Abstract
3D点云中物体的精确检测是许多应用中的一个核心问题,如自主导航、室内机器人和增强/虚拟现实。
为了将高度稀疏的激光雷达点云与区域建议网络(RPN)进行接口,大多数现有的努力都集中在手工制作的特征表示上,例如,鸟瞰投影。
在这项工作中,我们不需要为3D点云进行手动的特征设计,并提出一个具有统一特征提取和边框(bounding box)预测的单阶段(single-stage)、端到端(end-to-end)的可训练深度网络的通用3D检测网络,即VoxelNet。
具体而言,VoxelNet将点云划分为等间距的三维体素,并通过新引入的体素特征编码(VFE)层将每个体素中的一组点变换为统一的特征表示。
以这种方式,点云被编码为描述性的体积表示,然后将其连接到RPN以产生检测。
KITTI车辆检测基准的实验表明,VoxelNe比现有的基于LIDAR的3D检测方法大幅度地优于现有的基于LIDAR的3D检测方法。
此外,我们的网络学习出对不同的几何形状的物体的有效判别的特征表示,在仅基于激光雷达的行人和骑自行车的人的3D检测上产生令人鼓舞的结果。
1 Introduction
基于点云的3D物体检测是各种真实世界应用的一个重要组成部分,如自主导航[11,14]、家务机器人[28]和增强/虚拟现实[29]。
与基于图像的检测相比,激光雷达提供可靠的深度信息,可以用于精确定位物体并表征它们的形状[21, 5]。
然而,与图像不同的是,激光雷达点云稀疏且具有高度可变的点密度,这是由于3D空间的非均匀采样、传感器的有效范围、遮挡和相对姿态等因素造成的。
为了应对这些挑战,许多方法手动提取用于三维物体检测的点云的特征表示。

几种方法将点云投影到透视图中,并应用基于图像的特征提取技术[28,15,22]。
其他方法将点云光栅化为3D体素网格,并手动提取编码每个体素[43,9,39,40,21,5]。
然而,这些手动设计选择引入了一个阻止这些方法有效地利用3D形状信息和检测任务所需的不变性的信息瓶颈。
从手动提取特征到机器学习提取特征是图像识别[20]和检测[13]任务上的重大突破。
[分段]
最近,Qi等人[31]提出了一种端到端(end-to-end)深度神经网络PointNet,它直接从点云学习点对点特征(point-wise feature)。
该方法在三维物体识别、三维物体分割、点对点语义分割等方面取得了令人印象深刻的结果。
在[32]中,引入了一种改进的PointNet模型,使网络能够在不同的尺度上学习局部结构。
为了获得令人满意的结果,这两种方法在所有输入点(大约1k点)训练特征变换网络。
由于使用LiDARs获得的典型点云包含大约100k点,因此训练像[29, 30 ]中的体系结构会导致高的计算和存储器需求。
将3D特征学习网络扩展到多个数量级和3D检测任务是我们在本文中所要解决的主要挑战。
[分段]
区域生成网络(Region proposal network,RPN)[34]是一种高度有效的目标检测算法[17,5,33,24]。
然而,这种方法需要的数据是密集和有组织的张量结构(例如,图像,视频),而这不是典型的LiDAR点云的数据结构。
在本文中,我们消除了点集特征学习和RPN的3D目标检测任务之间的鸿沟。
[分段]
我们提出了一个通用的3D检测框架VoxelNet,它同时从点云中学习有辨识度的特征表示,并以端到端的方式预测精确的3D边框(bounding box),如图2所示。
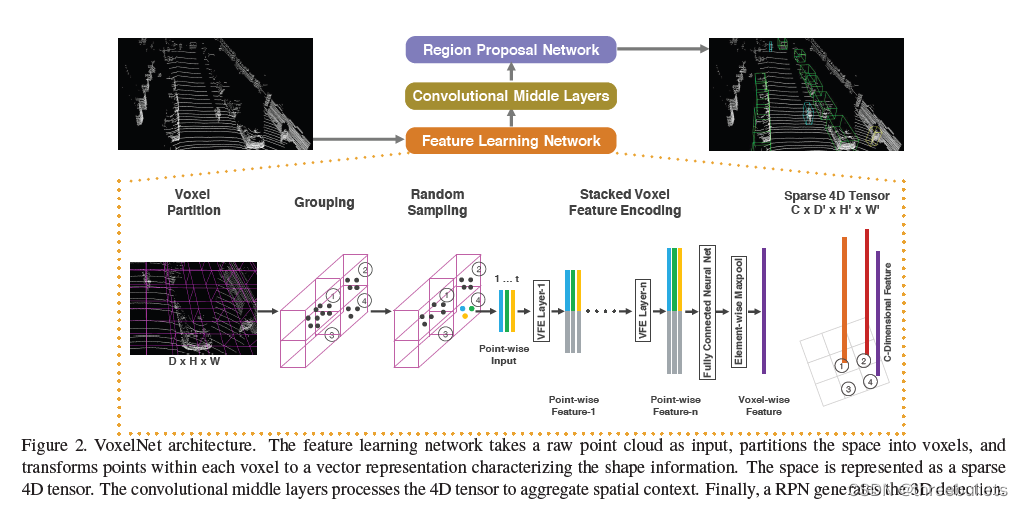
我们设计了一种新的体素特征编码(voxel feature encoding,VFE)层,它能够在体素中实现点间交互,通过将点特征与局部聚集特征相结合。
堆叠多个VFE层允许学习复杂特征以表征局部3D形状信息。
具体而言,VoxelNet将点云划分为等间距的三维体素,通过堆叠的VFE层编码每个体素,然后3D卷积进一步聚集局部体素特征,将点云转换为高维体积表示。
最后,RPN获得体积表示并产生检测结果。
这种有效的算法既有利于稀疏点结构,又有利于体素网格的有效并行处理。
[分段]
我们评估VoxelNet在鸟瞰视图检测和完整的3D检测任务,由KITTI基准[11]提供。
实验结果表明,VoxelNet大大优于现有的基于激光雷达的3D检测方法。
我们还证明,VoxelNet在激光雷达点云检测行人和骑自行车者方面取得了非常令人鼓舞的结果。
1.1 Related Work
3D传感器技术的快速发展促使研究者开发有效的表达来检测和定位点云中的物体。
一些早期的特征表示方法中是[41,8,7,19,42,35,6,27,1,36,2,25,26 ]。
当丰富和详细的3D形状信息可用时,这些手工制作的特征会产生令人满意的结果。
然而,它们无法适应更复杂的形状和场景,并且从数据中学习所需的不变性,从而导致不受控制的场景的有限成功,例如自主导航。
[分段]
考虑到图像提供了详细的纹理信息,许多算法从2D图像推断出3D包围框(3D bounding boxes)[4,3,44,45,46,38]。
然而,基于图像的3D检测方法的精度受到深度估计精度的限制。
[分段]
一些基于激光雷达的3D物体检测技术利用体素网格表示。
[43,9]用从体素中包含的所有点导出的6个统计量来编码每个非空体素。
[39]融合多个局部统计数据来表示每个体素。
[40]计算体素网格上的截断符号距离。
[21]使用三维体素网格的二进制编码。
[5]通过在鸟瞰图中计算多通道特征图和在正面视图中的圆柱坐标,介绍了一种激光雷达点云的多视图表示方法。
其他一些研究将点云投影到透视图上,然后使用基于图像的特征编码方案[30, 15, 22]。
[分段]
还存在多种结合图像和激光雷达的多模态融合方法以提高检测精度[10,16,5]。
这些方法与仅激光雷达的3D检测相比提供了改进的性能,特别是对于小物体(行人、骑自行车者)或物体远时,因为摄像机提供比激光雷达更大数量级的测量。
然而,需要与激光雷达进行时间同步和校准的摄像机限制了它们的使用,并且使得该解决方案对传感器故障模式更加敏感。
在这项工作中,我们专注于激光雷达仅检测。
1.2. Contributions
- 我们对于基于点云的3D检测提出了一种新的端到端可训练的深架构VoxelNet,它直接操作在稀疏的3D点,并避免信息瓶颈由手动特征获取引入。
- 我们提出了一种有效的实现VoxelNet的方法,它既有利于稀疏点结构,又有利于体素网格上的高效并行处理。
- 我们在KITTI基准上进行实验,并表明VoxelNETs在基于激光雷达的汽车、行人和骑自行车检测基准中产生了最先进的结果。
2 VoxelNet
在这一节中,我们解释了VoxelNETs的架构,用于训练的损失函数,以及实现网络的有效算法。
2.1 VoxelNet Architecture
所提出的VoxelNet由三个功能块组成:(1)特征学习网络,(2)卷积中间层,和(3)区域建议网络[34],如图2所示。我们在下面的章节中详细介绍了VoxelNet.
2.1.1 Feature Learning Network
体素划分
给定点云,我们将3D空间细分成等距的体素,如图2所示。假设点云包含沿Z、Y、X轴分别具有D、H、W的三维空间。
我们定义每个体素的大小VD,VH,和VW相应。得到的三维体素网格大小为D’=D/VD,H’=H/VH,W’=W/VW。
这里,为了简单起见,我们假设D、H、W是VD、VH、VW的倍数。
分组
我们根据点所在的体素来对点进行分组。
由于距离、遮挡、物体相对姿态和非均匀采样等因素,激光雷达点云稀疏,在整个空间中具有高度可变的点密度。
因此,在分组之后,体素将包含可变数量的点。
图2显示了一个例子,其中Voxel-1比Voxel-2和Voxel-4具有更多的点,而Voxel-3不包含任何点。
随机抽样
典型地,高分辨率激光雷达点云由大约100K点组成。
直接处理所有的点不仅增加了计算平台上的内存/效率负担,而且在整个空间中高度可变的点密度可能导致检测结果偏差。
为此,我们随机地从点数多于T个的体素中随机采样固定个数T。
该采样策略有两个目的,(1)计算节省(参见细节2.3节);(2)减少体素之间的点的不平衡,减少采样偏差,并且增加训练的变化。
堆叠体素特征编码
关键的创新是VFE层的链。
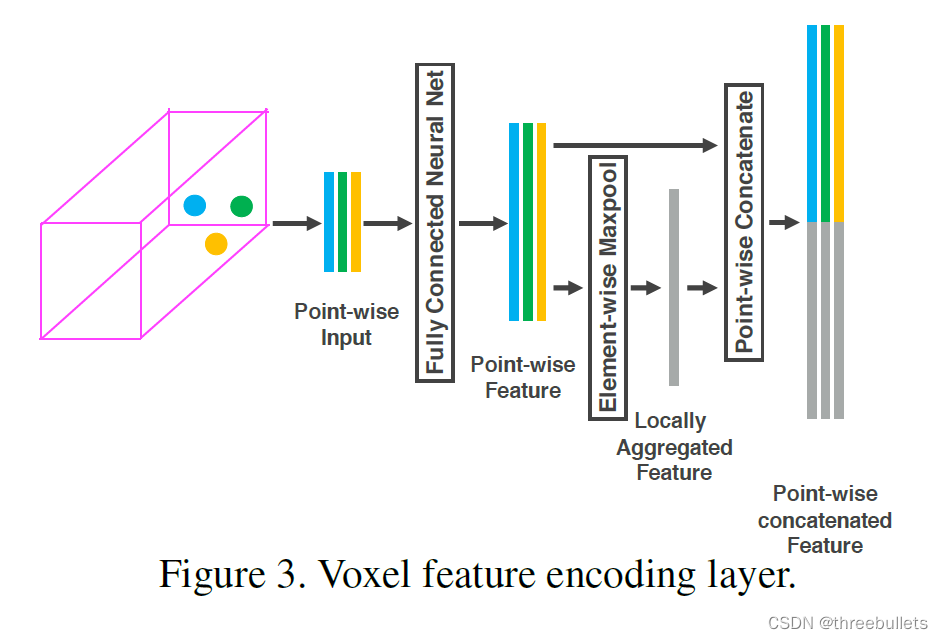
为了简单起见,图2示出了一个体素的分层特征编码过程。
在不损失一般性的情况下,我们使用VFE层-1来描述下面段落中的细节。图3显示了VFE层-1的体系结构。
V = { p i = [ x i , y i , z i , r i ] T ∈ R 4 } V = \left \{ p_{i} =[x_{i},y_{i},z_{i},r_{i}]^T \in \mathbb{R}^{4}\right \} V={
pi=[xi,yi,zi,ri]T∈R4}
V作为含有t(t <= T)个激光雷达点的非空体素,其中pi包含第i个点的XYZ坐标,ri是接收的反射率。
我们首先计算局部均值作为V中的所有点的质心,表示为 ( v x , v y , v z ) (v_{x},v_{y},v_{z}) (vx,vy,vz)。
然后用与质心相关的相对偏移扩充每个点Pi,得到输入特征集Vin
V i n = { p ^ i = [ x i , y i , z i , r i , x i − v x , y i − v y , z i − v z ] T ∈ R 7 } i = 1... t V_{in} = \left \{ \widehat{p}_{i} =[x_{i},y_{i},z_{i},r_{i},x_{i}-v_{x},y_{i}-v_{y},z_{i}-v_{z}]^T \in \mathbb{R}^{7}\right \}_{i=1...t} Vin={
p
i=[xi,yi,zi,ri,xi−vx,yi−vy,zi−vz]T∈R7}i=1...t
接着,pi通过全连通网络(FCN)变换为特征空间,在这里我们可以从点特征 f i ∈ R m f_{i} \in \mathbb{R}^m fi∈Rm集合信息来编码包含在体素中的表面的形状。
FCN由线性层、批量归一化(BN)层和线性修正单元(ReLU)层组成。
在获得逐点特征表示之后,我们使用元素相关的最大池遍历所有与 V V V相关的 f i f_{i} fi以获得局部聚合特征 f ~ ∈ R m \tilde{f}\in \mathbb{R}^m f~∈Rm
最后,我们用 f ~ \tilde{f} f~来增加每个 f i f_{i} fi以形成点i级联特征,如 f i o u t = [ f i T , f ~ i T ] ∈ R m f_{i}^{out}=[f_{i}^{T},\tilde{f}_{i}^{T}] \in \mathbb{R}^m fiout=[fiT,f~iT]∈Rm。
因此,我们得到输出特征集 V o u t = { f i o u t } i . . . t V_{out}= \left \{ f_{i}^{out} \right \} _{i...t} Vout={ fiout}i...t。
所有非空体素以相同的方式编码,并且它们在FCN中共享相同的参数集。
[分段]
我们使用VFE- i ( C i n , C o u t ) i(C_{in},C_{out}) i(Cin,Cout)来表示将维度 C i n C_{in} Cin的输入特征转换为维度 C o u t C_{out} Cout的输出特征的第i个VFE层。
线性层学习维度为 C i n × ( C o u t / 2 ) C_{in}×(C_{out}/2) Cin×(Cout/2)的矩阵,逐点级联产生维度为 C o u t C_{out} Cout的输出。
[分段]
由于输出特征结合了点特征和局部聚集特征,堆叠VFE层编码体素内的点相互作用,并且使得最终特征表示能够学习描述性形状信息。
逐体素特征是通过将VFE-n的输出通过FCN转换成 R C \mathbb{R}^C RC并应用逐元素最大池化得到,其中C是逐体素特征的维度,如图2所示。
[分段]
稀疏张量表示
通过只处理非空体素,我们得到体素特征的列表,每个体素与特定的非空体素的空间坐标唯一相关。
获得的体素特征列表可以表示为一个稀疏的4D张量,大小为C× D ′ D' D′× H ′ H' H′× W ′ W' W′,如图2所示。
虽然点云包含大约100K点,但超过90%的体素通常是空的。
表示非空体素特征作为稀疏张量极大地减少了在反向传播期间的内存使用和计算成本,并且它是我们高效实现的关键步骤。
2.1.2 Convolutional Middle Layers
我们使用ConvMD(cin,cout,k,s,p)来表达一个M维卷积操作,其中cin和cout是输入和输出通道个数,k,s,p是M维向量分别对应于卷积核(kernel size)大小、步幅大小(stride size)和填充大小(padding size)。
当通过M维的大小是相同的,我们使用一个标量来代表这个大小,例如k对应于k=(k,k,k)。
[分段]
每一个卷积中间层循环地应用于3D卷积、BN层和ReLU层。
卷积中间层在一个逐步增大的感受野上合并逐体素特征,添加更多的上下文到形状描述中。
卷积中间层中的滤波器的详细大小在第三节中详细介绍。
2.1.3 Region Proposal Network
最近,
[分段]
我们RPN的输入是卷积中间层提供的特征图谱。
这个网络的结构见图4.

这个网络有三个全卷积层块。
每个块的第一层通过一个stride size为2的卷积将特征图谱进行一半的降采样,接着一个stride为1的卷积序列(×q意味着滤波器的q次应用)。
在每个卷积层之后,进行BN和ReLU操作。
然后我们对每个块的输出升采样到一个固定的大小,连接以构造高分辨率的特征图谱
最后,特征图谱被映射到预期的学习目标:一个可能性分数图和一个回归图。
(未完待续)