随机森林中的特征重要性
随机森林算法示意图
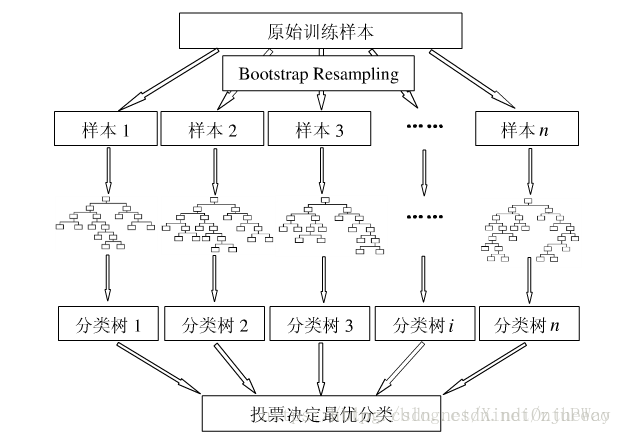
利用随机森林选择特征可参看论文Variable selection using Random Forests。
用随机森林进行特征重要性评估的思想其实很简单,说白了就是看看每个特征在随机森林中的每颗树上做了多大的贡献,然后取个平均值,最后比一比特征之间的贡献大小。
好了,那么这个贡献是怎么一个说法呢?通常可以用基尼指数(Gini index)或者袋外数据(OOB)错误率作为评价指标来衡量。
袋外数据错误率
计算某个特征 的重要性时,具体步骤如下:
1)对每一颗决策树,选择相应的袋外数据(out of bag,OOB)计算袋外数据误差,记为 。
所谓袋外数据是指,每次建立决策树时,通过重复抽样得到一个数据用于训练决策树,这时还有大约1/3的数据没有被利用,没有参与决策树的建立。这部分数据可以用于对决策树的性能进行评估,计算模型的预测错误率,称为袋外数据误差。
这已经经过证明是无偏估计的,所以在随机森林算法中不需要再进行交叉验证或者单独的测试集来获取测试集误差的无偏估计。
2)随机对袋外数据OOB所有样本的特征 加入噪声干扰(可以随机改变样本在特征 处的值),再次计算袋外数据误差,记为 。
3)假设森林中有 棵树,则特征 的重要性= 。这个数值之所以能够说明特征的重要性是因为,如果加入随机噪声后,袋外数据准确率大幅度下降(即 上升),说明这个特征对于样本的预测结果有很大影响,进而说明重要程度比较高。
举个例子
借用利用随机森林对特征重要性进行评估的例子。
以UCI上葡萄酒的例子为例,首先导入数据集。
import pandas as pd
url = 'http://archive.ics.uci.edu/ml/machine-learning-databases/wine/wine.data'
df = pd.read_csv(url, header = None)
df.columns = ['Class label', 'Alcohol', 'Malic acid', 'Ash',
'Alcalinity of ash', 'Magnesium', 'Total phenols',
'Flavanoids', 'Nonflavanoid phenols', 'Proanthocyanins',
'Color intensity', 'Hue', 'OD280/OD315 of diluted wines', 'Proline']看下数据的信息:
df.info()<class 'pandas.core.frame.DataFrame'>
RangeIndex: 178 entries, 0 to 177
Data columns (total 14 columns):
Class label 178 non-null int64
Alcohol 178 non-null float64
Malic acid 178 non-null float64
Ash 178 non-null float64
Alcalinity of ash 178 non-null float64
Magnesium 178 non-null int64
Total phenols 178 non-null float64
Flavanoids 178 non-null float64
Nonflavanoid phenols 178 non-null float64
Proanthocyanins 178 non-null float64
Color intensity 178 non-null float64
Hue 178 non-null float64
OD280/OD315 of diluted wines 178 non-null float64
Proline 178 non-null int64
dtypes: float64(11), int64(3)
memory usage: 19.5 KB可见除去class label之外共有13个特征,数据集的大小为178。
按照常规做法,将数据集分为训练集和测试集。
from sklearn.cross_validation import train_test_split
from sklearn.ensemble import RandomForestClassifier
x, y = df.iloc[:, 1:].values, df.iloc[:, 0].values
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 0)
feat_labels = df.columns[1:]
forest = RandomForestClassifier(n_estimators=10000, random_state=0, n_jobs=-1)
forest.fit(x_train, y_train)好了,这样一来随机森林就训练好了,其中已经把特征的重要性评估也做好了,我们拿出来看下。
importances = forest.feature_importances_
indices = np.argsort(importances)[::-1]
for f in range(x_train.shape[1]):
print("%2d) %-*s %f" % (f + 1, 30, feat_labels[indices[f]], importances[indices[f]]))输出的结果为:
1) Color intensity 0.182483
2) Proline 0.158610
3) Flavanoids 0.150948
4) OD280/OD315 of diluted wines 0.131987
5) Alcohol 0.106589
6) Hue 0.078243
7) Total phenols 0.060718
8) Alcalinity of ash 0.032033
9) Malic acid 0.025400
10) Proanthocyanins 0.022351
11) Magnesium 0.022078
12) Nonflavanoid phenols 0.014645
13) Ash 0.013916对的就是这么方便。
如果要筛选出重要性比较高的变量的话,这么做就可以
threshold = 0.15
x_selected = x_train[:, importances > threshold]
x_selected.shape输出为
(124,3)