K8s组件:etcd安装、使用及原理(Linux)
1 介绍及安装
1.1 介绍
分布式系统架构中对一致性要求很高,etcd就满足了分布式系统中的一致性要求。
- 实现了分布式一致性键值对存储的中间件,支持跨平台,有活跃的社区。
- etcd 是基于go实现的一个分布式键值对存储(类比Redis),设计用来可靠而快速的保存关键数据并提供访问。通过分布式锁,leader选举和写屏障(write barriers) 来实现可靠的分布式协作。etcd集群是为高可用,持久性数据存储和检索而准备。
- etcd完整的cluster(集群)至少需要3台,这样才能选出一个master和两个node
- etcd目前占用2379和2380两个端口
- 2379:提供HTTP API服务,和etcdctl交互;
- 2380:集群中节点间通讯;
- 具有强一致性,
常用于注册中心(配置共享和服务发现)- 现目前是分布式和云原生下的基础组件,如:k8s等
CAP理论:Consistency一致性、Availability可用性、partition tolerance分区容错性【CP、AP】
- 系统架构:
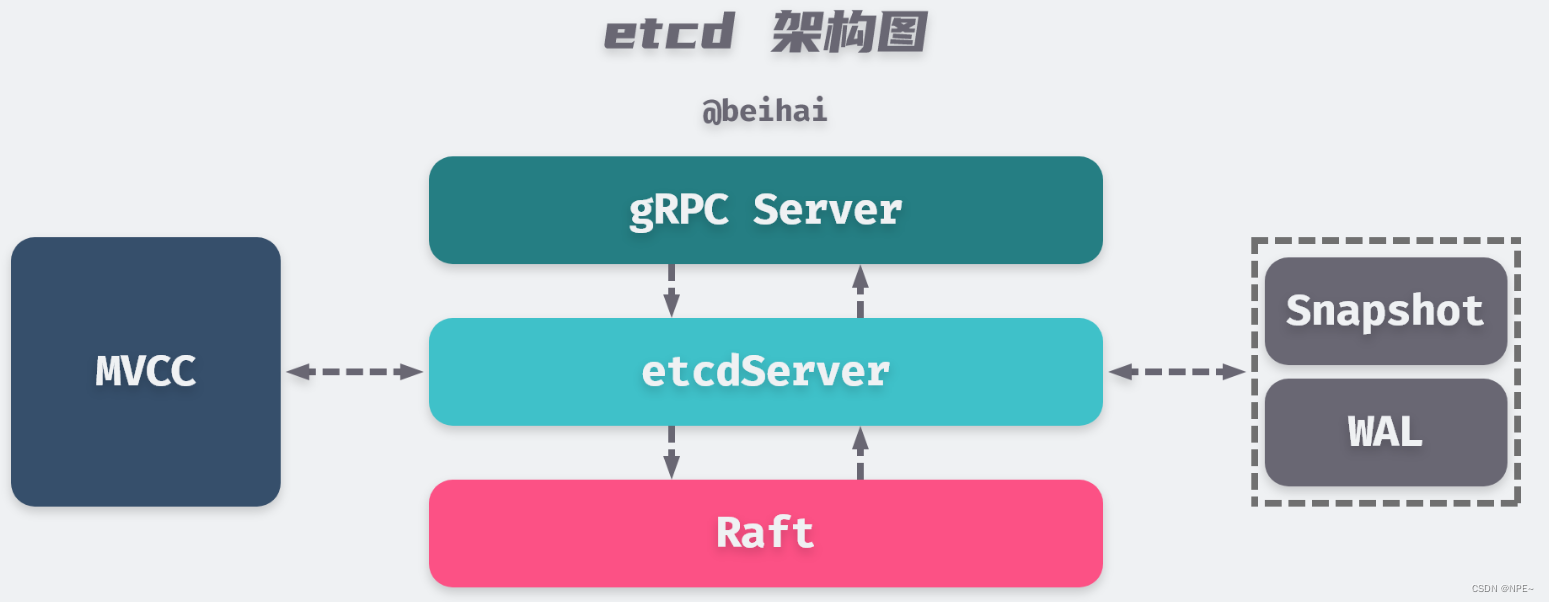
应用场景:
- 键值对存储
- 服务注册与发现
- 消息发布与订阅
- 分布式锁
1.2 Raft协议
参考:https://juejin.cn/post/7035179267918938119#heading-3
1.2.1 基本概念
①名词解释
Raft协议一共包含3种角色:
- Leader(领袖):领袖由群众投票选举得出,每次选举,只能选出一名领袖;
- Candidate(候选人):当没有领袖时,某些群众可以成为候选人,然后去竞争领袖的位置;
- Follower(群众):这个很好理解,就不解释了。
然后在进行选举过程中,还有几个重要的概念:
- Leader Election(领导人选举):简称选举,就是从候选人中选出领袖;
- Term(任期):它其实是个单独递增的连续数字,每一次任期就会重新发起一次领导人选举;
- Election Timeout(选举超时):就是一个超时时间,当群众超时未收到领袖的心跳时,会重新进行选举。
②角色转换
这幅图是领袖、候选人和群众的角色切换图,我先简单总结一下:
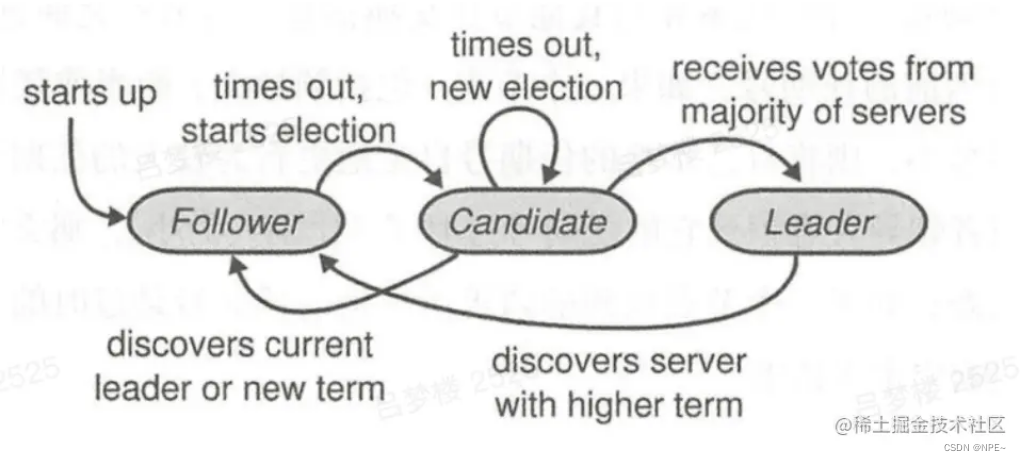
- 群众 -> 候选人:当开始选举,或者“选举超时”时
- 候选人 -> 候选人:当“选举超时”,或者开始新的“任期”
- 候选人 -> 领袖:获取大多数投票时
- 候选人 -> 群众:其它节点成为领袖,或者开始新的“任期”
- 领袖 -> 群众:发现自己的任期ID比其它节点分任期ID小时,会自动放弃领袖位置
备注:后面会针对每一种情况,详细进行讲解。
1.2.2 选举
①领导人选举
为了便于后续的讲解,我画了一副简图,“选举定时器”其实就是每个节点的“超时时间”。
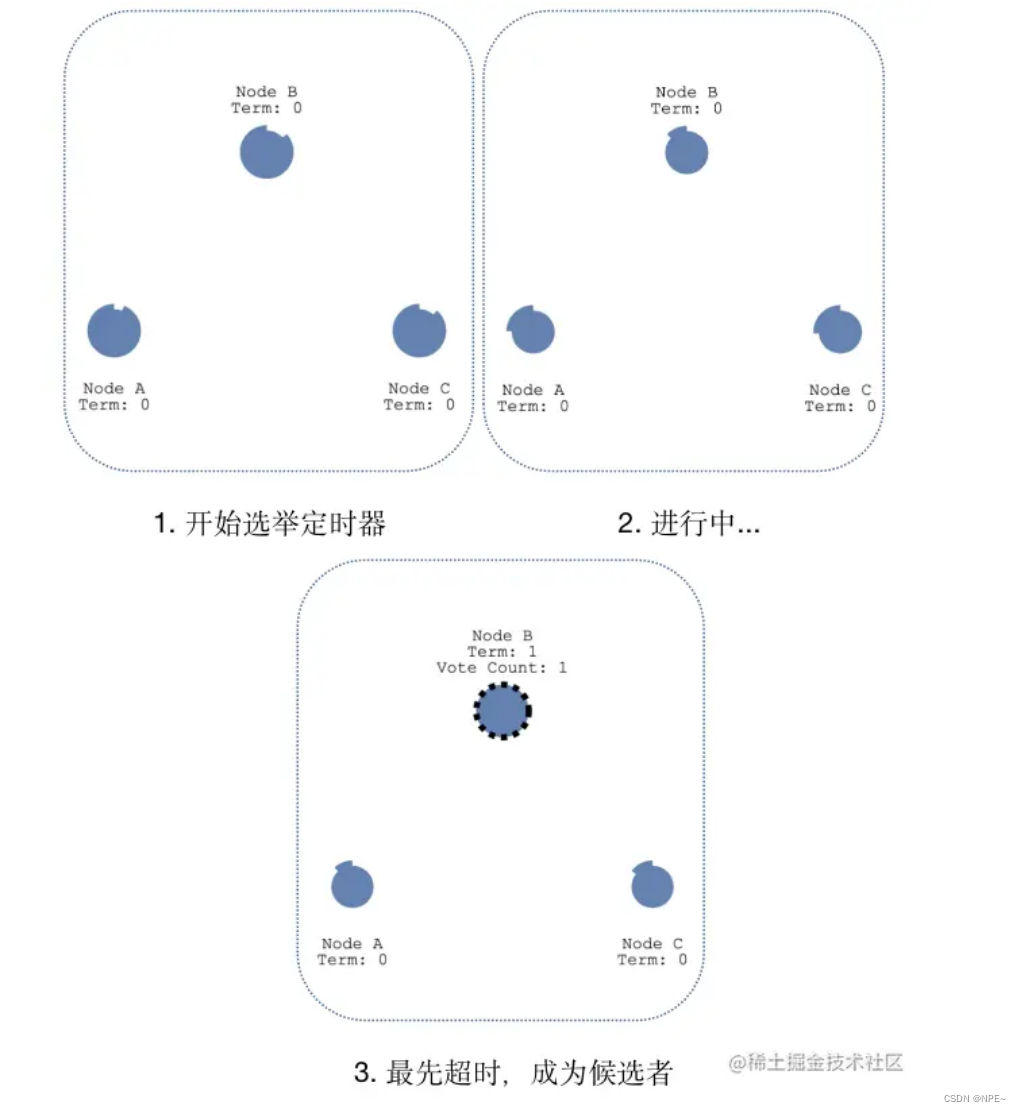
成为候选人:每个节点都有自己的“超时时间”,因为是随机的,区间值为150~300ms,所以出现相同随机时间的概率比较小,因为节点B最先超时,这时它就成为候选人。
扫描二维码关注公众号,回复: 15695279 查看本文章
选举领导人:候选人B开始发起投票,群众A和C返回投票,当候选人B获取大部分选票后,选举成功,候选人B成为领袖。
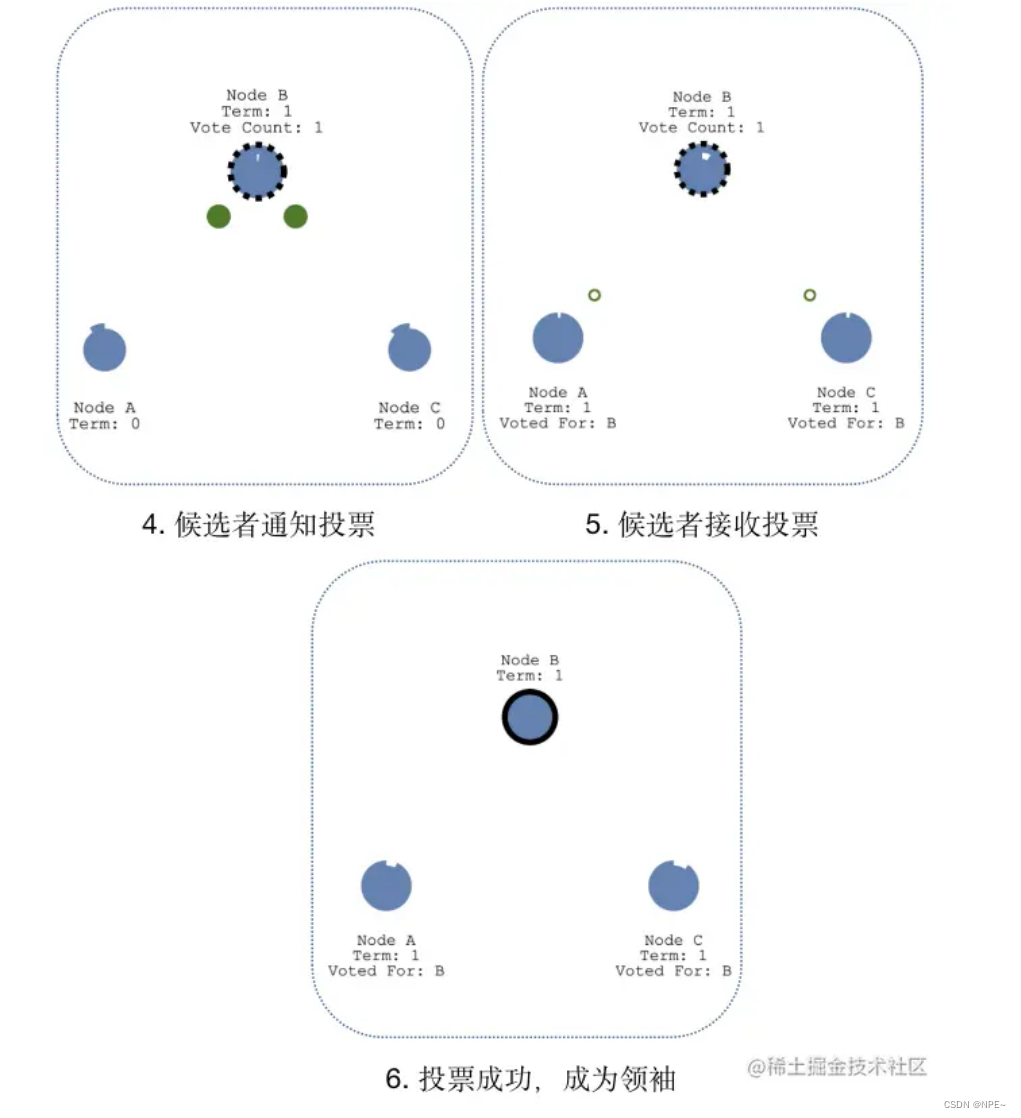
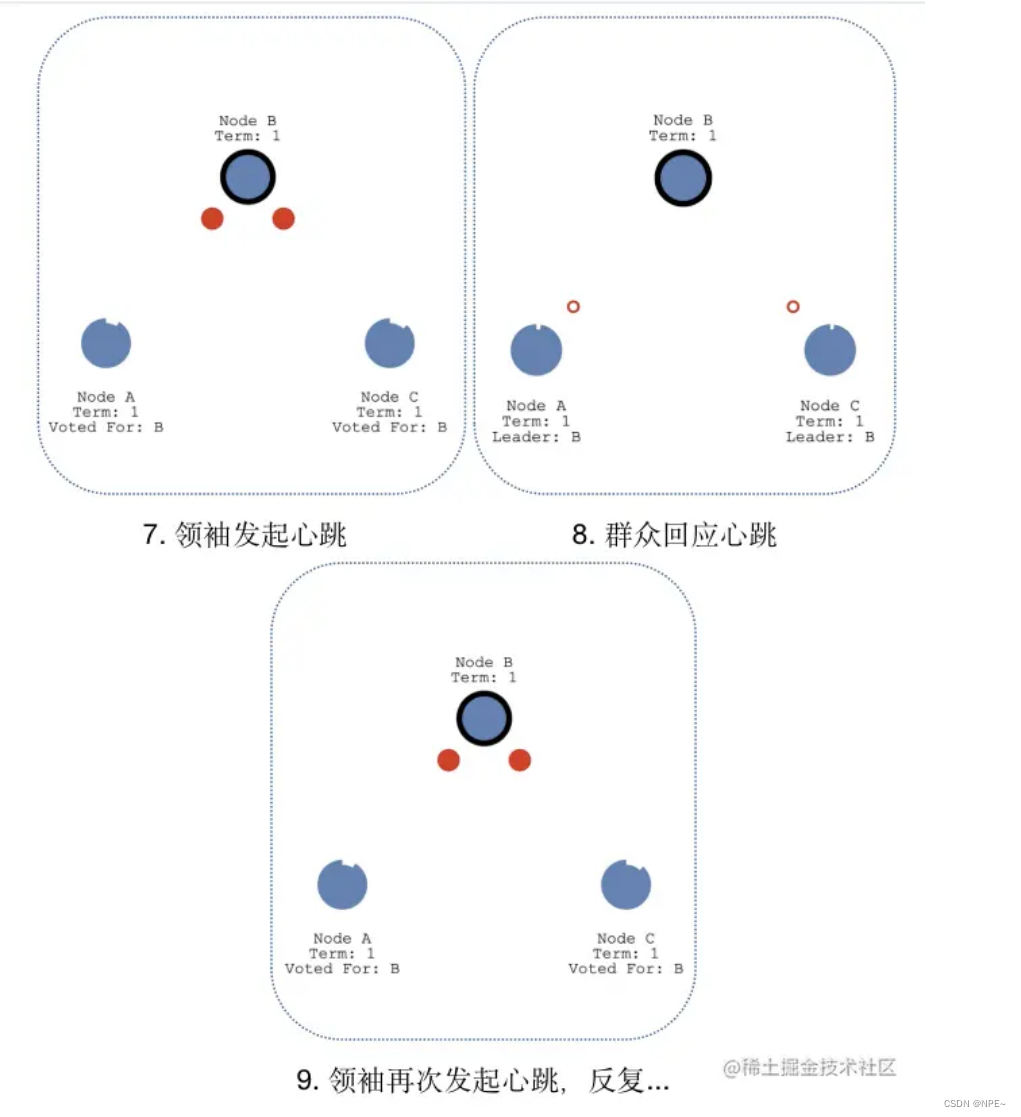
心跳探测:为了时刻宣誓自己的领导人地位,领袖B需要时刻向群众发起心跳,当群众A和C收到领袖B的心跳后,群众A和C的“超时时间”会重置为0,然后重新计数,依次反复。
这里需要说明一下,领袖广播心跳的周期必须要短于“选举定时器”的超时时间,否则群众会频繁成为候选者,也就会出现频繁发生选举,切换Leader的情况。
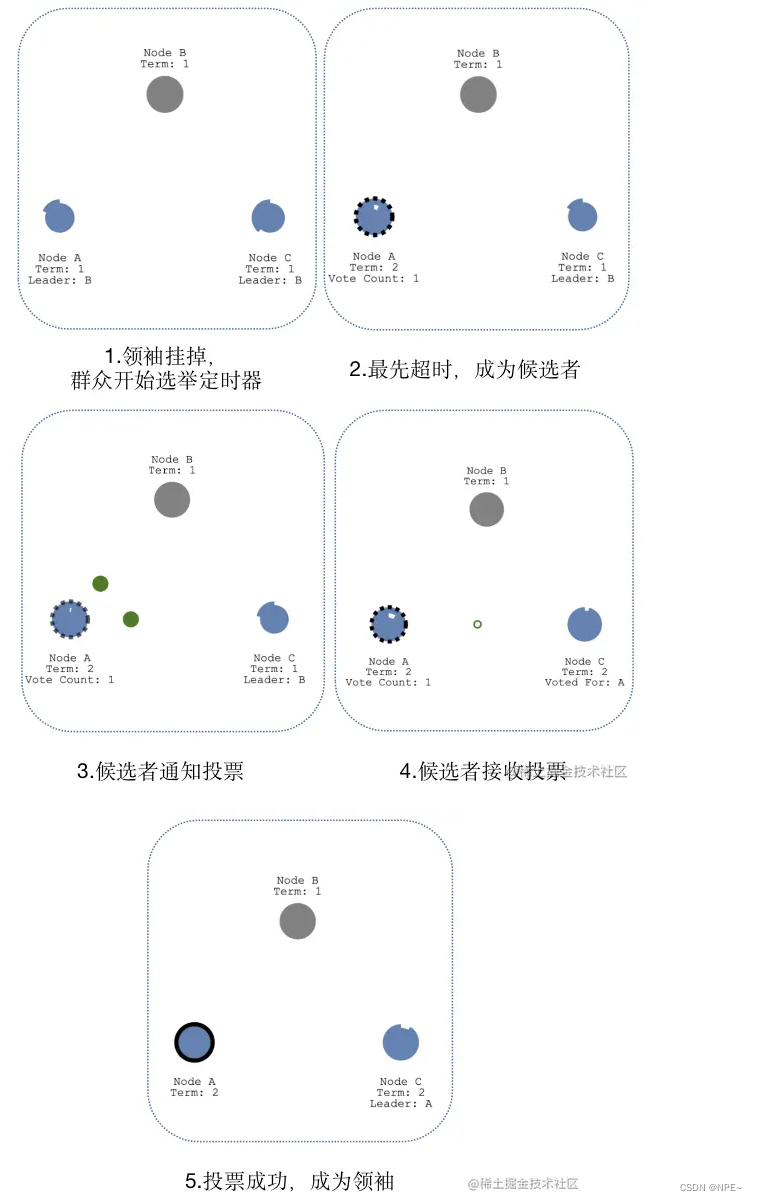
②领袖挂掉的情况
当领袖B挂掉,群众A和C会的“选举定时器”会一直运行,当群众A先超时时,会成为候选人,然后后续流程和“领导人选举”流程一样,即通知投票 -> 接收投票 -> 成为领袖 -> 心跳探测。
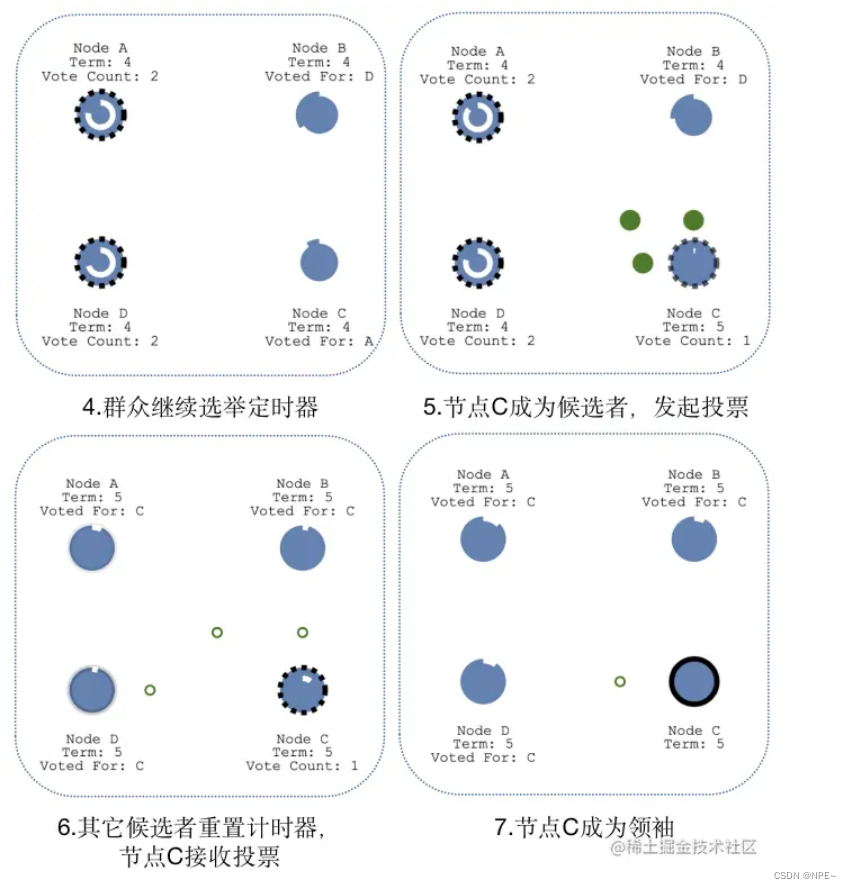
③出现多个候选者情况
当出现多个候选者A和D时,两个候选者会同时发起投票,如果票数不同,最先得到大部分投票的节点会成为领袖;如果获取的票数相同,会重新发起新一轮的投票。
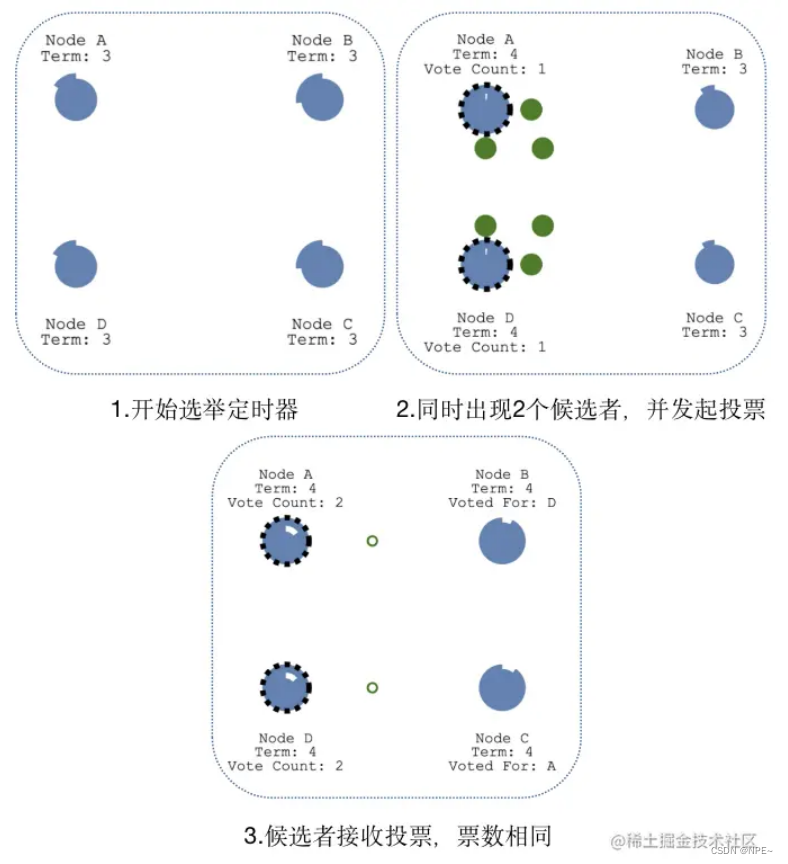
当C成为新的候选者,此时的任期Term为5,发起新一轮的投票,其它节点发起投票后,会更新自己的任期值,最后选择新的领袖为C节点。
1.2.3 日志复制
①复制状态机
复制状态机的基本思想是一个分布式的状态机,系统由多个复制单元组成,每个复制单元均是一个状态机,它的状态保存在操作日志中。如下图所示,服务器上的一致性模块负责接收外部命令,然后追加到自己的操作日志中,它与其他服务器上的一致性模块进行通信,以保证每一个服务器上的操作日志最终都以相同的顺序包含相同的指令。一旦指令被正确复制,那么每一个服务器的状态机都将按照操作日志的顺序来处理它们,然后将输出结果返回给客户端。
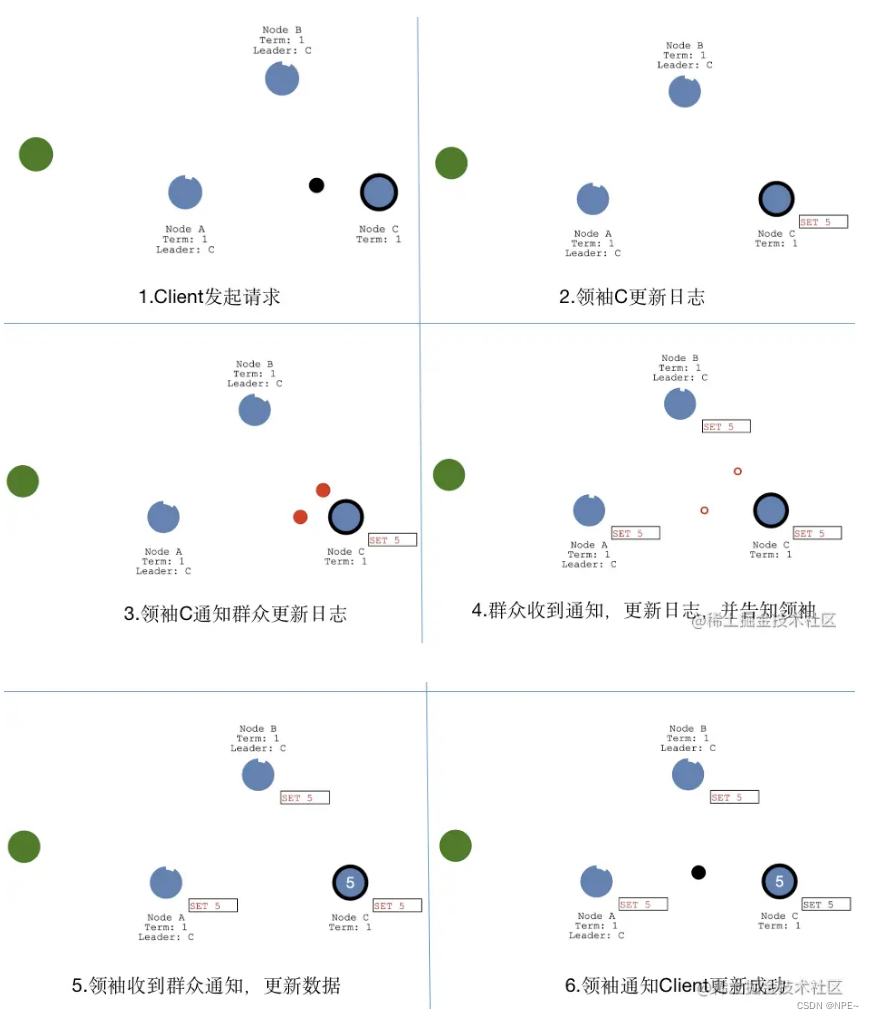
②数据同步流程
数据同步流程,借鉴了“复制状态机”的思想,都是先“提交”,再“应用”。当Client发起数据更新请求,请求会先到领袖节点C,节点C会更新日志数据,然后通知群众节点也更新日志,当群众节点更新日志成功后,会返回成功通知给领袖C,至此完成了“提交”操作;当领袖C收到通知后,会更新本地数据,并通知群众也更新本地数据,同时会返回成功通知给Client,至此完成了“应用”操作,如果后续Client又有新的数据更新操作,会重复上述流程。
③日志原理
日志的是以条目(Entry)的方式顺序组织在一起的,日志中包含index、term、type和data等字段。index随日志条目的递增而递增,term是生成该条目的leader当时处于的term。type是etcd定义的字段,目前有两个类型,一个是EntryNormal正常的日志,EntryConfChange是etcd本身配置变化的日志。data是日志的内容。

内存中的日志操作,主要是由一个raftLog类型的对象完成的,以下是raftLog的源码。可以看到,里面有两个存储位置,一个是storage是保存已经持久化过的日志条目。unstable是保存的尚未持久化的日志条目。
type raftLog struct {
// storage contains all stable entries since the last snapshot.
//这里还是一个内存存储,保存了从上一个snapshot起,已经持久化了的日志条目。
storage Storage
// unstable contains all unstable entries and snapshot.
// they will be saved into storage.
// 保存了尚未持久化的日志条目或快照。
unstable unstable
// committed is the highest log position that is known to be in
// stable storage on a quorum of nodes.
//指示当前已经确认的被半数以上节点同步过的最新日志index
committed uint64
// applied is the highest log position that the application has
// been instructed to apply to its state machine.
// Invariant: applied <= committed
//指示已经作用到状态机中的最新日志条目的index
applied uint64
logger Logger
持久化日志: WAL和snapshot。下图显示持久化的Storage接口定义和storage结构中字段的定义。它实际上就是包含一个WAL来保存日志条目,一个Snapshotter负责保存日志快照的。
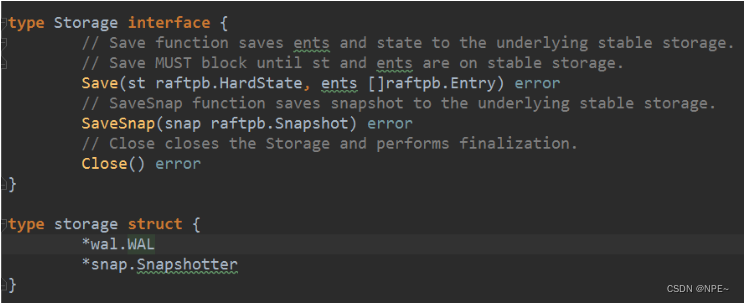
WAL是一种追加的方式将日志条目一条一条顺序存放在文件中。存放在WAL的记录都是walpb.Record形式的结构。Type代表数据的类型,Crc是生成的Crc校验字段。Data是真正的数据。
参考:https://mp.weixin.qq.com/s/o_g5z77VZbImgTqjNBSktA
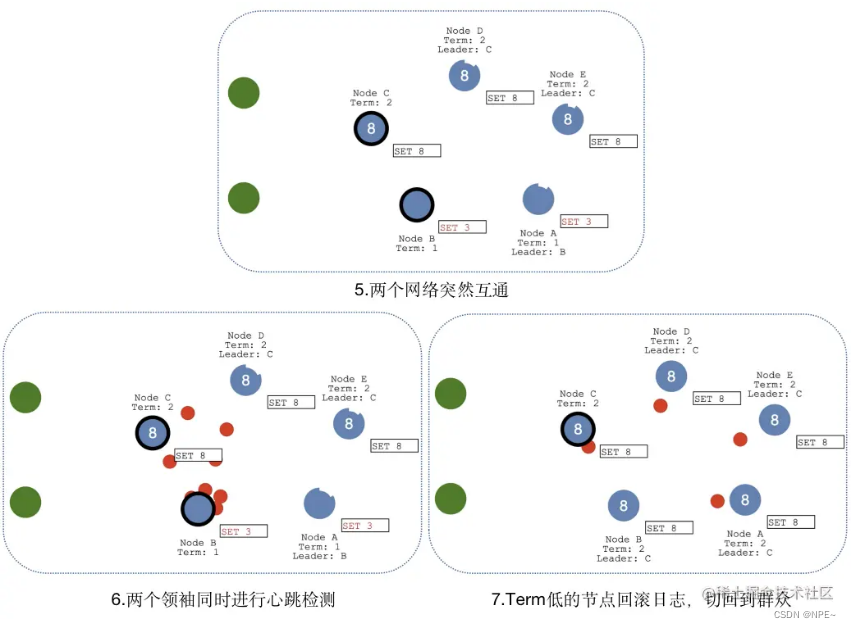
1.2.4 脑裂情况(网络问题,出现多个master)
当网络问题导致脑裂,出现双Leader情况时,每个网络可以理解为一个独立的网络,因为原先的Leader独自在一个区,所以向他提交的数据不可能被复制到大多数节点上,所以数据永远都不会提交,这个可以在第4幅图中提现出来(SET 3没有提交)。
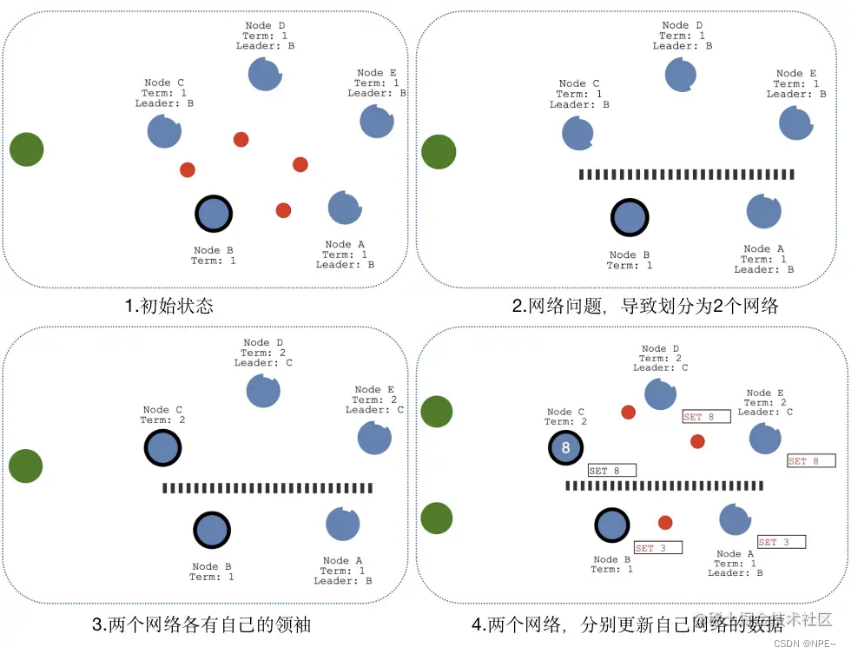
当网络恢复之后,旧的Leader发现集群中的新Leader的Term比自己大,则自动降级为Follower,并从新Leader处同步数据达成集群数据一致
脑裂情况其实只是异常情况的一种,当Leader通知Follower更新日志、Leader提交更新时,都存在各种异常情况导致的问题,这个我就不再详述了,具体可以参考《云原生分布式存储基石-etcd深入解析》书中的“1.4.3 异常情况”这一章,里面讲述的比较清楚。
1.3 安装
- 下载压缩包(尽量选择在
~目录下下载)
- 通过github直接下载,然后ftp上传到linux。Github地址:https://github.com/etcd-io/etcd/releases,根据自己linux版本下载
- 如果github访问过慢的话,可以通过华为镜像网站下载:https://mirrors.huaweicloud.com/etcd/
- curl直接下载;curl -O https://github.com/etcd-io/etcd/releases/download/v3.4.24/etcd-v3.4.24-linux-amd64.tar.gz
PS:curl默认不支持Https,命令#curl -V(V大写)查看Protocols项有没有https ,如果没有就要用命令:# yum install openssl-devel 装SSL
- 解压缩
tar -zxvf etcd-v3.4.6-linux-amd64.tar.gz
- 配置环境变量
将文件夹中etcd和etcdctl两个文件添加可执行文件路径到环境变量PATH中。
- etcd是服务端,etcdctl是运维人员操作的控制端,一般只需要装etcd,现在是学习就都装在同一台机器。
- PS:用echo $PATH查看自己的环境变量路径
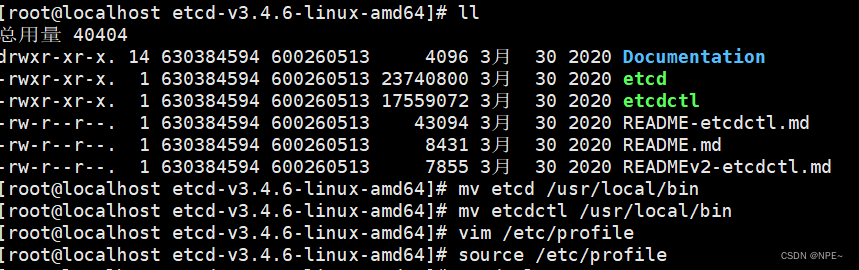
# 移动可执行文件位置
mv etcd /usr/local/bin
mv etcdctl /usr/local/bin
# 修改profile文件,
vim /etc/profile
# 在文件最后加入变量,因为etcd默认使用V2版本,我们需要V3版本的API。
export ETCDCTL_API=3
# 使环境变量生效
source /etc/profile
4. 查看版本信息
etcdctl version

- 创建etcd配置文件,一定需要确认用户对数据目录etcd有读写权限,否则服务可能无法正确启动
[root@Cent0S7 ~]# mkdir -p /var/lib/etcd/
[root@Cent0S7 ~]# cat <<EOF | sudo tee /etc/etcd.conf
#节点名称
ETCD_NAME=$(hostname -s)
#数据存放位置
ETCD_DATA_DIR=/var/lib/etcd/
EOF
注意:5以后的操作根据自己需求可选
- 创建开机启动文件
[root@Cent0S7 ~]# cat <<EOF | sudo tee /etc/systemd/system/etcd.service
[Unit]
Description=Etcd Server
Documentation=https://github.com/coreos/etcd
After=network.target
[Service]
User=root
Type=notify
#这个文件特别关键,etcd使用的环境变量都需要通过环境变量文件读取
EnvironmentFile=-/etc/etcd.conf
ExecStart=/usr/local/bin/etcd
Restart=on-failure
RestartSec=10s
LimitNOFILE=40000
[Install]
WantedBy=multi-user.target
EOF
- 重新加载配置 & 开机启动 & 启动etcd
[root@Cent0S7 ~]# systemctl daemon-reload && systemctl enable etcd && systemctl start etcd
开机启动,设置状态enabled:
[root@Cent0S7 ~]# systemctl list-unit-files etcd.service
UNIT FILE STATE
etcd.service enabled
1 unit files listed.
查看etcd状态:
[root@Cent0S7 ~]# systemctl show etcd.service
Type=notify
Restart=on-failure
NotifyAccess=main
RestartUSec=10s
TimeoutStartUSec=1min 30s
TimeoutStopUSec=1min 30s
WatchdogUSec=0
WatchdogTimestamp=Sun 2020-11-29 22:44:07 CST
WatchdogTimestampMonotonic=9160693425
------ 剩余内容 (略) -------
- 查看端口是否启动
[root@Cent0S7 ~]# netstat -an |grep 2379
tcp 0 0 127.0.0.1:2379 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:53156 127.0.0.1:2379 ESTABLISHED
tcp 0 0 127.0.0.1:2379 127.0.0.1:53156 ESTABLISHED
CentOS默认没有装netstat,需要 # yum install -y net-tools 自己装
2 使用
2.1 put(新增、修改)
# 设置值 etcdctl put KEY VALUE
etcdctl put myKey "this is etcd"
# 取值 etcdctl get KEY
etcdctl get myKey

2.2 get(查询)
# 1. 根据key值查询
etcdctl get name1
# 2. 返回结果不显示key,只显示value
etcdctl get --print-value-only name1
# 3. 按key前缀查找
etcdctl get --prefix name
# 4. 按key的字节排序查找
etcdctl get --from-key name2
# 5. 查询所有key
etcdctl get --from-key ""
2.3 del(删除)
# 1. 删除指定key
etcdctl del name11
# 2. 删除指定前缀的key
etcdctl del --prev-kv --prefix name
# 3. 删除所有key
etcdctl del --prefix ""
3 etcd+grpc实现服务注册与发现(windows)
项目结构:
3.1 本地docker启动etcd
本地安装好docker环境,或者直接下载docker-desktop
- 搭建教程参考:https://editor.csdn.net/md/?articleId=130749488
- 拉取镜像
docker pull bitnami/etcd
- 运行
docker run -d --name Etcd-server --publish 2379:2379 --env ALLOW_NONE_AUTHENTICATION=yes --env ETCD_ADVERTISE_CLIENT_URLS=http://localhost:2379 bitnami/etcd:latest

3.2 编写proto文件
server.proto
syntax = "proto3";
option go_package = ".;rpc";
message Empty {
}
message HelloResponse {
string hello = 1;
}
message RegisterRequest {
string name = 1;
string password = 2;
}
message RegisterResponse {
string uid = 1;
}
service Server {
rpc Hello(Empty) returns(HelloResponse);
rpc Register(RegisterRequest) returns(RegisterResponse);
}
通过脚本,生成对应的go代码
生成之前,先在client和server目录下分别创建好rpc目录
gen.sh:
echo "生成rpc server代码"
# 输出目录
OUT=../server/rpc
# protoc脚本及参数
protoc \
--go_out=${OUT} \
--go-grpc_out=${OUT} \
--go-grpc_opt=require_unimplemented_servers=false \
server.proto
echo "生成rpc client代码"
OUT=../client/rpc
protoc \
--go_out=${OUT} \
--go-grpc_out=${OUT} \
--go-grpc_opt=require_unimplemented_servers=false \
server.proto
# 也可以直接在终端执行命令
# 生成server下相关的
protoc --go_out=../server/rpc --go-grpc_out=../server/rpc --go-grpc_opt=require_unimplemented_servers=false server.proto
# client相关的
protoc --go_out=../client/rpc --go-grpc_out=../client/rpc --go-grpc_opt=require_unimplemented_servers=false server.proto

3.3 server端
①etcd.go:
package main
import (
"context"
"fmt"
clientv3 "go.etcd.io/etcd/client/v3"
"go.etcd.io/etcd/client/v3/naming/endpoints"
"log"
)
const etcdUrl = "http://localhost:2379"
const serviceName = "chihuo/server"
const ttl = 10
var etcdClient *clientv3.Client
func etcdRegister(addr string) error {
log.Printf("etcdRegister %s\b", addr)
etcdClient, err := clientv3.NewFromURL(etcdUrl)
if err != nil {
return err
}
em, err := endpoints.NewManager(etcdClient, serviceName)
if err != nil {
return err
}
lease, _ := etcdClient.Grant(context.TODO(), ttl)
err = em.AddEndpoint(context.TODO(), fmt.Sprintf("%s/%s", serviceName, addr), endpoints.Endpoint{
Addr: addr}, clientv3.WithLease(lease.ID))
if err != nil {
return err
}
//etcdClient.KeepAlive(context.TODO(), lease.ID)
alive, err := etcdClient.KeepAlive(context.TODO(), lease.ID)
if err != nil {
return err
}
go func() {
for {
<-alive
fmt.Println("etcd server keep alive")
}
}()
return nil
}
func etcdUnRegister(addr string) error {
log.Printf("etcdUnRegister %s\b", addr)
if etcdClient != nil {
em, err := endpoints.NewManager(etcdClient, serviceName)
if err != nil {
return err
}
err = em.DeleteEndpoint(context.TODO(), fmt.Sprintf("%s/%s", serviceName, addr))
if err != nil {
return err
}
return err
}
return nil
}
②server.go:
package main
import (
"context"
"fmt"
"go_code/demo01/study/etcd-grpc/server/rpc"
)
type Server struct {
}
// server.proto文件中 服务提供的方法
// rpc Hello(Empty) returns(HelloResponse);
func (s Server) Hello(ctx context.Context, request *rpc.Empty) (*rpc.HelloResponse, error) {
//server.proto定义的HelloResponse中只有一个string参数
resp := rpc.HelloResponse{
Hello: "hello client."}
return &resp, nil
}
/*
server.proto文件中定义的格式,因此设置resp.uid
message RegisterResponse {
string uid = 1;
}
*/
func (s Server) Register(ctx context.Context, request *rpc.RegisterRequest) (*rpc.RegisterResponse, error) {
resp := rpc.RegisterResponse{
}
resp.Uid = fmt.Sprintf("%s.%s", request.GetName(), request.GetPassword())
return &resp, nil
}
③main.go:
package main
import (
"context"
"flag"
"fmt"
"go_code/demo01/study/etcd-grpc/server/rpc"
"google.golang.org/grpc"
"log"
"net"
"os"
"os/signal"
"syscall"
)
func main() {
var port int
flag.IntVar(&port, "port", 8001, "port")
flag.Parse()
addr := fmt.Sprintf("localhost:%d", port)
//关闭信号处理
ch := make(chan os.Signal, 1)
signal.Notify(ch, syscall.SIGTERM, syscall.SIGINT, syscall.SIGKILL, syscall.SIGHUP, syscall.SIGQUIT)
go func() {
//开启协程从ch管道中读取,如果有服务停止,则注销etcd中的服务
s := <-ch
//处理etcd中服务的注销流程
etcdUnRegister(addr)
if i, ok := s.(syscall.Signal); ok {
os.Exit(int(i))
} else {
os.Exit(0)
}
}()
//注册服务
err := etcdRegister(addr)
if err != nil {
panic(err)
}
lis, err := net.Listen("tcp", addr)
if err != nil {
panic(err)
}
grpcServer := grpc.NewServer(grpc.UnaryInterceptor(UnaryInterceptor()))
rpc.RegisterServerServer(grpcServer, Server{
})
log.Printf("service start port %d\n", port)
if err := grpcServer.Serve(lis); err != nil {
panic(err)
}
}
func UnaryInterceptor() grpc.UnaryServerInterceptor {
return func(ctx context.Context, req interface{
}, info *grpc.UnaryServerInfo, handler grpc.UnaryHandler) (resp interface{
}, err error) {
log.Printf("call %s\n", info.FullMethod)
resp, err = handler(ctx, req)
return resp, err
}
}
3.4 client端
client.go:
package main
import (
"context"
"fmt"
clientv3 "go.etcd.io/etcd/client/v3"
"go.etcd.io/etcd/client/v3/naming/resolver"
rpc2 "go_code/demo01/study/etcd-grpc/client/rpc"
"google.golang.org/grpc/balancer/roundrobin"
"google.golang.org/grpc/credentials/insecure"
"log"
"time"
"google.golang.org/grpc"
)
const etcdUrl = "http://localhost:2379"
const serviceName = "chihuo/server"
func main() {
//bd := &ChihuoBuilder{addrs: map[string][]string{"/api": []string{"localhost:8001", "localhost:8002", "localhost:8003"}}}
//resolver.Register(bd)
//获取etcd客户端
etcdClient, err := clientv3.NewFromURL(etcdUrl)
if err != nil {
panic(err)
}
etcdResolver, err := resolver.NewBuilder(etcdClient)
//通过grpc与服务建立连接
conn, err := grpc.Dial(fmt.Sprintf("etcd:///%s", serviceName), grpc.WithResolvers(etcdResolver), grpc.WithTransportCredentials(insecure.NewCredentials()), grpc.WithDefaultServiceConfig(fmt.Sprintf(`{"LoadBalancingPolicy": "%s"}`, roundrobin.Name)))
if err != nil {
fmt.Printf("err: %v", err)
return
}
//rpc2 "go_code/demo01/study/etcd-grpc/client/rpc"
//通过连接conn获取ServerClient(与服务器相互通信)
ServerClient := rpc2.NewServerClient(conn)
for {
//通过客户端发起远程调用【请求服务端的Hello方法】,接受服务器的返回结果
helloRespone, err := ServerClient.Hello(context.Background(), &rpc2.Empty{
})
if err != nil {
fmt.Printf("err: %v", err)
return
}
log.Println(helloRespone, err)
time.Sleep(500 * time.Millisecond)
}
}
3.5 测试效果
- 启动三个server,并向etcd注册服务
//1. 进入server/main.go所在目录
go run . --port 8081
go run . --port 8082
go run . --port 8083
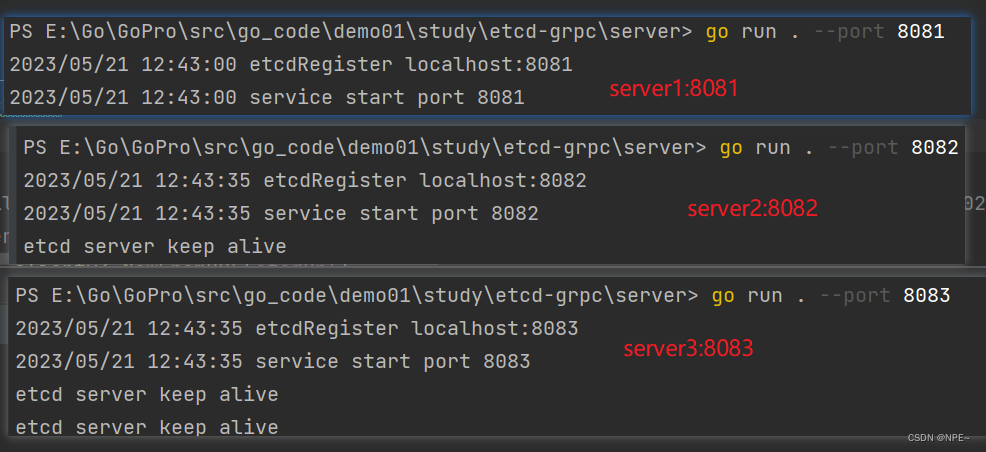
可以,看到我们已经启动了三个服务端,并且已经向etcd注册成功
- 启动一个client端,通过etcd拉取服务

- 观察三个server的打印,可以发现,client端的请求时负载均衡的,每个server都有可能被访问到
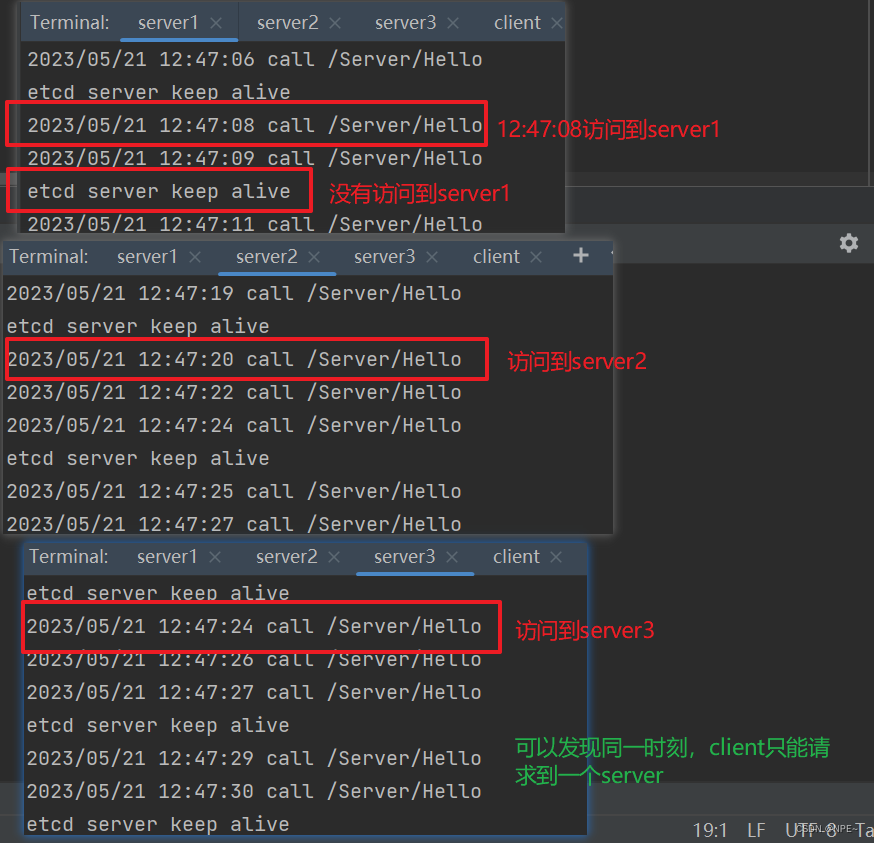
- 我们停止server3,发现client的请求被均衡的分发到server1、server2
表明server3已经从etcd中被踢出【服务上线下线】
- 由于请求过快,因此,可能效果不明显,大家可以将时间打印的更细致一点
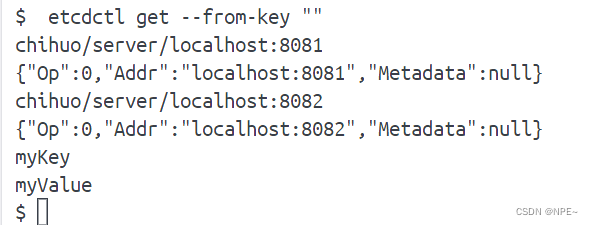
进入docker部署的etcd内部,查询所有的key:
4 ETCD-V3版本变动
4.1 watch机制
etcdv2中的键被废除以后,为了能够跟踪key的变化,使用了事件机制进行跟踪,维护键的状态,来防止被删除掉的键还能恢复和watch到,但是有一个滑动窗口的大小限制,那么如果要获取1000个时间之前的键就获取不到了。因此etcdv2中通过watch来同步数据不是那么可靠,断开连接一段时间后就会导致有可能中间的键的改动获取不到了。在etcdv3中支持get和watch键的任意的历史版本记录。
另外,v2中的watch本质上还是建立很多HTTP连接,每一个watch建立一个tcp套接字连接,当watch的客户端过多的时候会大大消耗服务器的资源,如果有数千个客户端watch数千个key,那么etcd v2的服务端的socket和内存资源会很快被耗尽。v3版本中的watch可以进行连接复用,多个客户端可以共用相同的TCP连接,大大减轻了服务器的压力。
总结一下,其实这里主要进行2点优化:
- 实时监听key的更新:解决v2中途key的数据更新,客服端不会感知的问题;
- 多路复用:这个可以想到select和epool模型,就是一个客户之前需要建立多个TCP连接,现在只需要建立一个即可。
etcd-V3版本:可以跟踪的key个数不受限制了,消耗资源更少了
参考:
https://www.cnblogs.com/wutou/p/14056868.htm
https://blog.csdn.net/weixin_34067980/article/details/92961304