1.TensorRT 下载
TensorRT 各个版本的下载网址(用这个网址可以跳过 老黄的调查问卷):
https://developer.nvidia.com/nvidia-tensorrt-8x-download
https://developer.nvidia.com/nvidia-tensorrt-7x-download
https://developer.nvidia.com/nvidia-tensorrt-6x-download
主要是 for linux 也有windows
很奇怪 TensorRT 7.x 和 TensorRT 6.x 里没有python 文件夹
最后我在TensorRT 8.x 里发现
TensorRT-8.2.1.8.Windows10.x86_64.cuda-10.2.cudnn8.2 可以使用
最后用了这版,我的笔记本显卡是1660Ti
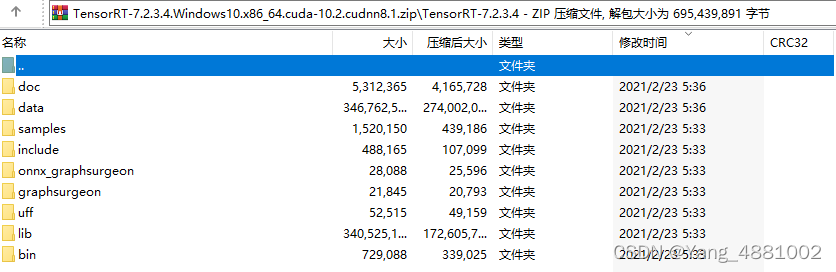
TensorRT-7.2.3.4.Windows10.x86_64.cuda-10.2.cudnn8.1文件内容:
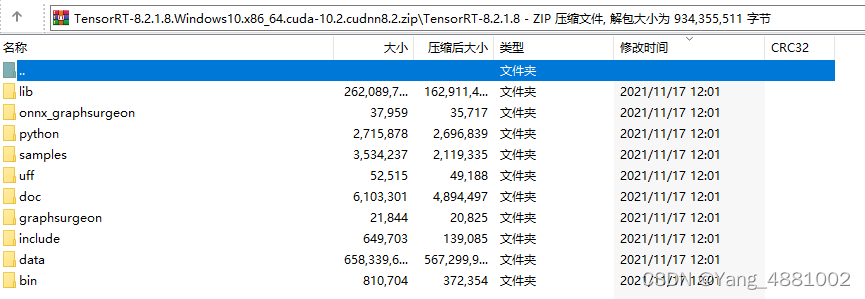
TensorRT-8.2.1.8.Windows10.x86_64.cuda-10.2.cudnn8.2文件内容:
2.安装
一开始安装我参考了他的,感谢作者~,但又不太一样,我改进优化了一下:https://blog.csdn.net/hhhhhhhhhhwwwwwwwwww/article/details/120360288
- 2.1 配置环境:
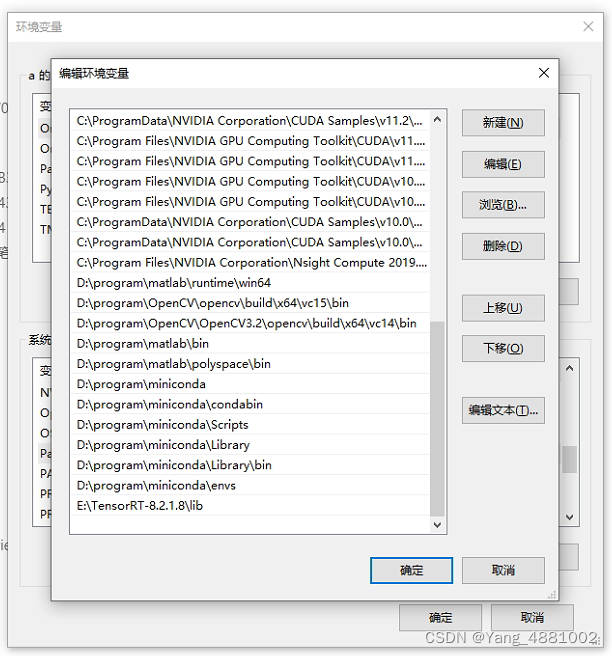
将下载好的文件解压到一个安静的磁盘位置,然后将“X:\TensorRT-7.2.3.4\lib”添加环境变量。 环境变量位置: 此电脑图标–右键属性–高级系统设置–高级–环境变量–系统变量–path
- 2.2 安装必要的whl文件
安装 graphsurgeon、uff、onnx_graphsurgeon, 如下图所示:
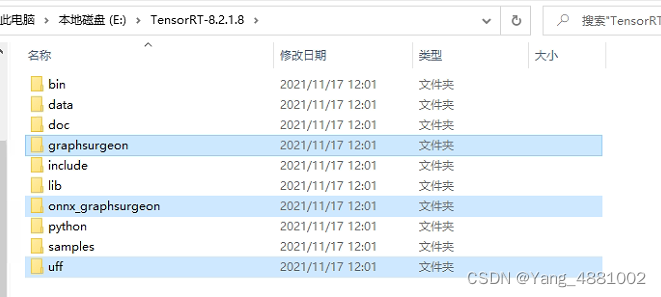
安装方法是用Anaconda Prompt cd到这三个文件夹下 然后再安装,如下图所示:
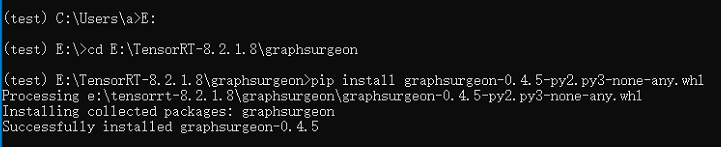
记得激活需要安装的虚拟环境
如果 onnx_graphsurgeon 安装失败

可以用以下命令:
pip install onnx_graphsurgeon-0.3.12-py2.py3-none-any.whl -i https://pypi.tuna.tsinghua.edu.cn/simple
-
2.3 安装python 版本的tensorrt-8.2.1.8
关键的来了,找到TensorRT里的python文件夹,找到对应环境的python版本,进行安装:
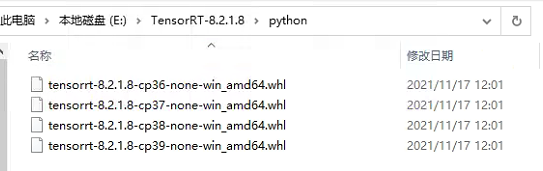
-
2.4 复制dll文件到cuda安装目录
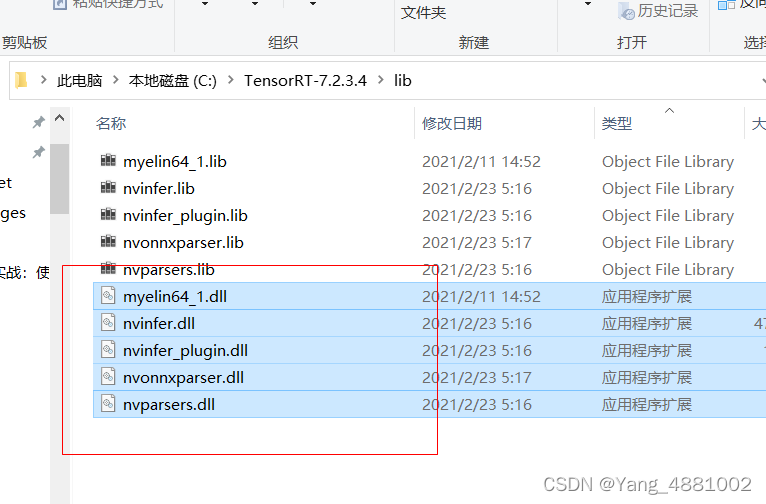
复制到:C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin 下
到这里就安装完成了,需要测试一下。
3.测试
简单测试一下
import tensorrt as trt
print(trt.__version__)

这样就没问题了
4.运行
将.pt转换为.engine
.pt --> .onnx -->.engine
注:这里是用yolov5 源码里的export.py转的
转换后的.engine 可以在win10平台上使用
一个轻量模型 可以从 一张图片 0.008s提速到0.004s,从 125帧/s 提升到 250帧/s,大约2倍(估计本来就快)
5.TensorRT-优化-原理
TensorRT优化方法主要有以下几种方式,最主要的是前面两种。
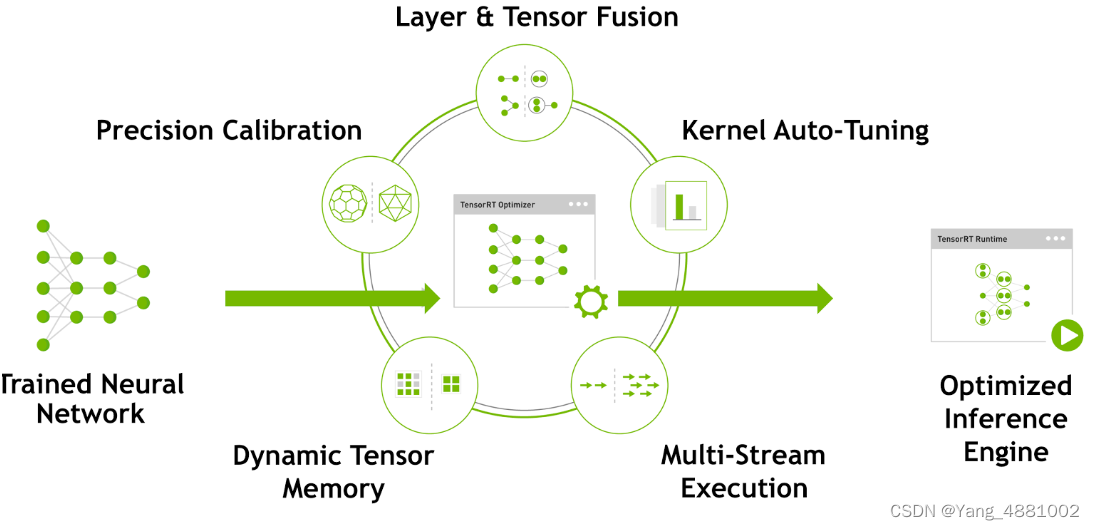
- 层间融合或张量融合(Layer & Tensor Fusion)
如下图左侧是GoogLeNetInception模块的计算图。这个结构中有很多层,在部署模型推理时,这每一层的运算操作都是由GPU完成的,但实际上是GPU通过启动不同的CUDA(Compute unified device architecture)核心来完成计算的,CUDA核心计算张量的速度是很快的,但是往往大量的时间是浪费在CUDA核心的启动和对每一层输入/输出张量的读写操作上面,这造成了内存带宽的瓶颈和GPU资源的浪费。TensorRT通过对层间的横向或纵向合并(合并后的结构称为CBR,意指 convolution, bias, and ReLU layers are fused to form a single layer),使得层的数量大大减少。横向合并可以把卷积、偏置和激活层合并成一个CBR结构,只占用一个CUDA核心。纵向合并可以把结构相同,但是权值不同的层合并成一个更宽的层,也只占用一个CUDA核心。合并之后的计算图(图4右侧)的层次更少了,占用的CUDA核心数也少了,因此整个模型结构会更小,更快,更高效。

- 数据精度校准(Weight &Activation Precision Calibration)
大部分深度学习框架在训练神经网络时网络中的张量(Tensor)都是32位浮点数的精度(Full 32-bit precision,FP32),一旦网络训练完成,在部署推理的过程中由于不需要反向传播,完全可以适当降低数据精度,比如降为FP16或INT8的精度。更低的数据精度将会使得内存占用和延迟更低,模型体积更小。
| Precision | Dynamic Range |
|---|---|
| FP32 | −3.4×1038 +3.4×1038−3.4×1038 +3.4×1038 |
| FP16 | −65504 +65504−65504 +65504 |
| INT8 | −128 +127−128 +127 |
INT8只有256个不同的数值,使用INT8来表示 FP32精度的数值,肯定会丢失信息,造成性能下降。不过TensorRT会提供完全自动化的校准(Calibration )过程,会以最好的匹配性能将FP32精度的数据降低为INT8精度,最小化性能损失。
第5部分来源:
TensorRT-优化-原理
补充
1.如果还需要安装pycuda 如下安装网址:
https://www.lfd.uci.edu/~gohlke/pythonlibs/#pycuda
2.如果转yolov5 的.pt权重遇到了这个问题:
Could not load library cudnn_cnn_infer64_8.dll. Error code 126
Please make sure cudnn_cnn_infer64_8.dll is in your library path!

可以参考这个老哥的方法:
https://blog.csdn.net/illumiD/article/details/123266661
成功有效,比换版本的方便多了
成功!