前言
1.从技术角度来看,现在的数学人就是一个缝合怪,把各种技术点都整合在一起,用来实现直播、对话等数字人。技术流程大概如下图:

其实最重要的一环应该属于LLM(大型语言模型),LLM相当于一个人的意识,如果没有LLM,这一套完全没有深度。
2.数学人的呈现方式有现在基本上可以分为三种,2D、2.5D、3D这三种,2D是最常见的用一段语音去驱动一张照片,2.5D比2D多一些肢体动作,3D是UE建模。
3.我这里部署的是2D实时对话的数字人,部署环境是win 10、cuda 11.7、cudnn 8.5、GPU是3060(6G显存)。
2D实时对话数字人
因为这个项目本身就是一个缝合的项目,所以尽量使用Anaconda来创建环境,这样项目之间就不存在依赖互相干扰的问题。python使用python3.9或者3.10。
一.项目源码
缝合连接的源码可使用开源的Fay这个代码,这个代码里面有连接各种API和部署本地库的,源码地址:GitHub - TheRamU/Fay: Fay是一个完整的开源项目,包含Fay控制器及数字人模型,可灵活组合出不同的应用场景:虚拟主播、现场推销货、商品导购、语音助理、远程语音助理、数字人互动、数字人面试官及心理测评、贾维斯、Her。 开源项目,非产品试用!!!Fay是一个完整的开源项目,包含Fay控制器及数字人模型,可灵活组合出不同的应用场景:虚拟主播、现场推销货、商品导购、语音助理、远程语音助理、数字人互动、数字人面试官及心理测评、贾维斯、Her。 开源项目,非产品试用!!! - GitHub - TheRamU/Fay: Fay是一个完整的开源项目,包含Fay控制器及数字人模型,可灵活组合出不同的应用场景:虚拟主播、现场推销货、商品导购、语音助理、远程语音助理、数字人互动、数字人面试官及心理测评、贾维斯、Her。 开源项目,非产品试用!!! https://github.com/TheRamU/Fay
https://github.com/TheRamU/Fay
2D数字人源码地址:
https://github.com/waityousea/xuniren![]() https://github.com/waityousea/xuniren
https://github.com/waityousea/xuniren
二.Fay环境安装
conda create --name fay python=3.10
activate fay安装fay所需要的环境依赖:
git clone https://github.com/TheRamU/Fay.git
cd xx/xx/fay
pip install -r requirements.txt
打开fay项目下的system.conf文件,添加用到的Key,关于这些key如何获取,可以参与fay给参考教程:
 https://www.bilibili.com/video/BV1go4y1L7oe/?spm_id_from=333.999.0.0&vd_source=d08e238ac726c4b15a0e12ffd5176ee5
https://www.bilibili.com/video/BV1go4y1L7oe/?spm_id_from=333.999.0.0&vd_source=d08e238ac726c4b15a0e12ffd5176ee5
[key]
#funasr / ali
ASR_mode = ali
#ASR二选一(需要运行fay/test/funasr服务)集成达摩院asr项目、感谢中科大脑算法工程师张聪聪提供集成代码
local_asr_ip=127.0.0.1
local_asr_port=10197
# ASR二选一(第1次运行建议用这个,免费3个月), 阿里云 实时语音识别 服务密钥(必须)https://ai.aliyun.com/nls/trans
ali_nls_key_id=
ali_nls_key_secret=
ali_nls_app_key=
# 微软 文字转语音 服务密钥(非必须,使用可产生不同情绪的音频)https://azure.microsoft.com/zh-cn/services/cognitive-services/text-to-speech/
ms_tts_key=
ms_tts_region=
# 讯飞 情绪分析 服务密钥 https://www.xfyun.cn/service/emotion-analysis/
xf_ltp_app_id=
xf_ltp_api_key=
#NLP多选一:xfaiui、yuan、chatgpt、rasa(需启动chatglm及rasa,https://m.bilibili.com/video/BV1D14y1f7pr)、VisualGLM
chat_module=xfaiui
# 讯飞 自然语言处理 服务密钥(NLP3选1) https://aiui.xfyun.cn/solution/webapi/
xf_aiui_app_id=
xf_aiui_api_key=
#浪.潮源大模型 服务密钥(NLP3选1) https://air.inspur.com/
yuan_1_0_account=
yuan_1_0_phone=
#gpt 服务密钥(NLP3选1) https://openai.com/
chatgpt_api_key=
#ngrok内网穿透id,远程设备可以通过互联网连接Fay(非必须)http://ngrok.cc
ngrok_cc_id=
#revChatGPT对接(非必须,https://chat.openai.com登录后访问https://chat.openai.com/api/auth/session获取)
gpt_access_token=
gpt_conversation_id=绑定完使用到的key,启动fay看看是否能交互。
python main.py文字输入:
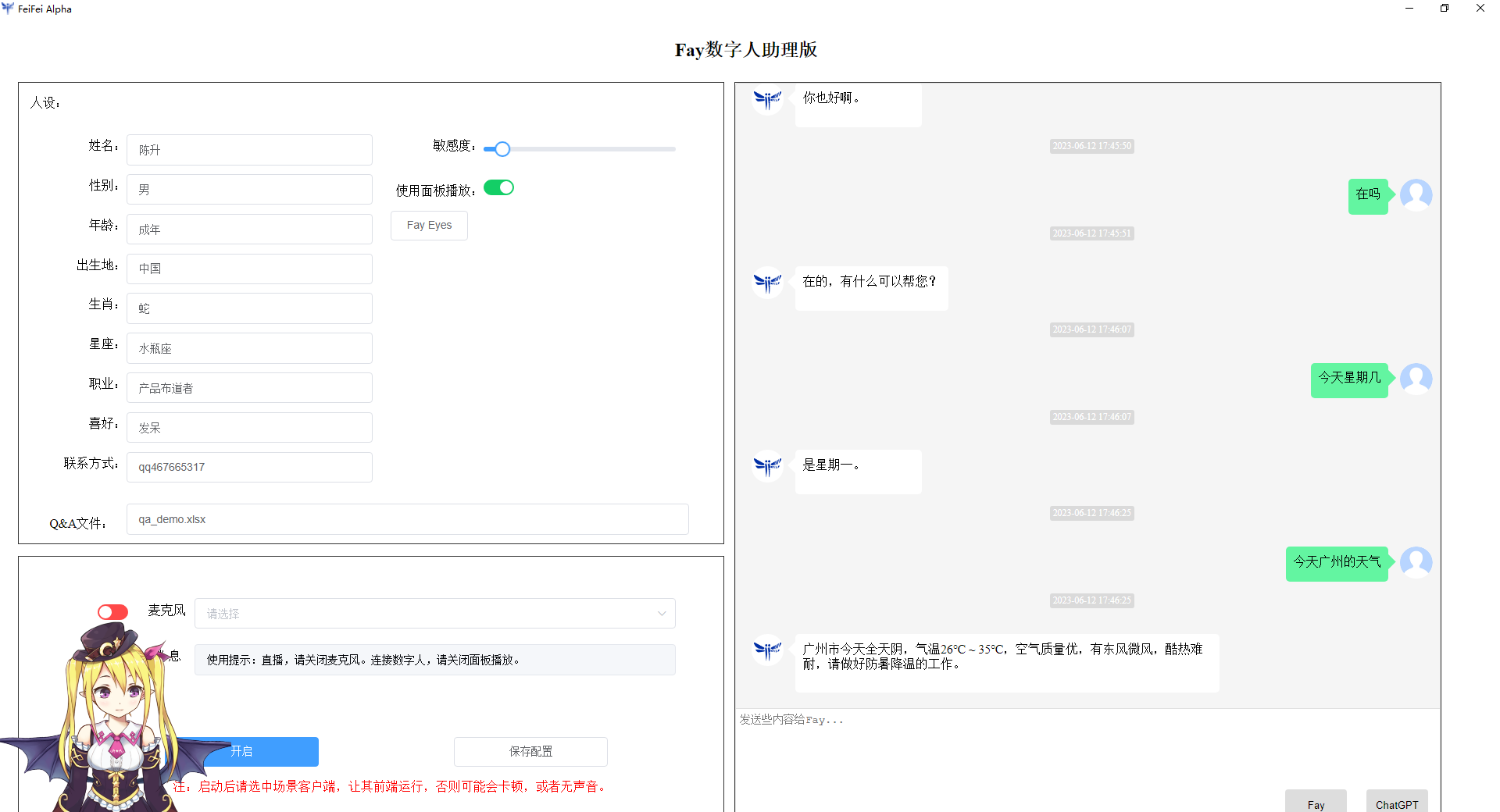
语音输入:

这样代表fay启动成功,文字和语音都能进行交互。
三. 2D数字人部署
环境安装
conda create --name xuniren python=3.10
activate xuniren项目下载与依赖torch:
git clone https://github.com/waityousea/xuniren.git
cd xuniren
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
conda install -c fvcore -c iopath -c conda-forge fvcore iopath
pip install -r requirements.txt安装pytorch 3D(win下这一步比较容易报错)
git clone https://github.com/facebookresearch/pytorch3d.git
cd pytorch3d
python setup.py install安装完成之后运行api看看是否有报错。
python fay_connect.py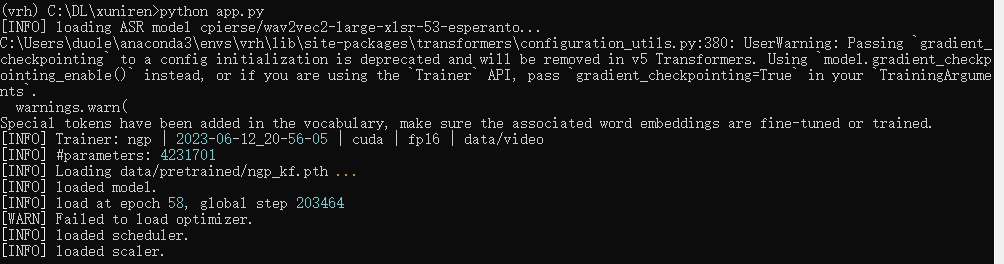
四.数字人实现对话
要与数字人对话,按前言给的流程图,要实现语音文字、LLM、文字转语音、合成视频,这里可以先试试线上的语言模型。
1.启动fay
cd xx/xx/Fay
activate fay
python main.py可以看到1003接口已打开
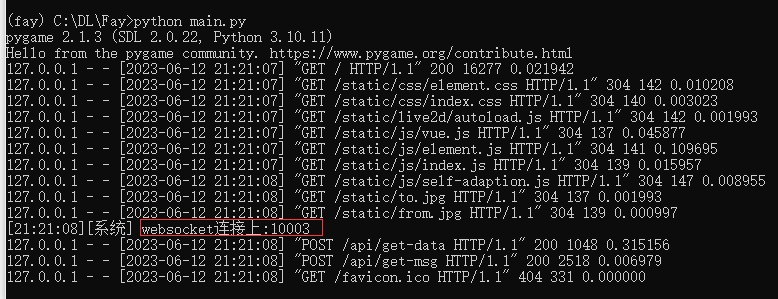
2.打开一个新conda终端启动数字人
cd xx/xx/xuniren
activate xuniren
python fay_connect.py此时1002口也连接上,数字人终端可以检测到fay面板已经打开
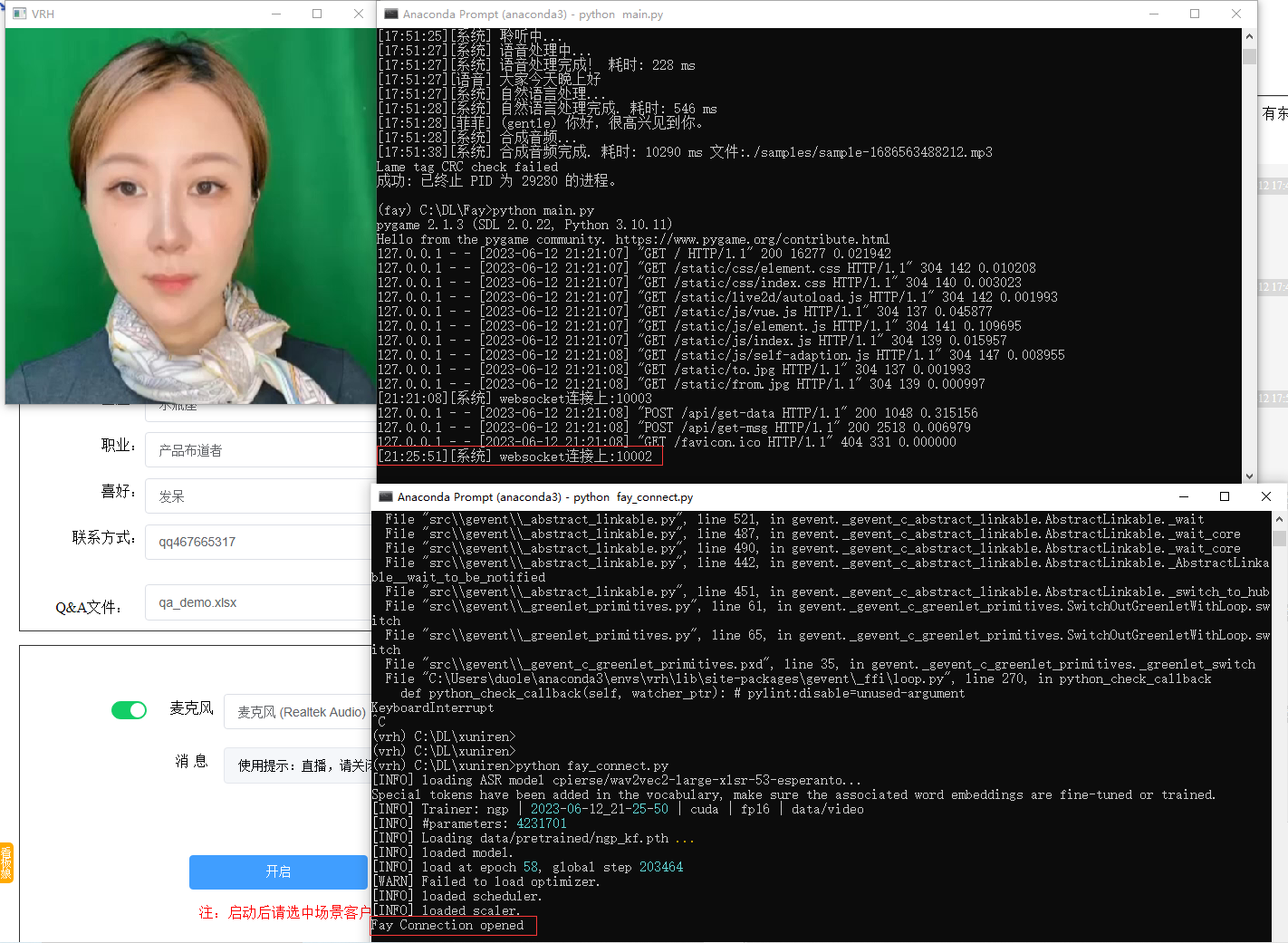
3.打开fay的控制面板,启动数字人助理
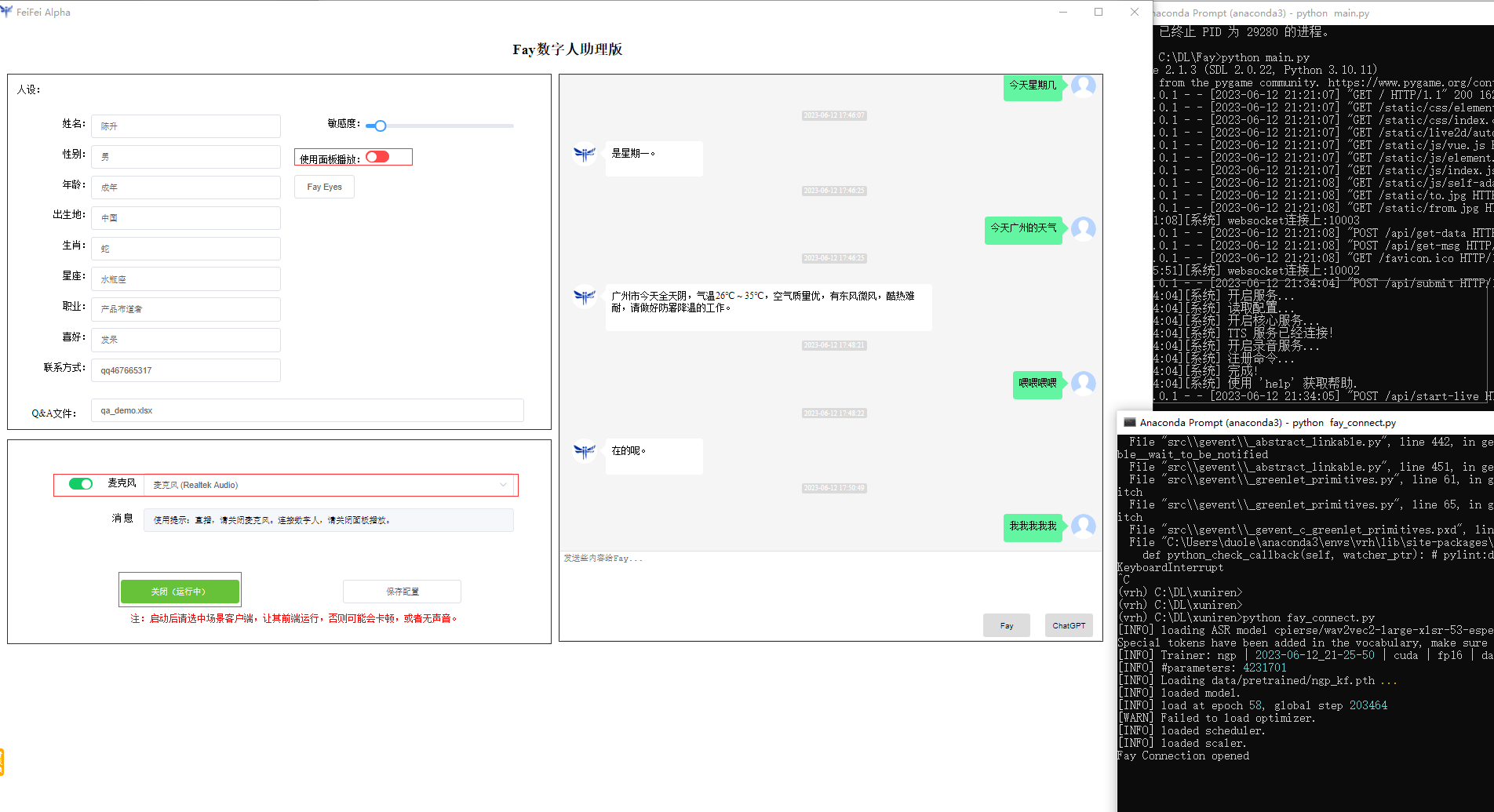
4.开始交互
语音识别后,提交给语言模型,模型回答后生成语音,把语音保存的地地址发给数字人,生成的语音是mp3格式的,把mp3转成wav,然后通过模型合成视频,合成后对视频进行播放。

这就是一个简单的对话数字人的全部过程,这里除了语音合成视频用的本地模型之外,都用的是在线的api,在6G的GPU在,1秒的时间,大概能生成1秒左右的视频。
五.本地部署ChatGLM
如果想要数字人有自己的知识库,或者有自己回答问题的方式,就要接入私有化的LLM,Fay有接入ChatGLM的接口,也可以按Fay的代码接入微调过的LLM。
1.ChatGLM-6B
ChatGLM-6B 是清华开源的、支持中英双语的对话语言模型,基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。我笔记本的3060刚刚好6G,那可以用GLM试试。
2.源码下载与环境依赖
为了方便管理,这里还是用conda创建环境
git clone https://github.com/THUDM/ChatGLM-6B
cd ChatGLM-6B
conda create --name GLM python=3.10
activate GLM
conda install pytorch==2.0.0 torchvision==0.15.0 torchaudio==2.0.0 pytorch-cuda=11.7 -c pytorch -c nvidia
pip install -r requirements.txt
3.更改模型精度
我当前笔记本的GPU只有6G,所以要更改模型精度,要不然会报内存不够的错误。
更改api.py文件
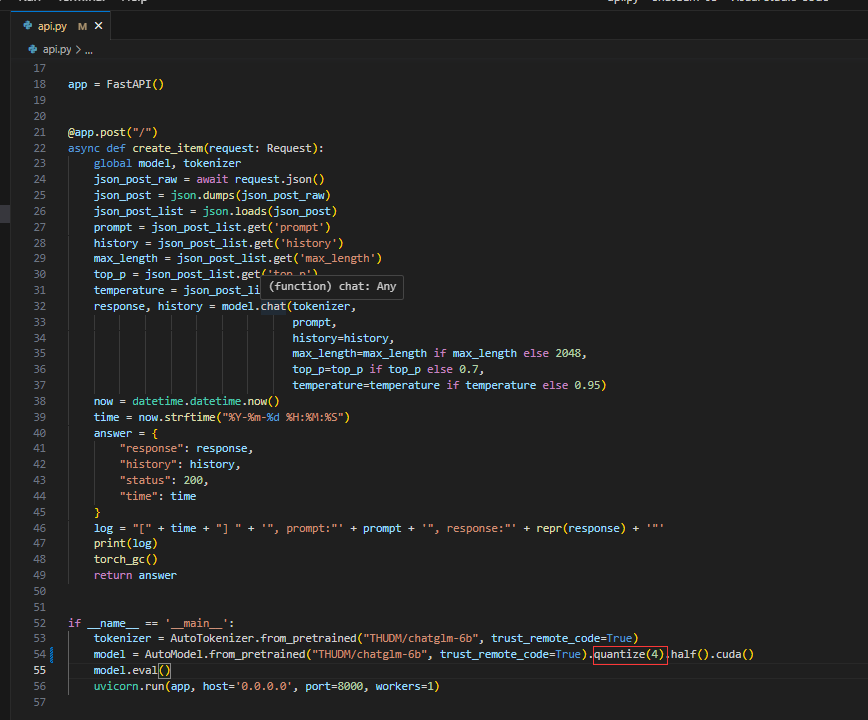
4.运行ChatGLM
更改完成之后,运行api.py,这里会下载12G大小的模型,下载的过程中可能会出现中断,多运行几次就可以了,下载的时间看自己的网速快慢。当出现以下界面,GLM安装成功。

六、对接本地语言模型
1.要实现对接本地的语言模型步骤有些多,fay提供了对接rasa加GLM的方法,首先要更改fay的配置文件,把语言模型改成如下:

改完成之后,启动第一个fay的conda环境并运行main.py程序,窗口放着不用动。
activate fay
python main.py2.启动多一个fay的conda环境,用来运行rasa
activate fay
cd fay/test/rasa
pip install rasa
rasa run actions 运行结果如下:
3.再启动一个fay的conda环境,用来对接GLM
activate fay
cd fay/test/rasa
然后运行 rasa shell 来测试是否能连上GLM,在Your input处提出问题看看是否能得到相应的答案。
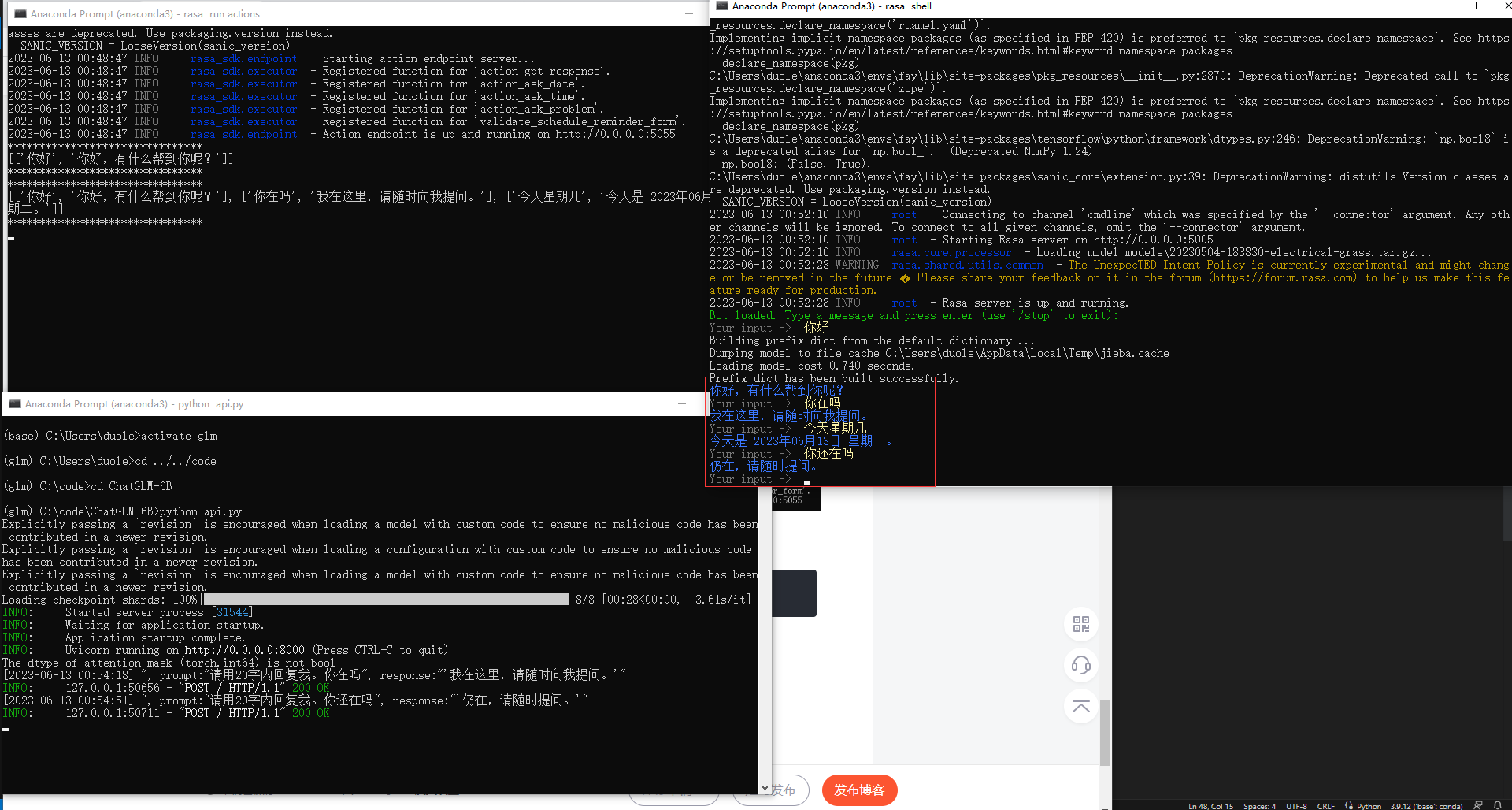
如果运行成功,终止掉rasa shell,启动rasa api server:rasa run --enable-api -p 5005

4.启动数字人
cd xx/xx/xuniren
activate xuniren
python fay_connect.py5.开启fay数字人控制面板,就可以跟数字人进行互动了。
后记
这是一个完成的部署过程,因为项目所用到的项目源码与环境相对多,部署过程会有很多问题,虽然是一个各种项目缝合在一起,但也给如何实现数字人做了一个很好的参考。之后有时间我试着把2.5D的模型缝合进来。
如果对该项目感兴趣或者获取源码的可以加我的企鹅群:487350510,大家一起探讨,也可以加fay的公众号,fay的公众号在它的git首页获取。