论文题目: Double Critic Deep Reinforcement Learning for
Mapless 3D Navigation of Unmanned Aerial Vehicles
作者: Ricardo Bedin Grando1, Junior Costa de
Jesus2, Victor Augusto Kich3, Alisson
Henrique Kolling3, Paulo Lilles Jorge Drews-Jr2
论文链接: https://arxiv.org/pdf/2112.13724v1.pdf
一、概述
解决问题: 提出了一种新的基于深度强化学习的无人机三维mapless导航系统。没有使用基于图像的传感方法,提出了一个简单的学习系统仅使用来自距离传感器的少量稀疏范围数据来训练学习代理。
方法: 基于两种最先进的双批评家深度RL模型:双延迟深度确定性策略梯度(TD3)和软参与者批评家(SAC)。两种方法优于基于深度确定性策略梯度(DDPG)技术和BUG2算法的方法。此外基于递归神经网络(RNN)的新深度RL结构优于当前用于执行移动机器人mapless导航的结构。
结论: 基于双批评和递归神经网络(RNN)的深度RL方法更适合执行无人机的mapless导航和避障。提高了机器人避障的能力。
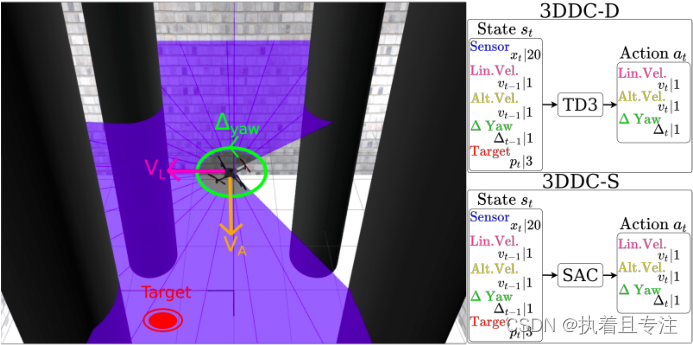
二、算法原理
无人机系统可以学习从空间上的起始位置导航到目标位置,并通过一系列目标点,在有障碍的环境中建立自己的运动计划。只需要两个距离传感数据和无人机的相对定位数据来执行mapless导航和避障。运动方程为:vt = f(xt, pt, vt-1); 其中xt为传感器读数的原始信息,pt是相对位置和角度,vt-1是无人机上一时刻速度。该模型允许获得机器人能够做出的动作,给定其当前状态st。体现在神经网络中,预期结果是当前状态的动作。
1、网络架构
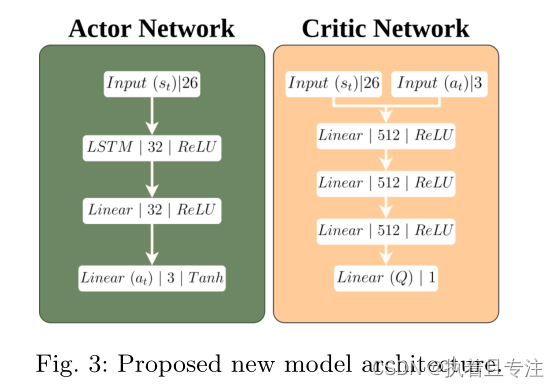
网络包含26个输入和3个输出的结构。在26个输入中,20个表示来自模拟激光雷达的距离发现,3个表示用于无人机以前的动作,其他3个表示有关目标的信息。激光雷达在270°范围内提供1080个样本,其中20个以13.5°等距采样。使用的目标信息是无人机与目标的相对距离和与目标的两个相对角度。网络的输出提供了给定步长的动作,即线性速度和高度速度以及偏航角的变化。然后将这些动作应用于无人机。如下图:

网络架构具有32单元LSTM层,用于使用ReLU功能激活的actor网络。双曲正切函数用作actor输出中的激活函数。线性速度的值在0到0.25 m/s之间缩放,delta yaw在-2.5到2.5rads。高度速度为-0.25和0.25 m/s。当前状态和代理执行的操作的Q值在批评网络中给出。对于基于SAC的方法,价值网络的结构与批评家网络相同。
2、奖励函数
只有两种奖励,一种是正确完成任务,另一种是失败。当目标在cd米的边距内达到时,代理收到100的正奖励。该边距设置为0.5m表示误差。另外在与障碍物或场景限制碰撞的情况下,我们给出了一个负奖励−10。如果距离传感器的读数低于0.5米的距离co,则验证碰撞。这种简化的奖励系统也有助于关注深度RL方法本身,而不是关注环境。
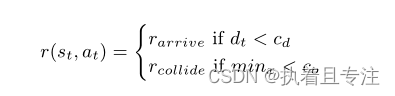
三、实验结果
使用了两个环境来训练和测试我们的代理。第一个环境基本上是一个边长10米的盒子,有自由空间来执行导航。第二个环境与第一个环境相同,但添加了4个固定障碍。设置这些障碍物是为了代表工业场景中的钻井立管,在工业场景中可以应用这种方法。两种环境都有5×5m的面积,如图5所示。蓝线是无人机的传感器光线。还使用了模拟风来增加难度。在三轴上使用Ornstein-Uhlenbeck噪声模拟风,速度设置为−0.175至0.175米/秒。对于室内环境而言,这相当高,相当于无人机可以达到的最大速度的70%。从经验上看,更高的值使场景几乎不可行,而较低的值对整体结果没有太大影响。
在第一个任务(导航任务)中,车辆应该从空间中的一个点导航到另一个点,而在第二个任务(航路点导航任务)中,应该访问多个点。在测试和评估期间,在两项任务中都使用了模拟风。此外,还针对每种场景培训了一名代理。在两种情况下对这两项任务分别进行了总共100次的评估。成功轨迹的总数表示无人机在其中导航的百分比。 具体数据见原文。
在训练阶段,从奖励中收集数据。我们收集了第一个场景中1000集和第二个场景中1500集的数据。训练的最后一集是根据所获得的平均奖励的停滞来选择的。下图分别显示了第一个和第二个场景中前300集的奖励移动平均值。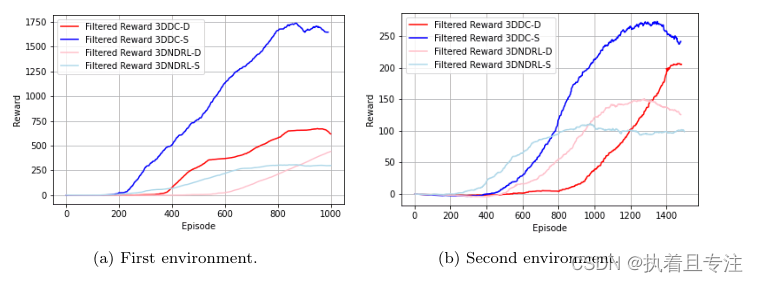
结论: 具有双批评者和RNN的方法比具有全连接人工神经网络的最先进方法更适合,通常用于地面移动机器人。提出的系统能够通过仅使用无人机的相对定位数据和一些距离发现来执行导航相关任务,而不使用基于图像的传感,这可能需要昂贵的硬件能力来实现良好的性能。基于双评论家-演员-评论家SAC和TD3算法的方法也设法绕过障碍物并达到预期目标,新方法优于基于DDPG的方法和BUG2算法。取得的良好结果可以归功于一个简单的基于感知的结构和一个简单的奖励系统。
内容来源于参考论文整理,侵权联系删。
未尽事宜可阅读原文,欢迎关注!
