-
什么是单目深度估计?
-
青铜:在图片当中,深度就是距离,所以深度估计就是距离估计。这个距离,指的是图片当中每一个像素点和相机(摄像头)之间的距离。
白银:对于单目深度估计,输入的是一张图片,输出的是图像中每个像素点的深度值。即通过神经网络对输入的图像进行特征提取,最后逐一的对每个像素点做一个回归,预测出每一个像素点离相机的距离。 深度估计要做啥?
-
输入一张彩色图片
输出深度估计

也就是说,输入一张彩色的图片,输出的则是这个彩色图片中每个像素点的深度值,也就是距离值。
论文:Monocular Depth Estimation Using Laplacian Pyramid-Based Depth Residuals(基于拉普拉斯金字塔深度残差的单目深度估计)
第一招:特征提取网络结构设计(backbone)
整体结构图:
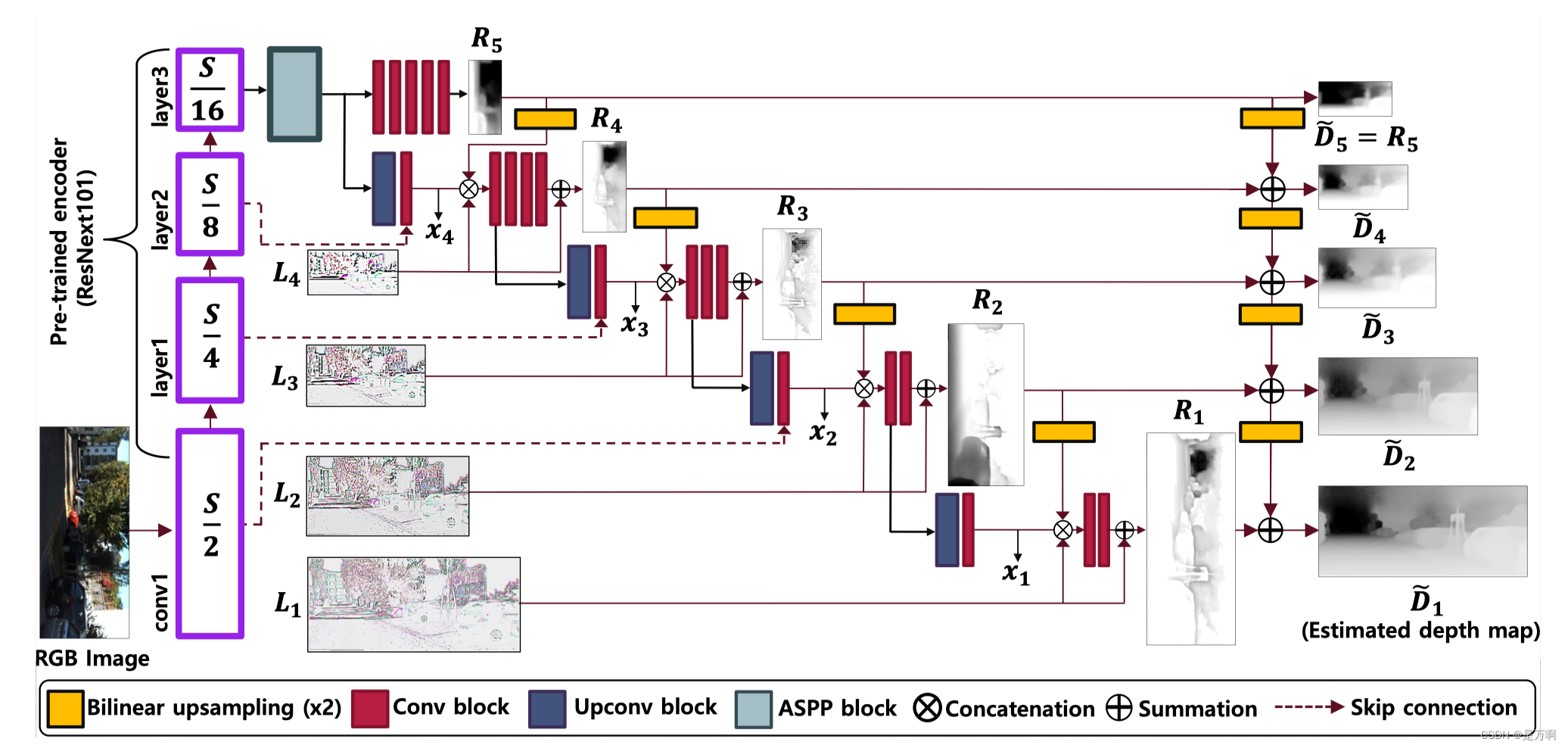
分解整体结构图:

解前小故事:有这样一道数学题 − 2 5 + 3 4 -\frac{2}{5}+\frac{3}{4}\ −52+43
对于一年级的我来说:这是啥?看不懂
对于二年级的我来说:有点印象,但是不会做
对于六年级的我老说:就这?然后做出结果
也就是说,我们对于某一件事,在不同的年龄阶段,对它的看法是不一样的。
对于本文的提取特征的网络结构,同样有这样的思想。即对于一张输入的彩色图片(某一件事),把特征提取过程分为几段去看(不同的年龄阶段),则每段的含义是不一样的(不同的看法)。
疑问一:为什么要把特征提取过程分为几段去看???
如上分解整体结构图,在对输入的彩色图像(SXSX3)进行卷进的过程中,我们要做很多次的卷积操作。而在不断卷积的过程中,我们把特征图是原始输入图像的1/2、1/4、1/8和1/16的特征图把它单独拎出来。而这拎出来的特征图,另作他用。
注:S/2是输入图像1/2倍大小的特征图尺寸,有可能是第10次提取特征得到特征图的大小,也有可能是第20次提取特征图的大小,但不是第S/2次提取特征的提取次数。
解决疑问一:是为了得到在提前特征的过程中,得到特征的多样性(后面还有其他的特征多样性)。即,在特征提取的过程中,比如第10次卷积操作得到的特征图,只能得到一些浅层的特征,比如图片的纹理或者边缘的特征信息。而在做第20次卷积的时候,得到的特征就会比第10次得到的特征更加的深,那么得到的特征信息也会更加的深层。
传统网络在做卷积的时候,就是不断的卷积,不断的卷积,然后在最后一次卷积之后接一个全连接层,然后再把全连接层里面节点拉长,转变成一维,最后输出一个结果,完成图片分类或者图片识别的任务。
而在本文中,则是把图像在不断卷积的过程中,产生的特征信息给它抽离出来,抽离出来以后,一是实现特征的多样性(后面还有多样性的体现),二是这些抽离出来的特征还要再后续进行特征融合的过程中,提供参考或者直接参加。
第一招总结:得到各个层级的特征,也就是得到backbone中不同层次的特征。
而每做一次卷积,就会得到一些特征图,所以我们可以取:做S/2次卷积的时候,把它所得到的特征图单独拎出来;做S/4次卷积的时候,也把它所得到的特征图给拎出来;同理,S/8和16/S次的特征图,也都单独拎出来。而拎出来的特征图,另作他用。
举个例子,取输入彩色图像尺寸是224X224,则在对该图像进行特征提取的过程中,把112大小的特征图单独拎出来,把56大小的特征图单独拎出来,把28大小的特征图单独拎出来,把14大小的特征图单独拎出来。
第二招:处理差异
何为差异?
对于一副图像来说,求图像中各个物体离相机的距离的前提,就是要把图像中各个物体识别出来,然后才知道这个车离我相机多远,那个行人离我相机多远。所以如何把图像中各个物体识别出来呢?
或者,换个说法,对于一副图像中的像素点,我怎么知道这个像素点是这个物体的边界像素点,还是这个物体的内部像素点呢?也就是对于这幅图像来说,怎么通过神经网络去实现图像中物体轮廓信息的判别。
也就是图像中各个物体之间的区别,或者它们的轮廓信息该怎么表示。有点类似图像分割任务中,怎么实现对图像中物体的分割。
本文用的方法就是“差异”。这个差异,有点类似“相减”的感觉。
如图,红色框出来的部分:
 具体步骤:回顾前面第一招中所说,S/2是输入图像1/2倍大小的特征图尺寸,同理可知S/4、S/8、S/16依次是图像1/4倍大小、1/8倍大小、1/16倍大小的特征图尺寸。这些都是通过下采样得到的。
具体步骤:回顾前面第一招中所说,S/2是输入图像1/2倍大小的特征图尺寸,同理可知S/4、S/8、S/16依次是图像1/4倍大小、1/8倍大小、1/16倍大小的特征图尺寸。这些都是通过下采样得到的。
现在做这样一件事,把S/16大小的一批特征图(记为S16A)进行一次卷积,得到另一批特征图大小依然为S/16(记为S16B)。然后,把S/16大小的另一批特征图(S16B)做上采样。上采样的目的,一是为了得到更多的特征,二是把S/16大小的特征图乘2,变为S/8大小的特征图。所以就可以得到一批特征图大小尺寸为S/8的特征图,记为S8B,而以前的记为S8A。然后差异L4
就为:
L 4 = S 8 A − S 8 B L_4=S_{8A}-S_{8B} L4=S8A−S8B
继续把S8B做上采样操作,得到S4B。则差异L3为:
L 3 = S 4 A − S 4 B L_3=S_{4A}-S_{4B} L3=S4A−S4B
把S4B做上采样操作,得到S2B;把S2B做上采样操作,得到S1B。则得到差异L2和L1为:
L 2 = S 2 A − S 2 B L_2=S_{2A}-S_{2B} L2=S2A−S2B
L 1 = S 1 A − S 1 B L_1=S_{1A}-S_{1B} L1=S1A−S1B
简单理解下采样与上采样。下采样就是把特征图的大小缩小n(这里n取2)倍,而上采样就是把特征图扩大n(这里n也取2)倍,有点类似滑动步长为2的池化操作。
第二招总结:通过差异的方法,提取图片中物体轮廓的信息。而差异计算方式就是通过上、下采样得到大小尺寸相同的特征图,然后让它们直接相减求得。而之所以有L1、L2、L3和L4这么多的差异计算,就是为了得到不同尺度的差异,进而更好算出图片的深度信息(只提一个尺度的差异也行,但是最后的结果,即边界信息就会很模糊,如下图)。

第三招:ASPP
招前招之SPP:
目的:为了特征的多样性(宽度)。
在提取特征的时候,一是可以从延长“长度”的角度提取更多的特征,即延长网络的层数,比如第一招中,对输入的彩色图片提取很多次特征,然后拿出其中四次的特征图做运算,这个是在长度方面实现特征的多样性。
其实,还有一种是通过扩大“宽度”的方式,来获取图片的更多特征。
举个例子,我们在描述对一个人的看法的时候,可以说她长得高,瘦,头发长,皮肤白等,这些描述都是从对这个人的外观进行描述,感觉有点片面了。我们还可以从多个角度去描述,比如性格、待人接物等等的角度去描述她,这样通过“多样性”的描述,可以让她变得更加的立体。
同理,本文中,从扩大“宽度”的方式来获取特征的多样性,就是通过不同的池化方法来实现。
以往池化操作(比如最大池化),就是通过指定一个区域大小(比如2X2),然后通过在特征图上滑动的方式(比如滑动步长为2),把指定区域里面的最大值选出来,然后把该值输出到下一层网络中。
而SPP,和以往的池化过程相反。以往的池化,是先指定池化窗口的大小和池化的滑动步长,比如池化窗口大小是2X2或者4X4,滑动步长为2,则大小为240X240的特征图,经过2*2的池化后,变成了120X120;而经过4X4的池化后,变成了118X118,所以在以往的池化操作中,使用不同的池化窗口,最后得到的特征图大小是不一样的。
而在SPP中,正好相反,它是通过池化操作得到一个确定的特征图大小。所以,在SPP中,既不考虑池化窗口的大小,也不考虑池化操作的步长,它的关注点就是最后的池化结果。
举个例子,假如输入特征图尺寸大小有100X100的,有120X120的,还有1125X125的三种尺寸,但是对于SPP来说,都无所谓,SPP只是要求这些不同尺寸的特征图在经过池化操作以后,变为固定的尺寸,比如60X60,或者40X40、30X30(得到不同尺寸的特征图,也是特征多样性的体现)。
对于SPP来说,由于它不关心输入特征图尺寸,只关注池化输出后特征图的尺寸,所以它不会限制输入初始图像的大小尺寸。比如,在以往的AlexNet网络中,要求图像大小为227X227;在VGG网络和GoogLeNet网络中,要求输入图像大小为224X224,而之所这些网络会对输入图像尺寸有要求,就是因为这些网络的最后几层有全连接层,所以为了全连接层的需要,这些网络就需要对输入的图像尺寸有这些限制。
而为了满足网络模型对输入图像尺寸的要求,通常在第一步输入图像的时候做一个reshape操作,即手动完成图像大小的改变。比如一张图像本来的尺寸为100X200,然后通过reshape操作,就可以把该图像转换为224X224大小。等于一开始一张长方形的输入图像,为了满足网络模型的需要,最后变成了正方形。
虽然满足了网络模型需要,完成了图像尺寸大小的改变,但这也必然图像本身带来影响,比如会丢失一些特征。小图像适应大尺寸还好,只需要填充一些灰度值;如果本来是大图像,为了网络的需要,去适应小尺寸的输入,则通过reshape以后,大图像中的像素点必然会被压缩,自然会丢失原本图像的很多信息。
SPP,它并不关心图像的输入尺寸大小,只专注于结果。如果结果需要最后的池化大小是20X20或者30X30,则不管输入图像尺寸为多少,它最终经过一系列卷积池化以后,得到的就是20X20或者30X30。
总结:SPP是做池化的。只专注结果的池化操作。优点一:可以做多种不同的池化,所以可以得到更加丰富的特征,即特征多样性(宽度)。优点二:对输入图像的尺寸大小没有要求,所以不需要对输入图像做reshape操作,进而防止丢失图像特征信息。
招前招之空洞卷积:
如图,普通卷积

空洞卷积:

空洞卷积:
青铜:跨格(洞)卷积。
白银:空洞卷积又名膨胀卷积,又又名扩张卷积。一开始空洞卷积的提出是为了解决图像分割问题而提出的。因为常见的图像分割算法通常使用卷积层和池化层来增加感受野,同时也缩小了特征图的尺寸。所以就需要用上采样的方式还原图像尺寸,比如第二招里面的求差异,就用到了上采样,其作用之一就是为了满足特征图尺寸大小一样后,才能对特征图做差求差异。
但是,对特征图做上采样,其实就是放大特征图,这必然会造图像信息的损失。所以就需要一种解决办法:增加感受野的同时,保持特征图的尺寸不变,从而代替上采样和下采样操作。所以空洞卷积就是为了解决这个问题而提出的。
感受野是什么?
对比人在看一副壁画(为什么是壁画,因为它足够大)的时候,不可能一眼就“看完”整个壁画。而是从上到下,或者从感兴趣的区域“一点一点扫描”的看,那人眼所能容纳的视觉范围(或者人眼能够容纳的壁画大小)就是感受野。对比到神经网络中,感受野就是卷积或者池化时,框住的特征图的区域,比如3X3的卷积,那感受野的范围就是3X3;若是2X2的池化,则感受野的范围就是2X2。
如上图,空洞卷积,就是在对图像做卷积时,增大框住的特征图区域,同时不改变卷积“个数”大小。空洞卷积引入了一个称为空洞数(扩张率)的超参数,该参数就是在做卷积操作时,卷积核内部的间距值。如果空洞数为1,则就是以往的正常卷积。
总结:对于空洞卷积,通过设置不同的空洞数,就能得到不同的特征;在SPP中,设置不同的最终池化大小,也能得到不同的特征。然后把空洞卷积和SPP组合在一起,就是ASPP。也就是通过ASPP,通过扩大“宽度”的方式,得到特征的多样性。