机器阅读是实现机器认知智能的重要技术之一。机器阅读任务主要有两大类:完形填空和阅读理解。
(1)完型填空类型的问答,简单来说就是一个匹配问题。问题的求解思路基本是:
1) 获取文档中词的表示
2) 获取问题的表示
3) 计算文档中词和问题的匹配得分,选出最优
(2)文本段类型的问答,与完型填空类型的问答,在思想上非常类似,主要区别在于:完形填空的目标是文档中的一个词,文本阅读理解的目标是文档中的两个位置,分别用来标志答案的起点和终点。目标的差别带来了网络模型上一些差别。
继上次复现了r-net的方案之后,现将之前复现过的Bidirectional AttentionFlow (经典的阅读理解模型)也进行记录一下。
1、基本原理
BiDAF模型最大的特点是在interaction层引入了双向注意力机制,计算Query2Context和Context2Query两种注意力,并基于注意力计算query-aware的原文表示。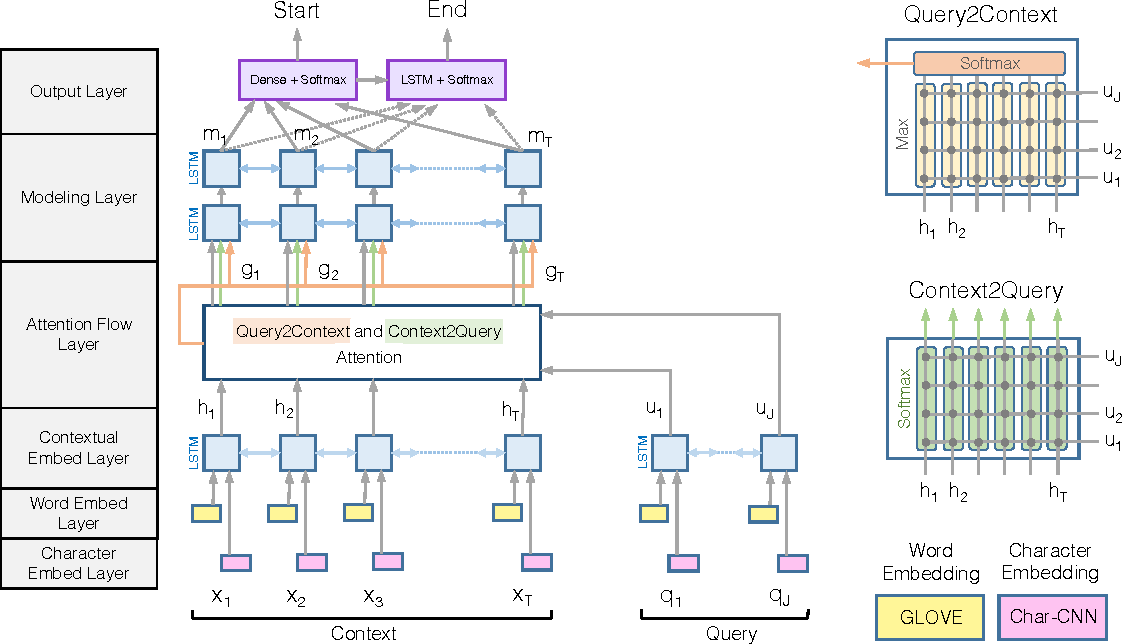
模型由这样几个层次组成:
(1)Character Embedding Layer使用char-CNN将word映射到固定维度的向量空间;
(2)Word Embedding Layer使用(pre-trained)word embedding将word映射到固定维度的向量空间;
从上图可以看出,该模型同时使用了字符的词向量和词向量两种层次的嵌入表示。
(3)Contextual Embedding Layer将上面的到的两个word vector拼接,然后输入LSTM中进行context embedding;
(4)Attention Flow Layer将passage embedding和question embedding结合,使用Context-to-query Attention 和Query-to-contextAttention得到word-by-word attention;
(5)Modeling Layer将上一层的输出作为bi-directional RNN的输入,得到Modeling结果M;
(6)Output Layer使用M分类得到passage的起始位置,然后使用M输入bi-directional LSTM得到M2,再使用M2分类得到passage的中止位置作为answer。
2、实验测试
(1)启动训练,加载词向量模型

(2)训练过程截图

(3)训练后的测试结果,如下所示,可以看到F1的值可以达到74.9%
