
作者:Barr Moses
翻译:陈超
校对:欧阳锦
本文约3800字,建议阅读12分钟本文将会深入分析一些短期内最热门的观点,这些观点可能会成为后现代数据堆栈的组成部分,并对它们对数据工程的潜在影响进行论述。后现代数据堆栈已经到来。我们准备好了吗?

图片由作者免费提供
如果你不喜欢改变,数据工程不适合你。在这个领域没有任何东西能够保持一成不变。
最近最重要的例子是Snowflake和Databricks,它们颠覆了数据库的概念,开创了现代数据堆栈时代。
作为此次变化的一部分,Fivetran和dbt从根本上上将数据管道从ETL(Extract, Transform, Load)变为ELT。高接触中断软件即服务(SaaS)以一种将重心转移到数据仓库的尝试席卷了整个世界。蒙特卡洛也加入这场争论之中,并认为“让工程师手动编写单元测试可能并非保证数据质量的最佳方式”。
今天,数据工程师们沿着现代数据堆栈启蒙的上坡路前进过程中继续死磕硬编码管道和企业预置型服务器。而必将到来的兼并与幻灭的低谷已经在尚且称之为安全的远处显现。
所以干扰破坏者的新观点已经不断涌现的事实,这貌似看起来不太合理:
Zero-ETL在自己的视域中有数据摄取
AI和大型语言模型可以变形
数据产品容器将数据表视为数据的核心基本要素
我们要(再一次)重建一切吗?Hadoop(分布式计算)的时代还没到完全凉透的程度。
答案是当然的。我们可能会在职业生涯中多次重建我们的数据系统。真正的问题是为什么、何时以及怎样(以此为序)。
我不会妄称自己知道所有答案或者拥有能够预知答案的水晶球。但是本文将会深入分析一些短期内最热门的观点,这些观点可能会成为后现代数据堆栈的组成部分,并对它们对数据工程的潜在影响进行论述。
实践性和权衡


图片来自Unsplash上的Tingey Injury Law Firm
现代数据堆栈的出现并非因为它比之前的技术做得更好。权衡就在于此。数据更大、更快,但它也更混乱,管理更差。关于成本效益的审判仍然没有定论。
现代数据堆栈之所以一骑绝尘,因为它能支持用例并以在从前可能是非同寻常的难度情况下将数据价值释放出来。机器学习一词已经从单纯的流行语变成了“财富密码”。而分析和实验则可以更深入地支持决策更大化。
同样的情况也适用于以下每一种趋势。虽然毁誉参半,但是主导采纳的是他们或者那些我们还未发现的黑马们如何解锁新的方法来利用数据。让我们进一步来看一下。
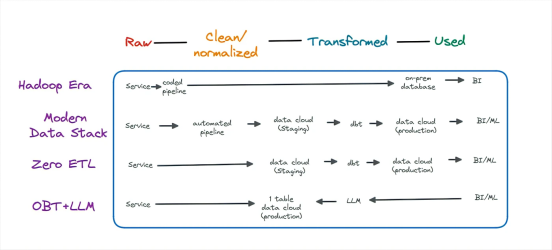
Zero-ETL


它是什么:一则用词不当;数据管道仍然存在。
如今,数据通常由服务生成并写入事务数据库。部署的自动管道不仅将原始数据移动到分析数据仓库,而且在此过程中对其进行了轻微修改。
例如,API 将以 JSON 格式导出数据,引入管道不仅需要传输数据,还需要应用轻度转换,以确保数据采用可加载到数据仓库中的表格式。在引入阶段完成的其他常见轻量级转换是数据格式化和重复数据删除。
虽然您可以通过在 Python 中对管道进行硬编码来进行更繁重的转换,并且有些人主张这样做以将预先建模的数据交付到仓库,但大多数数据团队出于权宜之计和可见性/质量原因选择不这样做。
Zero-ETL 通过让事务数据库在自动将其加载到数据仓库之前执行数据清理和标准化来更改此引入过程。请务必注意,数据仍处于相对原始的状态。
目前,这种紧密集成是可能的,因为大多数zero-ETL架构要求事务数据库和数据仓库来自同一云提供商。
优点:减少延迟。没有重复的数据存储。少一个故障源。
缺点:在引入阶段自定义数据处理方式的能力较差。部分供应商锁定。
谁在推动它:AWS是流行语(Aurora到Redshift)背后的驱动力,但GCP(BigTable到BigQuery)和Snowflake(Unistore)都提供类似的功能。Snowflake(安全数据共享)和Databricks(Delta共享)也在追求它们所谓的“无复制数据共享”。此过程实际上不涉及 ETL,而是提供了对存储数据的扩展访问。
实用性和价值释放潜力:一方面,由于背后的科技巨头和随时可用的能力,Zero-ETL的推广似乎只是时间问题。另一方面,我观察到数据团队正在解耦,而非更紧密地集成操作和分析数据库,以防止意外的架构更改而使整个操作崩溃。
这种创新可能会进一步降低软件工程师对其服务产生的数据的可见性和责任感。数据在提交代码后不久就已经在运往仓库的途中,他们为什么还要关心架构?
随着流数据和微批量方法满足了目前对“实时”数据的绝大多数需求,我认为此类创新的主要业务驱动力是基础设施简化。虽然无可厚非,但从长远来看,没有副本数据共享以消除冗长的安全审查障碍的可能性可能会导致对此种机制报复性使用(尽管需要明确的是,这不是此消彼长的选项)。
OBT和大型语言模型


它是什么:目前,业务利益相关者需要向数据专业人员表达他们的需求、指标和逻辑,然后数据专业人员将其全部转换为 SQL 查询甚至仪表板。该过程需要时间,即使数据仓库中已存在所有数据也是如此。更不用说在数据团队最喜欢的活动列表中,临时数据请求的排名介于根管和文档之间。
有一群初创公司旨在利用像 GPT-4 这样的大型语言模型的力量,通过让消费者在平滑的界面中“查询”自然语言中的数据来自动化该过程。
 至少在我们的新机器人霸主使二进制成为新的官方语言之前
至少在我们的新机器人霸主使二进制成为新的官方语言之前
这将从根本上简化自助式分析过程,并进一步使数据大众化,但考虑到更高级分析的数据管道的复杂性,除了基本的“指标获取”之外,该问题很难解决。
但是,如果通过将所有原始数据填充到一个大表中来简化这种复杂性呢?
这是本恩·斯坦西尔(Benn Stancil)提出的想法,他是数据领域最优秀和有远见的作家/创始人之一。没有人比他更能预见现代数据堆栈的消亡。
作为一个概念,它并非那么遥不可及。一些数据团队已经开始使用褒贬不一的(one big table, OBT)策略了。
利用大型语言模型似乎可以克服使用OBT的最大挑战之一,即在发现和模式识别方面的困难以及其完全缺乏组织性。对于人类来说,为他们的故事提供一个目录和标记良好的章节是十分有用的,但人工智能并不在乎。
优点:也许可以最终兑现自助式数据分析的承诺;快速获得见解;使数据团队能够将更多时间用于释放数据价值和构建,减少响应即席查询的时间。
缺点:是否自由过度?数据专业人员熟悉数据令人痛苦的怪癖(时区!什么是“帐户”?),而在某种程度上,大多数业务利益相关者对此却并不熟悉。我们是否受益于代议制而不是直接的数据民主?
谁在推动它:Delphi和 GetDot.AI 等超级早期创业公司。像Narrator这样的初创公司。更成熟的参与者正在做一些这样的版本,如Amazon QuickSight,Tableau Ask Data或ThoughtSpot。
实用性和价值释放潜力:令人耳目一新的是,这不是一项寻找用例的技术。价值和效率是显而易见的,但技术挑战也是显而易见的。这一愿景仍在构建中,需要更多的时间来制定。也许采用的最大障碍将是所需的基础设施中断,这对于更成熟的组织来说可能风险太大。
数据产品容器
它是什么:数据表是构建数据产品的数据的构建基块。事实上,许多数据领导者将生产表视为他们的数据产品。但是,要将数据表视为产品,需要对许多功能进行分层,包括访问管理、发现和数据可靠性。
容器化已成为软件工程中微服务运动不可或缺的一部分。它们增强了可移植性、基础架构抽象,并最终使组织能够扩展微服务。数据产品容器概念设想了数据表的类似容器化。
数据产品容器可能被证明是使数据更加可靠和可治理的有效机制,特别是如果它们可以更好地呈现与数据基础单元关联的语义定义、数据沿袭和质量指标等信息。
优点:数据产品容器似乎是更好地打包和执行四个数据网格原则(联合治理、数据自助服务、将数据视为产品、域优先基础结构)的一种方式。
缺点:这个概念会让组织更容易还是更难扩展其数据产品?对于许多这些未来数据趋势,另一个基本问题是,数据管道的副产品(代码、数据、元数据)是否包含值得数据团队保留的价值?
谁在推动它:Nextdata,由数据网格创建者Zhamak Dehgahni创立的创业公司。Nexla也一直在这个领域发挥作用。
实用性和价值释放潜力:虽然Nextdata最近才从隐身中脱颖而出,数据产品容器仍在不断发展,但许多数据团队已经看到了数据网格实施的成熟结果。数据表的未来将取决于这些容器的确切形态和执行。
数据生命周期的无尽想象重构


图片来自Unsplash, zero
为了窥探数据的未来,我们需要回顾过去和现在的数据。过去、现在、未来——数据基础设施处于不断中断和重生的状态(尽管我们可能需要更多的混乱)。
数据仓库的含义与 Bill Inmon 在 1990 年代引入的术语相比发生了巨大变化。ETL 管道现在是 ELT 管道。数据池不像两年前那样无固定的形状。
随着现代数据堆栈带来的这些创新,数据工程师在决定数据如何移动以及数据消费者如何访问数据方面仍然发挥着核心的技术作用。但有些变化比其他变化更大、更可怕。
Zero-ETL这个术语似乎很有威胁,因为它(不准确地)暗示了管道的消亡,如果没有管道,我们需要数据工程师吗?
尽管 ChatGPT 生成代码的能力背后大肆宣传,但这个过程仍然掌握在技术数据工程师手中,他们仍然需要审查和调试。大型语言模型的可怕之处在于它们如何从根本上扭曲数据管道或我们与数据消费者的关系(以及如何向他们提供数据)。
然而,这个未来,如果它成为现实,仍然强烈依赖数据工程师。
自古以来一直存在的是数据的一般生命周期。它被放出,它被塑造,它被使用,然后它被存档(最好避免在这里纠缠于我们自己的消亡)。
虽然底层基础设施可能会发生变化,自动化会将时间和注意力转移到右边或左边,但在可预见的未来,人类数据工程师将继续在从数据中提取价值方面发挥关键作用。
这并不是因为未来的技术和创新无法简化当今复杂的数据基础设施,而是因为我们对数据的需求和使用将继续增加复杂性和规模。
大数据已经并且永远是一个来回摆动的钟摆。我们在能力上向前飞跃,然后我们同样迅速地找到一种方法来达到这些边界,直到需要下一次飞跃。在这个循环中得到安慰——被需要是件好事。
Shane Murray是这篇文章的合著者。请订阅以将他的故事发送到您的收件箱。
对数据质量的未来感兴趣,请联系蒙特卡洛团队!
原文标题:
Zero-ETL, ChatGPT, And The Future of Data Engineering
原文链接:
https://towardsdatascience.com/zero-etl-chatgpt-and-the-future-of-data-engineering-71849642ad9c
编辑:于腾凯
校对:程安乐
译者简介

陈超,北京大学应用心理硕士,数据分析爱好者。本科曾混迹于计算机专业,后又在心理学的道路上不懈求索。在学习过程中越来越发现数据分析的应用范围之广,希望通过所学输出一些有意义的工作,很开心加入数据派大家庭,保持谦逊,保持渴望。
翻译组招募信息
工作内容:需要一颗细致的心,将选取好的外文文章翻译成流畅的中文。如果你是数据科学/统计学/计算机类的留学生,或在海外从事相关工作,或对自己外语水平有信心的朋友欢迎加入翻译小组。
你能得到:定期的翻译培训提高志愿者的翻译水平,提高对于数据科学前沿的认知,海外的朋友可以和国内技术应用发展保持联系,THU数据派产学研的背景为志愿者带来好的发展机遇。
其他福利:来自于名企的数据科学工作者,北大清华以及海外等名校学生他们都将成为你在翻译小组的伙伴。
点击文末“阅读原文”加入数据派团队~
转载须知
如需转载,请在开篇显著位置注明作者和出处(转自:数据派ID:DatapiTHU),并在文章结尾放置数据派醒目二维码。有原创标识文章,请发送【文章名称-待授权公众号名称及ID】至联系邮箱,申请白名单授权并按要求编辑。
发布后请将链接反馈至联系邮箱(见下方)。未经许可的转载以及改编者,我们将依法追究其法律责任。

点击“阅读原文”拥抱组织