Zookeeper集群搭建
前言
Zookeeper是大数据平台的必要服务之一。在比如Hadoop集群、Kafka集群以及Hbase集群等都需要Zookeeper的管理。
准备工作
- 需要准备三台Linux主机,可以是Centos、Ubuntu等都可以。
- 在三台Linux主机上配置Java环境变量。
- 为三台主机配置SSH免密登录。
开始搭建
- 下载Zookeeper的安装包,这里下载的是3.1.14版本,直接使用wget下载即可。
wget https://mirrors.tuna.tsinghua.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
- 下载之后使用tar命令对安装包进行解压:
tar -zxvf zookeeper-3.4.14.tar.gz
- 编写配置文件
# 切换到Zookeeper的conf目录下
cd zookeeper-3.4.14/conf
# 拷贝一份配置
cp zoo_sample.cfg zoo.cfg
# 使用vim打开配置文件进行编辑
vim zoo.cfg
zoo.cfg
tickTime=2000
initLimit=10
syncLimit=5
# 数据存储目录
dataDir=/tmp/zookeeper
# Zookeeper的端口
clientPort=2181
# 集群节点的配置
# 其中server.0的0为Zookeeper集群中的节点id
# 2888为原子广播端口,3888为选举端口
server.0=192.168.0.12:2888:3888
server.1=192.168.0.11:2888:3888
server.2=192.168.0.6:2888:3888
- 编写myid配置文件
myid配置文件中的内容按照zoo.cfg中配置的server.id相对应,比如server.0节点就需要在myid配置文件中配置一个“0”,以此类推。
其中myid配置文件的位置则为zoo.cfg中dataDir的目录。
将配置内容通过重定向的方式写入到myid文件中。
echo 0 > /tmp/zookeeper/myid
- 将解压完并且配置好的Zookeeper目录远程拷贝到其它两台机器上
scp -r zookeeper-3.4.14 [email protected]:/home/worker/bigdata/
其中的配置并不需要修改,只需配置对应的myid文件即可。
echo 2 > /tmp/zookeeper/myid
第三台机器以此类推。
启动Zookeeper
待三台机器都配置完成后,启动Zookeeper进行测试。由于没有配置环境变量,需要进入到Zookeeper的bin目录中执行命令。
使用该命令启动Zookeeper
./zkServer.sh start
在其它两台机器同样执行该命令
然后使用一下命令检查是否启动成功:
./zkServer.sh status
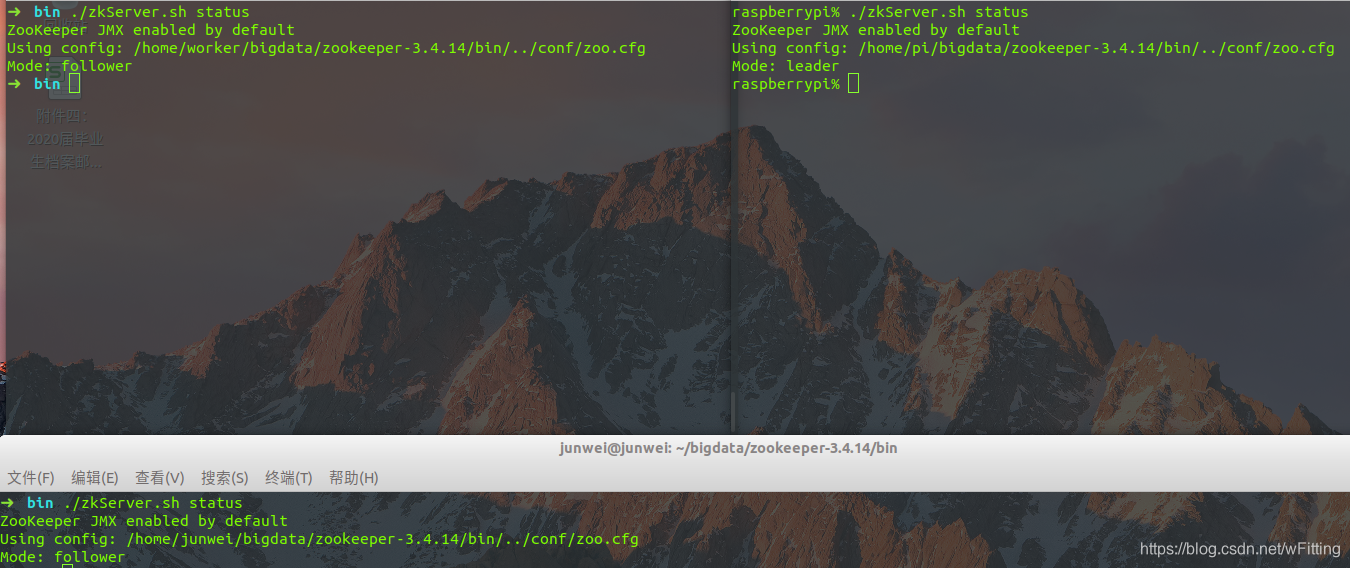
如Mode处显示状态即配置成功。两个follower一个leader。
我们还可以使用zkClinet进行测试,同样在bin目录下使用以下明林登录Zookeeper集群
./zkCli.sh
登录成功画面:

在根节点处有zookeeper的目录即为成功。
如果没有显示这些,可能会是出现了一些问题,同样在bin目录下有一个zookeeper.out的文件,这里面存储的就是Zookeeper运行的日志,可以查看里面的日志,具体来判断是出了什么问题。