目录
一、前言
以自注意力机制为核心的 Transformer 模型是各种预训练语言模型中的主要组成部分。自注意力机制能够构建序列中各个元素之间的上下文关联程度,挖掘深层次的语义信息。然而,自注意力机制的时空复杂度为,即时间和空间消耗会随着输入序列的长度呈平方级增长。这种问题的存在使得预训练语言模型处理长文本的效率较低。
传统处理长文本的方法一般是切分输入文本,其中每份的大小设置为预训练语言模型能够单次处理的最大长度(如512)。
最终将多片文本的决策结果进行综合(如对分类结果进行投票)或者拼接(如序列标注或生成任务)得到最终结果
。然而,这种方法不能很好地构建文本块之间的联系,挖掘长距离文本依赖的能力较弱。因此,更好的方法还是需要从根本上提高预训练语言模型单次能够处理的最大文本长度,从而能够更加充分地利用自注意力机制。针对这一挑战,Transformer-XL模型给出了解决方法。
二、整体概要
前面介绍到,Transformer 中处理长文本的传统策略是将文本切分成固定长度的块,并单独编码每个块,块与块之间没有信息交互。下图给出了块长度为4的一个示例。可以看到在训练阶段,Transformer分别对第一块中的序列x1
、x
2
、x
3
、x
4
与第二块中的序列x
5
、x
6
、x
7
、x
8
进行建模。而在测试阶段,由于每次处理的最大长度为4,当模型在处理序列x2
、x
3
、x
4
、x
5
时,无法构建与历史x
1
的关系。另外,由于需要以滑动窗口的方式处理整个序列,所以这种方法的效率也非常低。

为了优化对长文本的建模,Transformer-XL提出了两种改进策略——状态复用的块级别循环(Segment-level Recurrence with State Reuse)和相对位置编码(Relative Positional Encodings)。接下来针对这两种改进策略进行介绍。
三、细节描述
3.1 状态复用的块级别循环
假设两个连续的长度为n的块分别为 和
和 ,第τ 块在第l 层Transformer的隐含层输出为
,第τ 块在第l 层Transformer的隐含层输出为 ![h_{\tau }^{[l]}\in \mathbb{R}^{n\times d}](https://latex.csdn.net/eq?h_%7B%5Ctau%20%7D%5E%7B%5Bl%5D%7D%5Cin%20%5Cmathbb%7BR%7D%5E%7Bn%5Ctimes%20d%7D) (d为隐含层维度大小)。计算第τ+1块在第l层 Transformer的隐含层输出
(d为隐含层维度大小)。计算第τ+1块在第l层 Transformer的隐含层输出 ![h_{\tau+1 }^{[l]}](https://latex.csdn.net/eq?h_%7B%5Ctau+1%20%7D%5E%7B%5Bl%5D%7D) :
:

式中,函数SG(·)表示停止梯度传输;操作符
◦
表示沿长度维度进行拼接;
W
表示全连接权重。与传统Transformer的主要不同点在
于,键![k_{\tau+1 }^{[l]}](https://latex.csdn.net/eq?k_%7B%5Ctau+1%20%7D%5E%7B%5Bl%5D%7D) 和值
和值![v_{\tau+1 }^{[l]}](https://latex.csdn.net/eq?v_%7B%5Ctau+1%20%7D%5E%7B%5Bl%5D%7D) 依赖于扩展的上下文信息
依赖于扩展的上下文信息![h_{\tau+1 }^{[l-1]}](https://latex.csdn.net/eq?h_%7B%5Ctau+1%20%7D%5E%7B%5Bl-1%5D%7D) 以及上一个块
以及上一个块![h_{\tau }^{[l-1]}](https://latex.csdn.net/eq?h_%7B%5Ctau%20%7D%5E%7B%5Bl-1%5D%7D) 的缓存信息
。
的缓存信息
。
这种状态复用的块级别循环机制应用于语料库中每两个连续的片段,本质上是在隐含状态下产生一个片段级的循环。因此,在这种机制下,Transformer利用的有效上下文可以远远超出两个块。需要注意的是, 和![h_{\tau}^{[l-1]}](https://latex.csdn.net/eq?h_%7B%5Ctau%7D%5E%7B%5Bl-1%5D%7D) 之间的循环依赖性使得存在向下一层的计算依赖,这与传统的循环神经网络(RNN)中的同层循环机制(即只存在相同层之间的循环)是不同的。因此,最大可能的依赖长度随块的长度n和层数L呈线性增长(与开头提到的平方级增长形成对比),即
之间的循环依赖性使得存在向下一层的计算依赖,这与传统的循环神经网络(RNN)中的同层循环机制(即只存在相同层之间的循环)是不同的。因此,最大可能的依赖长度随块的长度n和层数L呈线性增长(与开头提到的平方级增长形成对比),即 ,如下图(b)中的阴影部分所示。这种机制和RNN中常用的随时间反向传播机制(Back Propagation Through Time,BPTT)类似。然而,在这里是将整个序列的隐含层状态全部缓存,而不是像BPTT机制中只会保留最后一个状态。
,如下图(b)中的阴影部分所示。这种机制和RNN中常用的随时间反向传播机制(Back Propagation Through Time,BPTT)类似。然而,在这里是将整个序列的隐含层状态全部缓存,而不是像BPTT机制中只会保留最后一个状态。

另外,这种设计除了能够处理更长的文本序列,还能加快测试速度。作者通过一系列的实验表明,Transformer-XL相比传统Transformer,能够在测试阶段达到1800倍以上的加速。
3.2 相对位置编码
虽然状态复用的块级别循环技术能够将不同块之间的信息联系起来,但在实际应用中还存在一个非常重要的问题:如何区分不同块中的相同位置(如第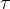 块和第
块和第 块中的第二个位置)?采用传统Transformer中的绝对位置编码方法是不可行的,其原因可通过下式说明:
块中的第二个位置)?采用传统Transformer中的绝对位置编码方法是不可行的,其原因可通过下式说明:
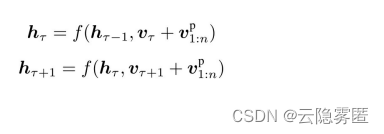
式中,  表示块
表示块 对应的词向量;
对应的词向量; 表示位置向量;f 表示变换函数。
可以看到对于不同的块,使用的位置向量是一样的。例如,对于第
τ 块中的
表示位置向量;f 表示变换函数。
可以看到对于不同的块,使用的位置向量是一样的。例如,对于第
τ 块中的 和第 τ+1 块中的
和第 τ+1 块中的 的位置信息是完全相同的,而这
显然是不合理的。
的位置信息是完全相同的,而这
显然是不合理的。
为了解决这个问题,Transformer-XL引入了
相对位置编码
策略。位置信息的重要性主要体现在注意力矩阵的计算上,用于构建不同词之间的关联关系。应用相对位置编码后,第i个词与第j个词的注意力值 为:
为:
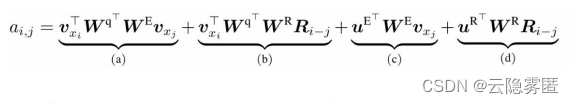
式中,W 和 表示可训练的权重;
表示可训练的权重;  表示词xi对应的词向量;
表示词xi对应的词向量; 表示相对位置矩阵(N表示最大编码长度),是一个不可训练的正弦编码矩阵,其第i行表示相对位置间隔为i的位置向量。接下来针对上式中的各个部分进行介绍。
表示相对位置矩阵(N表示最大编码长度),是一个不可训练的正弦编码矩阵,其第i行表示相对位置间隔为i的位置向量。接下来针对上式中的各个部分进行介绍。
基于内容的相关度(a):计算查询xi与键xj的内容之间关联信息;
内容相关的位置偏置(b):计算查询xi的内容与键xj的位置编码之间的关联信息,表示两者的相对位置信息,表示取R中的第i−j行;
全局内容偏置(c):计算查询xi的位置编码与键xj的内容之间的关联信息;
全局位置偏置(d):计算查询xi与键xj的位置编码之间关联信息。
想深入学习的读者可以参考下方论文链接了解更多细节部分,同时模型代码也一并附加到文章顶部。