simple RNN pytorch代码实现
在写这篇博客之前,博主要说一件事情,网上的simple RNN代码很多都是错误的,博主的也是错误的,为什么呢?
因为simple RNN的梯度下降代码必须自己去写,simple RNN的梯度下降不能使用pytorch的默认机制,否则会直接出现梯度消失,博主做了很多实验,一开始一直以为是代码写错了,后面发现,simple RNN不能使用一般的梯度下降算法去做,必须使用随时间梯度下降算法去实现,也就是如果你要复现simple RNN需要自己去写梯度下降代码,不能直接搭建模型训练。不过呢,使用两三层的simple RNN还可以,因为梯度消失还不严重,这里,我们给出我们的代码:
#coding=gbk
import torch
from torch.autograd import Variable
import os
from torch.utils import data
import matplotlib.pyplot as plt
import torch.nn.functional as F
import numpy as np
import torch.nn as nn
sample_num=1000
sequense_num=10
input_length=10
train_de_test=0.8
hidden_size=10
num_epochs=100
batch=32
learning_rate=0.01
#torch.manual_seed(10)
x_data=[]
y_data=[]
for i in range(sample_num):
if i%2==0:
x_gene=torch.randint(0,5,(sequense_num,input_length))
y_data.append(1)
else:
x_gene=torch.randint(6,10,(sequense_num,input_length))
# y=torch.sum(x_gene)
# y_data.append(1)
y_data.append(0)
x_data.append(x_gene)
x_data=torch.stack((x_data),0)
x_data=x_data.type(dtype=torch.float32)
y_data=torch.as_tensor(y_data)
print(x_data,y_data)
print(x_data.size())
# 神经网络搭建
class sRNN(nn.Module):
def __init__(self, sequense_num,input_length,hidden_size):
super().__init__()
self.sequense_num=sequense_num
self.input_length=input_length
self.hidden_size=hidden_size
self.W = torch.nn.Parameter(data=torch.randn(input_length, hidden_size, requires_grad=True))
self.U = torch.nn.Parameter(data=torch.randn(input_length, hidden_size, requires_grad=True))
self.b = torch.nn.Parameter(data=torch.randn( 1,hidden_size, requires_grad=True))
self.V = torch.nn.Parameter(data=torch.randn(hidden_size,1 , requires_grad=True))
self.f=nn.Sigmoid()
def forward(self,input):#d就是整个网络的输入
hidden_state_pre=torch.zeros(1, hidden_size)
for i in range(sequense_num):
# print(torch.matmul(self.W,input[:,i,:]))
z=torch.matmul(hidden_state_pre,self.U)+torch.matmul(input[:,i,:],self.W)+ self.b
hidden_state_pre=F.relu(z)
# print(hidden_state_pre)
y=self.f(torch.matmul(hidden_state_pre,self.V))
return y
def backward(self):
pass
loss_fn = nn.BCELoss()
def sampling(sample_num):
index_sequense=torch.randperm(sample_num)
return index_sequense
def get_batch(index_sequense,X_data,Y_data,index,bacth):
return X_data[index:index+bacth],Y_data[index:index+bacth]
srnn=sRNN(sequense_num,input_length,hidden_size)
loss_fn = nn.BCELoss()
index_sequense=sampling(sample_num)
optimizer = torch.optim.Adam(srnn.parameters(), lr=0.1)
co=0
for param_tensor in srnn.state_dict(): # 字典的遍历默认是遍历 key,所以param_tensor实际上是键值
print(param_tensor,'\t',srnn.state_dict()[param_tensor].size())
print(srnn.state_dict()[param_tensor])
acc_list=[]
index=0
index_sequense=torch.randperm(sample_num)
loss_list=[]
for k in range(num_epochs):
if index+batch>=sample_num-1:
index=0
index_sequense=torch.randperm(sample_num)
x_batch,y_batch=get_batch(index_sequense,x_data,y_data,index,batch)
y_batch=y_batch.type(dtype=torch.float32)
y_batch=y_batch.reshape(batch,1)
# print(x_batch)
predict=srnn(x_batch)
co=torch.sum(torch.abs(y_batch-predict)<0.5)
loss = loss_fn(predict,y_batch)
index=index+batch
optimizer.zero_grad()
loss.backward()
optimizer.step()
for p in srnn.parameters():
# p.data.add_(p.grad.data, alpha=-learning_rate)
# print("p.data",p.data)
print("p.grad.data",p.grad.data)
# print(predict)
# print(y_batch-predict)
print("loss :",loss)
print("accuracy :",co/batch)
loss_list.append(loss)
acc_list.append(co/batch)
#except:
# index=0
# index_sequense=torch.randperm(sample_num)
#optimizer.zero_grad()
#loss.backward()
#
#print(x_batch,y_batch)
x_batch,y_batch=get_batch(index_sequense,x_data,y_data,0,batch)
print(x_batch.size())
print("#")
print(srnn(x_batch))
#y_batch=y_batch.type(dtype=torch.float32)
#train(x_data,y_data,num_epochs,batch)
epoch_list=list(range(num_epochs))
plt.plot(epoch_list,acc_list,label='adam')
plt.title("loss")
plt.legend()
plt.show()
plt.plot(epoch_list,loss_list,label='adam')
plt.title("loss")
plt.legend()
plt.show()
#print(srnn.parameters())
#print(type(srnn.state_dict())) # 查看state_dict所返回的类型,是一个“顺序字典OrderedDict”
#for param_tensor in srnn.state_dict(): # 字典的遍历默认是遍历 key,所以param_tensor实际上是键值
# print(param_tensor,'\t',srnn.state_dict()[param_tensor].size())
# print(srnn.state_dict()[param_tensor])
os.system("pause")
运行结果:
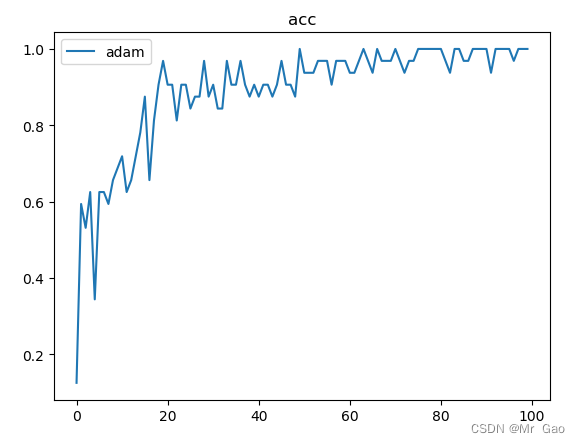
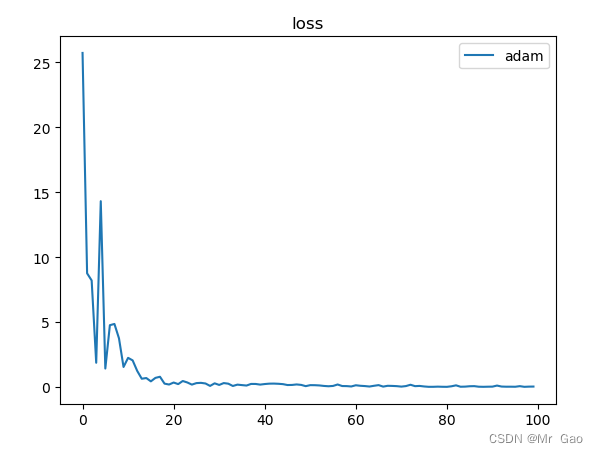
上面代码并不时完全正确的simple RNN代码,不过大家需要完善梯度下降算法就可以了。反向的去计算随时间的梯度就可以了。