需要源码和数据集请点赞关注收藏后评论区留言私信~~~
一、matplotlib可视化客流
是2D图形最常用的Python软件包之一,是很多高级可视化库的基础,它不是python内置库,调用前需要手动安装,且依赖numpy库。同时作为Python中的数据可视化模块,能够创建多种类型的图表,如条形图、散点图、饼状图、柱状图、折线图等
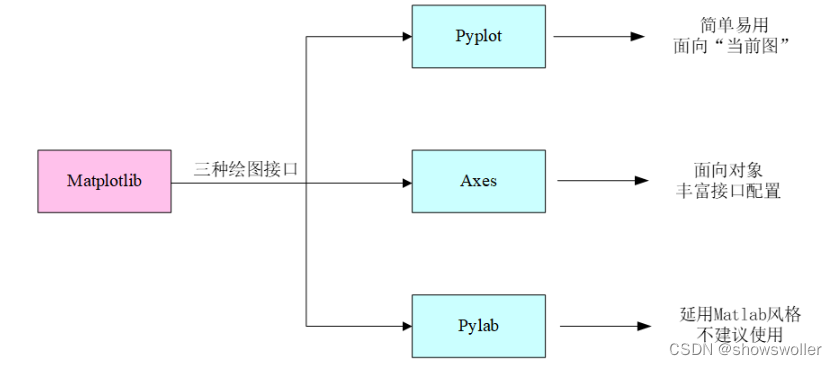
使用matplotlib库绘图时,一般都是调用pyplot模块,其集成了绝大部分常用方法接口,共同完成各种丰富的绘图功能。同时需要重点指出:figure和axes,也是其中的接口形式,前者为所有绘图操作定义了顶层类对象figure,相当于提供画板;后者则定义了画板中的每一个绘图对象axes,相当于画板内的各个子图。另外,matplotlib中还有另一个重要模块——pylab,其定位是Python中对Matlab的替代产品,不仅包含绘图功能,还有矩阵运算功能,总之凡是Matlab可以实现的功能,pylab都可以实现。虽然pylab功能强大,但因为其集成了过多的功能,直接调用并非一个明智选择,官方已不建议用其绘图。
以上介绍的Matplotlib的三种绘图接口形式如图 1 15 Matplotlib三种绘图接口所示
matplotlib的基本操作此处不再赘述,需要的看我之前的博客即可
下面对地体的客流数据进行可视化绘制
bar/barh:条形图或者柱状图,常用于表达一组离散数据的大小关系,比如一年内某个车站每个月的客流数据;默认竖直条形图,可选barh绘制水平条形图。
具体函数及相关参数为:plt.bar ( x, height, width = 0.8, bottom = None, color)。
其中:x为一个标量序列,确定x轴刻度数目;height用来确定y轴的刻度;width为单个直方图的宽度;bottom用来设置y边界坐标轴起点;color用来设置直方图颜色。(只给出一个值表示全部使用该颜色,若赋值颜色列表则会逐一染色,若给出颜色列表数目少于直方图数目则会循环利用)。
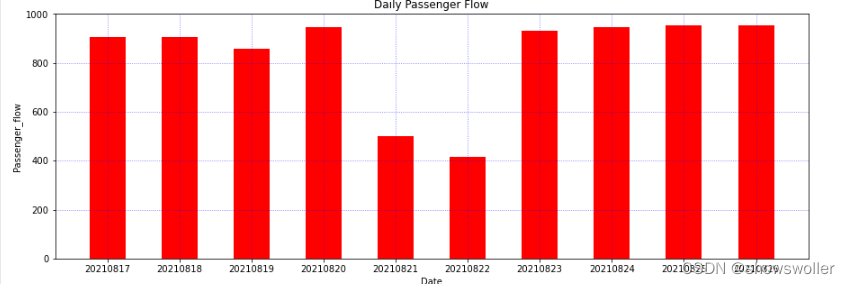
以某城市地铁近10日的客流数据为例,绘制柱状图
pie:饼图,主要用于表达构成或比例关系,一般适用于少量对比。
具体函数及相关参数为:plt.pie( x, labels, explode, startangle, shadow, labeldistance, radius)。
其中:x 为(每一块的)比例,如果sum(x) > 1,会使用sum (x)归一化;labels 为(每一块)饼图外侧显示的说明文字;explode为(每一块)离开中心距离,默认为0;startangle为起始绘制角度,默认图是从x轴正方向逆时针画起,如设定为90,则从y轴正方向画起;shadow表示在饼图下面画一个阴影。默认值:False,即不画阴影;labeldistance为label标记的绘制位置,相对于半径的比例,默认为1.1,如<1则绘制在饼图内侧;radius用来控制饼图半径,默认值为1。
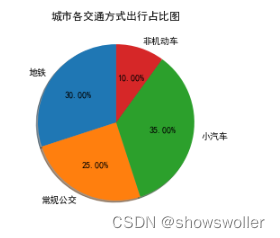
接下来以城市各种交通出行方式占比为例,绘制饼状图
部分代码如下
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['axes.unicode_minus'] = False
# 确定柱状图数量,代表最近10天
x = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
# 确定y轴刻度,代表每一天的地铁客流量
y = [904.8, 903.9, 857.13, 944.49, 498.72, 416.39, 930.74, 946.14, 953.54, 953.55]
x_label = ['20210817', '20210818', '20210819', '20210820', '20210821', '20210822', '2021082inestyle=':', color='b', alpha=0.6)
plt.xlabel('Date')
plt.ylabel('Passenger_flow')
plt.title('Daily Passenger Flow')
plt.show()
import matplotlib.pyplot as plt
plt.r= [30, 25, 35, 10]
plt.pie(sizes, labels=labels, shadow=True, autopct='%1.2f%%', startangle=90)
plt.title('城市各交通方式出行占比图')
plt.show()二、随机森林进行回归预测
随机森林是一种由多个决策树构成的集成算法,在分类和回归问题上都有不错的表现。在解释随机森林以前,需要简单介绍一下决策树。决策树是一种很简单的算法,解释性强,也符合人类的直观思维。这是一种基于if-then-else规则的有监督学习算法。
随机森林就是由很多决策树构成的,不同决策树之间没有关联。当我们进行分类任务时,新的输入样本进入,森林的每棵决策树分别进行判断分类,每个决策树会得到一个自己的分类结果,分类结果中哪一个分类最多,随机森林就会把这个结果当作最终结果。 随机森林作为解决分类、回归问题的集成算法,具有以下的优点
(1) 对于大部分资料,可以产生高准确度的分类器;
(2) 可以处理大量的输入变量;
(3) 随机性的引入,不容易过拟合;
(4) 能处理离散型和连续性数据,无需规范化。
同样,在利用随机森林解决分类、回归问题时,也存在以下的缺点:
(1) 在某些噪音较大的分类或回归问题上会过拟合;
(2) 同一属性,有不同取值的数据中,取值划分较多的属性会对随机森林产生更大的影响,在该类数据上产出的属性权值是不可信的;
(3) 森林中的决策树个数很多时,训练需要的时间和空间会较大
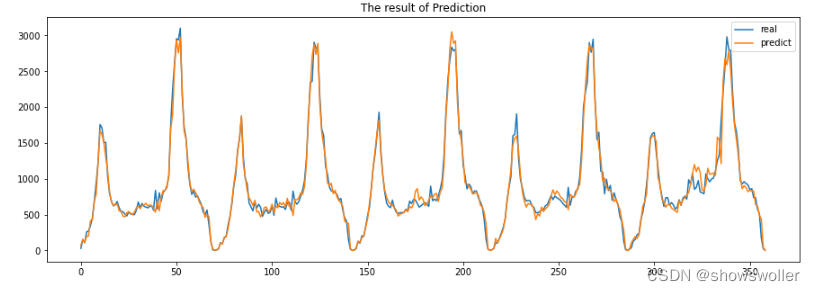
此处以北京西直门地铁站的进站客流数据为例,通过sklearn的随机森林算法对客流进行预测
首先利用Pandas导入西直门地铁站每15min的进站客流量,并且利用matplotlib绘制客流曲线图
考虑到客流量大小受先前客流影响,此处新增该时刻地铁客流的前一个15min客流量、该时刻前五个15min的平均客流量以及前十个15min的平均客流量,以此提高客流预测的准确率,同时删除异常数据NULL的所在行,避免影响预测。取数据集的80%作为训练集,20%作为测试集
考虑到客流量大小受先前客流影响,此处新增该时刻地铁客流的前一个15min客流量、该时刻前五个15min的平均客流量以及前十个15min的平均客流量,以此提高客流预测的准确率,同时删除异常数据NULL的所在行,避免影响预测。取数据集的80%作为训练集,20%作为测试集
可见拟合效果十分不错,除了一些极大值点有些出入其他预测的基本相同
部分代码如下
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.ensemble import RandomForestRegressor
# 导入西直门地铁站点15min进站客流
df = pd.read_csv('./xizhimen.csv', encoding="gbk", parse_dates=True)
len(df)
df.head() # 观察数据集,这是一个单变量时间序列
plt.figure.iloc[:, 0], df.iloc[:, 1], label="XiZhiMen Station")
plt.legend()
plt.show()
# 增加前一天的数据
df['pre_date_flow'] = df.loc[:, ['p_flow']].shift(1)
# 5日移动平均
df['MA5'] = df['p_flow'].rolling(5).mean()
# 10日移动hape[0])
X_length = X.shape[0]
split = int(X_length * 0.8)
X_train, X_test = X[:split], X[split:]
y_train, y_test = y[:split], y[split:]
print()
random_forest_regressor = RandomForestRegressor(n_estimators=15)
# 拟合模型
random_forest_regressor.fit(X_train, y_train)
score = random_forest_regressor.score(X_test, y_test)
result = random_forest_regressor.predict(X_test)
ravel(), label='real')
plt.plot(result, label = 'predict')
plt.legend()
plt.show()创作不易 觉得有帮助请点赞关注收藏~~~