需要源码和数据集请点赞关注收藏后评论区留言私信~~~
在进行时间序列预测之前,我们先来简单的介绍一下RNN循环神经网络和LSTM神经网络
一、RNN循环神经网络
对于普通神经网络,例如多层感知机,其前一个输入和后一个输入完全没有联系,导致在处理时间序列问题时,难以精准刻画时间序列中的时间关系。为了更好地处理时间序列问题,学者提出了循环神经网络结构(Recurrent Neural Network),最基本的循环神经网络由输入层、一个隐藏层和一个输出层组成

如果去掉有W的带箭头的连接线,即为普通的全连接神经网络。其中,X是一个向量,代表输入层的值;S是一个向量,表示隐藏层的值,其不仅仅取决于当前的输入X,还取决于上一时刻隐藏层的值;O也是一个向量,它表示输出层的值;U是输入层到隐藏层的权重矩阵;V是隐藏层到输出层的权重矩阵;W是隐藏层上一时刻的值作为当前时刻输入的权重矩阵
把RNN结构按照时间线展开

网络在t时刻接收到输入X_t之后,隐藏层的值是S_t,输出值是O_t,S_t的值不仅仅取决于X_t,还取决于S_t−1,因此,在RNN结构下,当前时刻的信息在下一时刻也会被输入到网络中,网络中的信息形成时间相关性,解决了处理时间序列的问题。神经网络模型“学”到的东西隐含在“权值”W中。基础的神经网络只在层与层之间建立全连接,而RNN与它们最大的不同之处在于同一层内的神经元在不同时刻也建立了全连接,即W与时间有关
RNN的四种结构:
one to one结构

最典型的神经网络属于one to one结构,这种结构为给定一个输入值来预测一个输出值
one to many和many to one结构
当输入值为一个输出值为多个的时候,比如在网络中输入一个关键字,通过网络输出一首以这个关键字为主题的诗歌,就是一个one to many的场景。当输入值为多个,输出值为一个时,比如输入一段语音判断这段语音的情感分类,再比如输入以往的股票信息判断未来是涨还是跌,诸如此类的分类等问题就是many to one的场景
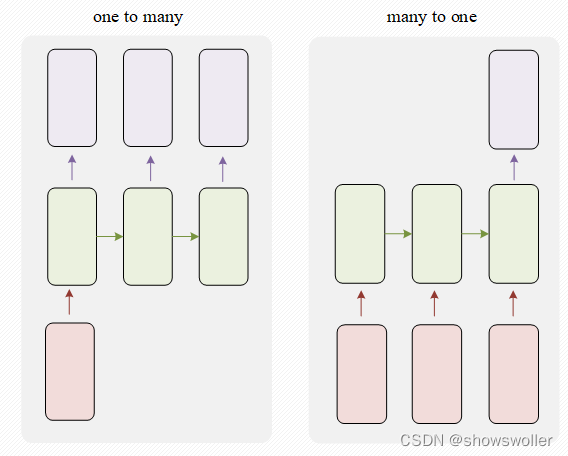
many to many结构
第一个many to many结构适用于机器翻译、自动问答等场景,比如输入一句英文,输出一句中文,输入与输出的都是序列。第二种many to many的结构适用于视频每一帧的分类和命名实体标记等领域,比如输入一段视频,将其每一帧进行分类

二、LSTM
RNN和LSTM最大区别在于分布在隐藏层的神经元结构,传统RNN的神经元结构简单,例如仅包含一个激活函数层。LSTM的记忆单元(Block)更加复杂,LSTM模型中增加了状态c,称为单元状态(cell state),用来保存长期的状态,而LSTM的关键,就是怎样控制长期状态c

LSTM使用三个控制开关,第一个开关负责控制如何继续保存长期状态c,第二个开关负责控制把即时状态输入到长期状态c,第三个开关负责控制是否把长期状态c作为当前的LSTM的输入。图 1 16中的三个开关分别是使用三个门来控制的,这种去除和增加单元状态中信息的门是一种让信息选择性通过的方法
LSTM用两个门来控制单元状态c的内容,一是遗忘门(forget gate),遗忘门决定了上一时刻的单元状态c_(t-1)有多少保留到当前时刻c_t,二是输入门(input gate),输入门决定了当前时刻网络的输入x_t有多少保存到单元状态c_t。LSTM用输出门(output gate)来控制单元状态c_t有多少输出到LSTM的当前输出值h_t。下面对这三个门进行逐一介绍,下图中,黄色矩形是学习得到的神经网络层,粉色的圆形表示运算操作,箭头表示向量的传输过程

W_f是遗忘门的权重矩阵,[ℎ_t−1,x_t]表示把两个向量连接成一个更长的向量,b_f是遗忘门的偏置项,σ是sigmoid函数

sigmoid函数称为输入门,决定将要更新什么值,tanh层创建一个新的候选值向量,C̃t会被加入到状态中
在遗忘门的控制下,网络可以保存很久之前的信息,在输入门的控制下,无用信息无法进入到网络当中
输出门控制了长期记忆对当前输出的影响,由输出门和单元状态共同确定
LSTM的核心是单元的状态,单元状态的传递类似于传送带,直接在整个时间链上运行,中间值有一些少量的线性交互,便于保存相关信息

三、PyTorch实现LSTM时间序列预测
下面以2016年北京地铁西直门站时间粒度为15分钟的进站客流数据为例,利用PyTorch搭建LSTM网络,实现对进站客流数据的预测
将数据导入后可视化如下
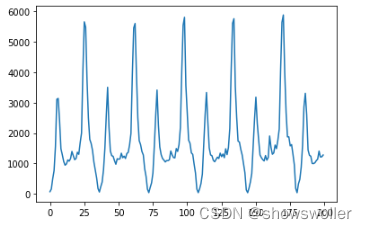
从输出的客流图可以看出,西直门从早到晚地铁站的客流变化趋势还是很有规律的,并且能够明显的观察到一天中的客流早晚高峰情况。接着把处理后的数据输入到LSTM模型里面进行训练,希望通过LSTM模型来预测客流
下面开始数据预处理,去掉无效数据,并且将数据归一化到[0, 1]之间,数据的归一化在深度学习中可以提升模型的收敛速度和精度。 使用dropna()函数去掉数据中的空值所在的行和列,使用astype变化数组类型,并且手动将数据集中的数据值大小固定到[0, 1]
下面开始数据预处理,去掉无效数据,并且将数据归一化到[0, 1]之间,数据的归一化在深度学习中可以提升模型的收敛速度和精度。 使用dropna()函数去掉数据中的空值所在的行和列,使用astype变化数组类型,并且手动将数据集中的数据值大小固定到[0, 1]
划分训练集和测试集,70%的数据作为训练集,30%的数据作为测试集
改变数据维度,对一个样本而言,序列只有一个,所以batch_size=1,我们根据前两个时间粒度预测第三个,所以feature=2
定义模型并将输出值回归到流量预测的最终结果,模型的第一部分是一个两层的RNN
输入维度是8,隐藏层维度为50,其中隐藏层维度可以任意指定,使用均方损失函数
开始训练模型,这里我们训练100个epoch,每5次输出一次训练结果,即Loss值,训练结果如下

通过训练过程中输出的Loss值可以看到,损失值在逐渐下降,模型训练还是比较有效果的。训练完成后,转换成测试模式,开始预测客流并且输出预测结果
将实际结果和预测结果用matplotlib包画图输出,其中真实数据用蓝色表示,预测的结果用橙色表示

训练后的LSTM模型预测的客流数据可以比较准确的拟合真实客流数据,说明LSTM模型的时间序列预测能力是比较好的,但是也可以明显的看到对于极大值和极小值LSTM预测的仍然有些出入,尤其是极大值,相差较大,这也是模型改进的一个目标方向
最后 部分代码如下
import torch
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
# % matplotlib inline
from torch import nn
from torch.autograd import Variable
data_csv = pd.read_csv("./LSTM.csv")
data_csv.head()
data_csv = data_csv.dropna()
dataset = data_csv.values
dataset = dataset.astype('float32')
max_value = np.max(dataset)
min_value = np.min(dataset)
scalar = max_value - min_value
dataset = list(map(lambda x: (x-min_value) / scalar, dataset))
def create_dataset(dataset, step=8):
dataX, dataY = [], []
for i in range(len(dataset) - step):
a = dataset[i:(i + step)]
dataX.append(a)
dataY.append(dataset[i + step])
return np.array(dataX), np.array(dataY)
train_size = int(len(data_X) * 0.7)
test_size = len(data_X) - train_size
train_X = data_X[:train_size]
train_Y = data_Y[:train_size]
test_X = data__Y.reshape(-1, 1, 1)
test_X = test_X.reshape(-1, 1, 8)
test_Y = test_Y.reshape(-1, 1, 1)
train1 = torch.Module):
def __init__(self, input_size, hidden_size, output_size=1, num_layers=2):
super(lstm_linear, self).__init__()
self.lstm = nn.LSTM(input_size, hidden_size, num_layers) # rnn
self.linear = nn.Linear(hidden_size, output_size) # 回归
def forward(self, x):
x, _ = self.lstm(x) # (seq, batch, hidden)
s, b, h = x.shape
x = x.view(s*b, h) # 转换成线性层的输入格式
x = self.linear(x)
x = x.view(s, b, -1)
return x
# 开始训练
for e .zero_grad()
loss.backward()
optimizer.step()
if (e + 1) % 5 == 0:
print('Epoch: {}, Loss: {:.5f}'.format(e + 1, loss.item()))
# 画出实际结果和预测的结果
plt.plot(test2, label='real')
plt.plot(pred_test,label='prediction')
plt.legend(loc='best')创作不易 觉得有帮助请点赞关注收藏~~~