基于真实世界的数据集的深度强化学习
前言
本文的讲座来自于英伟达GTC大会
首先附上原视频链接https://register.nvidia.com/flow/nvidia/gtcspring2023/attendeeportal/page/sessioncatalog/session/1666649323930001EDPn
机器学习大规模成功的共同要素是使用大量模型和大量的GPU训练,大多数的数据集都是有标签的数据集,虽然在传统意义上可以获得很好的效果,但是大多GPU训练都需要很高的花费和大型的数据集。
然而进近几年未标记的数据运用越来越多,是现在机器学习非常重要的一部分,这就自然引入了强化学习技术,强化学习是直接推理决策及其后果的机器学习框架。然而,将强化学习与大多数现代机器学习系统运行的数据驱动范式相协调是很困难的,因为经典形式的强化学习是一种主动的在线学习范式。我们能否获得两全其美的优势——监督或无监督学习中的数据驱动方法可以利用以前收集的大型数据集,以及强化学习的决策形式主义,可以对决策及其后果进行推理?下文将介绍离线强化学习如何使其成为可能,离线强化学习如何从次优多任务数据、现实世界领域中的广泛泛化以及机器人和对话系统等设置中引人注目的应用程序实现有效的预训练。
一、离线强化学习基础
离线强化学习是指在没有与环境交互的情况下,使用之前收集的经验数据进行强化学习。与在线强化学习不同,离线强化学习可以通过分析存储的历史数据进行训练,而无需与环境进行交互。下文用RL来代替强化学习(Reinforcement Learning)
1.1 离线RL和模仿学习对比
从绿点到红点,模仿学习就只能重复轨迹,离线RL可以从混乱的轨迹中获得一个最优的轨迹。

离线RL学习可以采用数据集中每部分的优点来达到整体最优。
1.2 Conservative Q-learning
此算法和对抗训练有些相似,如下图,假设绿色曲线是真实函数,蓝色曲线是Q拟合函数,Q拟合函数试图找到绿色的真实曲线。
第一行公式为正则化曲线,它试图找到具有高Q值的对抗分布,并最小化该分布下的Q值,它能够发现这些高估点并将它推低,可以很好的防止过度估计。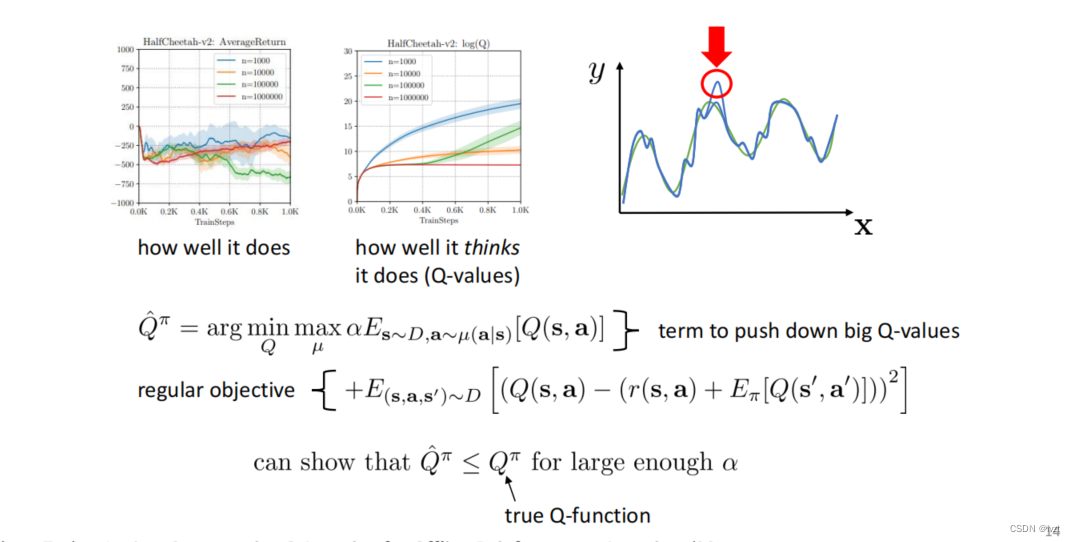
下图是利用这个算法的一个示例:
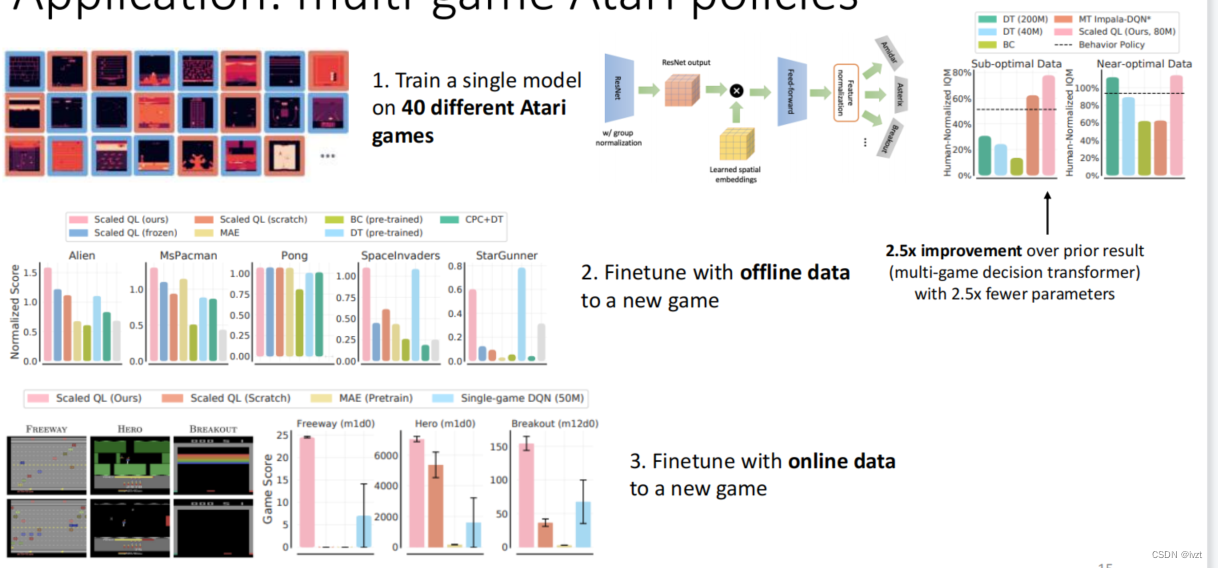
利用这一算法训练的单一神经网络取得了很好的效果。
1.3 PTR
PTR是以简单的方式对bridge数据集中的所有任务训练的一个策略。
对整个数据集进行预训练,然后针对新任务进行了10次训练,然后将在回收bridge数据集中的数据时进行微调,防止遗忘。并且使用热向量中的最后一个缩影来表示新的任务。
二.机器人技术的离线RL预训练
2.1 PTR
PTR是以简单的方式对bridge数据集中的所有任务训练的一个策略。
对整个数据集进行预训练,然后针对新任务进行了10次训练,然后将在回收bridge数据集中的数据时进行微调,防止遗忘。并且使用热向量中的最后一个缩影来表示新的任务。

并且离线的RL训练有助于提高PTR的性能

三.大型语言模型的离线RL
在进行训练之后采用,视觉对话进行评估,这体现资料离线RL可以在使用过程中数据来找出如何优化。
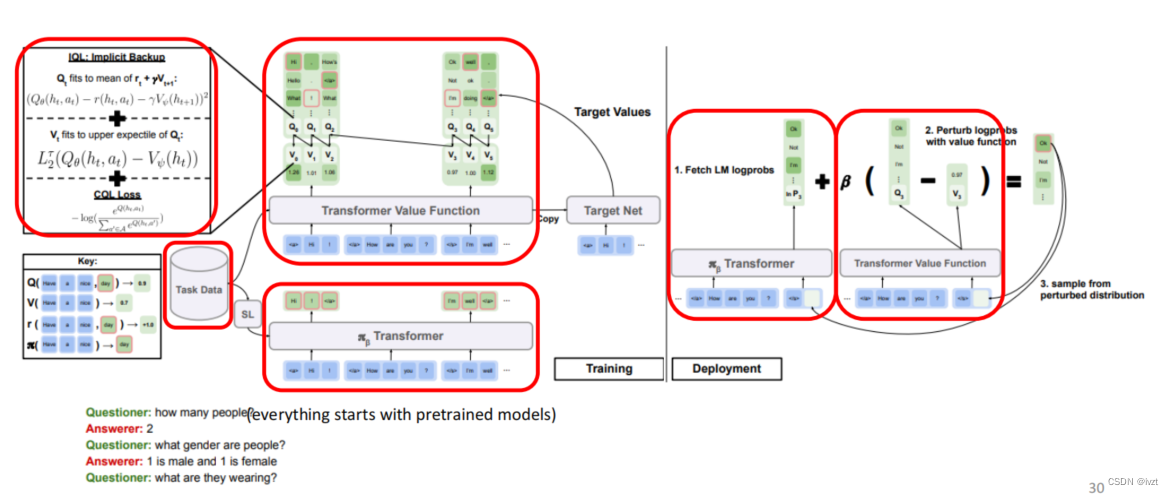
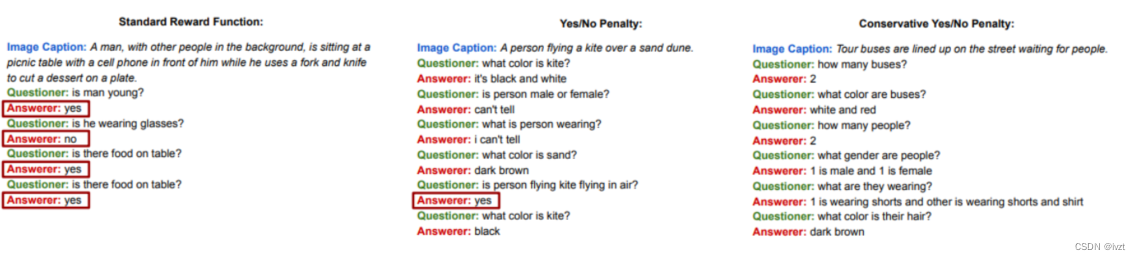
四.离线RL对人类的影响
通过观察人与人之间的玩耍,找出如何影响人类的行为,所有的辅助资料的可以了解到人类如何意外地相互影响。

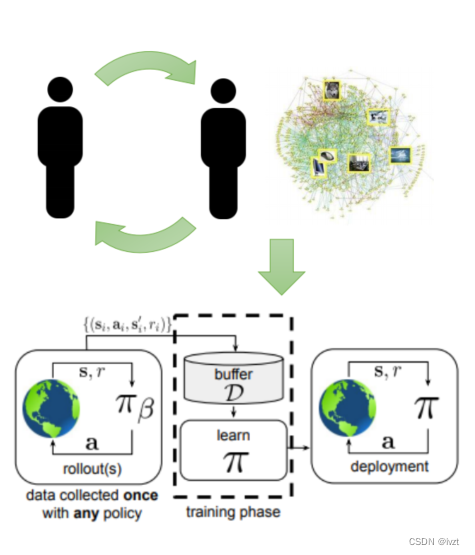
同时机器人也可以影响人类的行为,更大的数据集将使它能够识别更加微妙的模式。