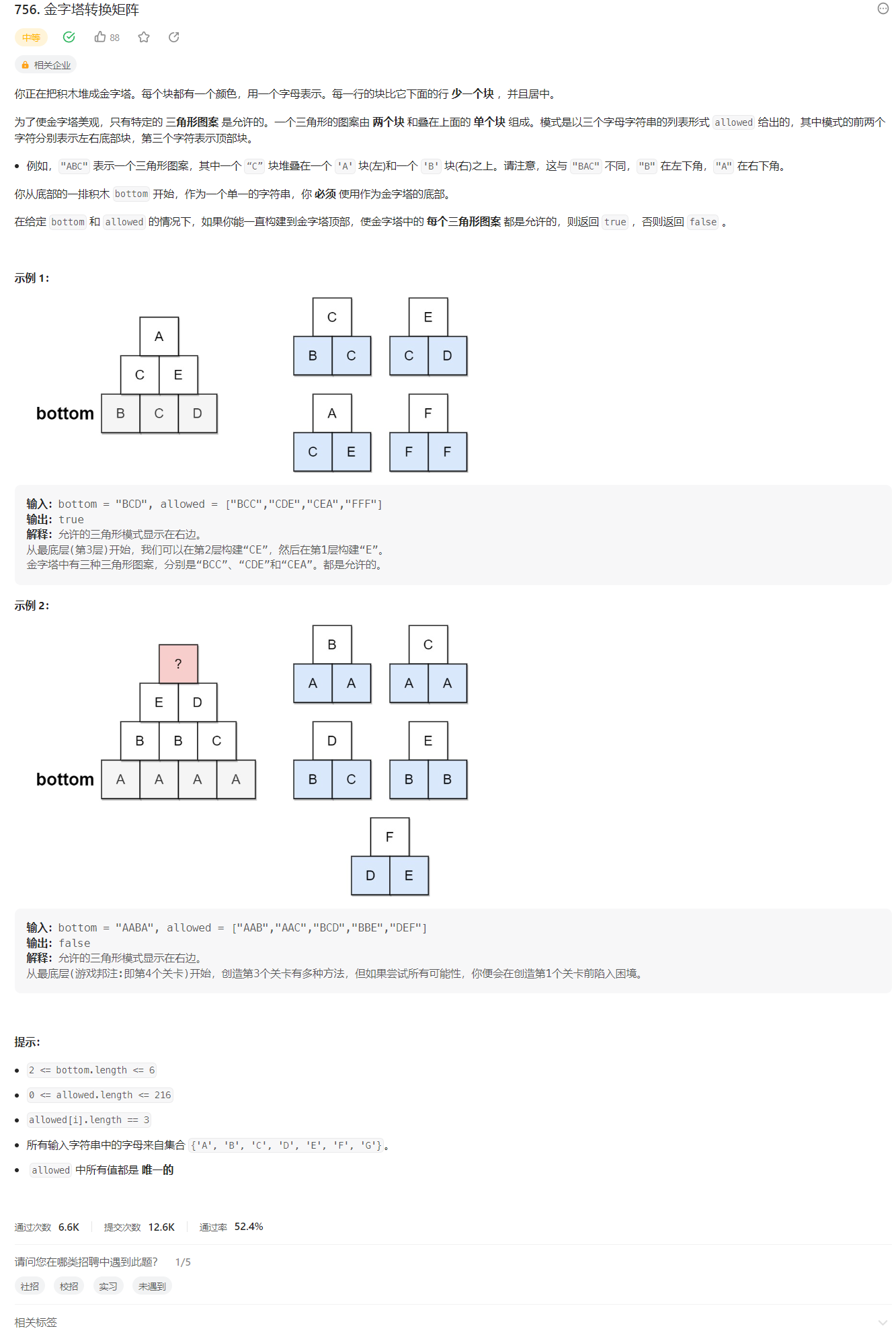
2.1 Leetcode 756. 金字塔转换矩阵
链接:https://leetcode.cn/problems/pyramid-transition-matrix/description/
解题思路:
从底部的每个位置开始,依次向上层逐个扩展,每一步看能否找到两个砖块合并成一个新砖块。如果能够得到底部的最后一行,则说明可以合并出一个砖块,此时将结果加入答案数组。
由于第 i i i 行有 i + 1 i+1 i+1 个砖块,因此最底层共有 2 m 2^m 2m 个位置需要进行一次模拟。对于每个砖块,我们都需要遍历 O ( 1 ) O(1) O(1)
个候选应该放在上方的可能性(注意这个常数实际上比字母表长度还要小),因此总的时间复杂度为 O ( n ⋅ 2 m ) O(n \cdot 2^m) O(n⋅2m)。算法的空间复杂度为 O ( 2 m ) O(2^m) O(2m),即生成的状态数。具体实现中,我们使用了一个字典 a l l o w e d _ d i c t \mathtt{allowed\_dict} allowed_dict 来记录所有可以组成新砖块的候选组合,以及一个队列
q u e u e \mathtt{queue} queue 存储待处理的位置。初始时,将每个底部位置 ( i , j ) (i, j) (i,j) 存入队列中,同时将其作为位置为 i + 1 , j i+1,j i+1,j
和 i + 1 , j + 1 i+1,j+1 i+1,j+1 的砖块的候选组合加入 a l l o w e d _ d i c t \mathtt{allowed\_dict} allowed_dict 中。之后,每次从队列中取出一个位置 ( i , j ) (i, j) (i,j),并枚举其上方的两个位置 ( i − 1 , j ) (i-1,j) (i−1,j) 和 ( i − 1 , j + 1 ) (i-1,j+1) (i−1,j+1)。如果可以通过
a l l o w e d _ d i c t \mathtt{allowed\_dict} allowed_dict 找到它们对应的组合 ( a , b ) (a,b) (a,b) 并将其合并为新砖块,则将 ( i − 1 , j ) (i-1,j) (i−1,j)
存入队列中,并且在 a l l o w e d _ d i c t \mathtt{allowed\_dict} allowed_dict
中记录以新砖块为下方的可行组合。最后,如果队列为空时还没有找到可以合并的砖块,则返回空数组。
解题代码:
from collections import deque
class Solution(object):
def pyramidTransition(self, bottom, allowed):
"""
:type bottom: str
:type allowed: List[str]
:rtype: bool {ab:[c,d]}
"""
maps = {
}
for all in allowed:
if (maps.get(all[:2])):
maps[all[:2]] += all[2]
else:
maps[all[:2]] = all[2]
return self.bfs(bottom,maps)
def bfs(self,bottom,maps):
q =[]
q.append(bottom)
used = {
}
while(len(q)):
t = q.pop(0)
if(used.get(t)):
continue
if(len(t)==1):
return True
temp = []
flag = True
#由当前的小s扩展到新的小s
for j in range(len(t)-1):
b_k = t[j:j+2]
b_t = maps.get(b_k)
if(not b_t):
flag = False
break
temp.append(b_t)
#现在要组装小s
if(flag):
ns = []
self.dfs(temp,0,[],ns)
for s2 in ns:
q.insert(0,s2)
used[t] = 1
return False
def dfs(self,temp,i,path,ns):
if(i==len(temp)):
ns.append("".join(path))
return
for c in temp[i]:
path.append(c)
self.dfs(temp,i+1,path,ns)
path.pop()
2.2 Leetcode 127题 单词接龙
链接:https://leetcode.cn/problems/word-ladder/

解题思路:
首先,我们需要转换输入的单词列表为一个 set 类型的变量 word_set,以便后续快速查找某个单词是否在列表中。接下来,定义一个队列
queue 和一个集合 visited,将 beginWord 加入队列,并将其加入 visited 中。对于每个单词 node
在队列中,我们需要进行以下操作:1)遍历该单词的所有邻居(即只相差一个字符的单词),如果邻居中存在 endWord,返回当前深度(即转换序列的长度)。
2)如果邻居不在 visited 中,则将其加入队列和 visited 中。
最终,如果未能找到最短转换序列,则返回 0。
代码实现:
class Solution:
def ladderLength(self, beginWord: str, endWord: str, wordList: List[str]) -> int:
if endWord not in wordList or not beginWord or not endWord or not wordList:
return 0
wordSet = set(wordList)
q = collections.deque()
q.append((beginWord, 1))
visited = set()
visited.add(beginWord)
while q:
cur_word, level = q.popleft()
if cur_word == endWord:
return level
for i in range(len(cur_word)):
for j in range(26):
new_word = cur_word[:i] + chr(j+97) + cur_word[i+1:]
if new_word in wordSet and new_word not in visited:
q.append((new_word, level+1))
visited.add(new_word)
return 0
2.3 Leetcode 126题 单词接龙 II(选做)
链接:https://leetcode.cn/problems/word-ladder-ii/

(可以使用双向队列进行搜索,但是这边选择了建图,然后使用spfa算法)
from collections import defaultdict
from typing import List
class Solution:
def findLadders(self, beginWord: str, endWord: str, wordList: List[str]) -> List[List[str]]:
# 将单词列表转化为集合,方便后续判断单词是否在列表中
word_set = set(wordList)
# 特判:如果终点不在列表中,则无法到达
if endWord not in word_set:
return []
# 建立单词的通用状态字典
# key 为通用状态,value 为所有具有该通用状态的单词
generic_dict = defaultdict(list)
for word in word_set:
for i in range(len(word)):
# 将单词的第 i 个字符替换为通配符 '*'
generic_word = word[: i] + '*' + word[i + 1:]
generic_dict[generic_word].append(word)
"""
{
'*ot': ['hot', 'dot', 'lot'],
'h*t': ['hot'],
'ho*': ['hot'],
'd*t': ['dot'],
'do*': ['dot', 'dog'],
'cog': ['cog', 'log']
}
"""
# 记录每个单词的前驱节点
prev_dict = {
}
# 记录起点到达每个单词的最短路径长度
distance_dict = {
}
# 初始化所有单词的距离为正无穷
for word in word_set:
distance_dict[word] = float('inf')
# 将起点加入队列,并初始化距离为 0
queue = [(beginWord, 0)]
distance_dict[beginWord] = 0
# 广度优先搜索算法(spfa)
while queue:
cur_word, cur_depth = queue.pop(0)
# 如果已经到达终点,则停止搜索
if cur_word == endWord:
break
# 枚举当前单词的所有通用状态
for i in range(len(cur_word)):
# 将单词的第 i 个字符替换为通配符 '*'
generic_word = cur_word[: i] + '*' + cur_word[i + 1: ]
# 遍历所有具有该通用状态的单词
for word in generic_dict[generic_word]:
# 如果与当前单词不同
if word != cur_word:
# 如果未访问过
if distance_dict[word] == float('inf'):
# 将其加入队列,并更新距离和前驱节点
queue.append((word, cur_depth + 1))
distance_dict[word] = cur_depth + 1
prev_dict[word] = [cur_word]
# 如果已经访问过,并且当前距离与之前记录的距离相等
elif distance_dict[word] == cur_depth + 1:
# 将当前单词作为新的前驱节点
prev_dict[word].append(cur_word)
# 还原最短路径
res = []
path = []
# 从终点开始还原路径
def dfs(word: str):
# 将当前单词加入路径中
path.append(word)
if word == beginWord:
# 如果已经回溯到起点,则将路径反转,并加入结果集
res.append(path[::-1])
elif word in prev_dict:
# 否则,遍历所有前驱节点
for prev in prev_dict[word]:
dfs(prev)
# 回溯时,将当前单词弹出路径
path.pop()
dfs(endWord)
return res