文章目录
1 xgboost 是什么
全称:eXtreme Gradient Boosting
作者:陈天奇(华盛顿大学博士)
基础:GBDT
所属:boosting迭代型、树类算法。
适用范围:分类、回归
优点:速度快、效果好、能处理大规模数据、支持多种语言、支 持自定义损失函数等等。
缺点:发布时间短(2014),工业领域应用较少,待检验
2 基础知识GBDT
xgboost是在GBDT的基础上对boosting算法进行的改进,内部决策树使用的是回归树,简单回顾GBDT如下:

回归树的分裂结点对于平方损失函数,拟合的就是残差;对于一般损失函数(梯度下降),拟合的就是残差的近似值,分裂结点划分时枚举所有特征的值,选取划分点。
最后预测的结果是每棵树的预测结果相加。
3 xgboost算法原理知识
3.1 定义树的复杂度

把树拆分成结构部分q和叶子权重部分w。 树的复杂度函数和样例:
定义树的结构和复杂度的原因很简单,这样就可以衡量模型的复杂度了啊,从而可以有效控制过拟合。

3.2 xgboost中的boosting tree模型

和传统的boosting tree模型一样,xgboost的提升模型也是采用的残差(或梯度负方向),不同的是分裂结点选取的时候不一定是最小平方损失。

3.3 对目标函数的改写

最终的目标函数只依赖于每个数据点的在误差函数上的一阶导数和二阶导数。这么写的原因很明显,由于之前的目标函数求最优解的过程中只对平方损失函数时候方便求,对于其他的损失函数变得很复杂,通过二阶泰勒展开式的变换,这样求解其他损失函数变得可行了。很赞!
当定义了分裂候选集合的时候,

求解:

3.4 树结构的打分函数
Obj代表了当指定一个树的结构的时候,在目标上面最多减少多少。(structure score)

对于每一次尝试去对已有的叶子加入一个分割
这样就可以在建树的过程中动态的选择是否要添加一个结点。
假设要枚举所有x < a 这样的条件,对于某个特定的分割a,要计算a左边和右边的导数和。对于所有的a,我们只要做一遍从左到右的扫描就可以枚举出所有分割的梯度和GL、GR。然后用上面的公式计算每个分割方案的分数就可以了。


3.5 寻找分裂结点的候选集
1、暴力枚举
2、近似方法 ,近似方法通过特征的分布,按照百分比确定一组候选分裂点,通过遍历所有的候选分裂点来找到最佳分裂点。
两种策略:全局策略和局部策略。在全局策略中,对每一个特征确定一个全局的候选分裂点集合,就不再改变;而在局部策略中,每一次分裂 都要重选一次分裂点。前者需要较大的分裂集合,后者可以小一点。对比补充候选集策略与分裂点数目对模型的影响。 全局策略需要更细的分裂点才能和局部策略差不多
3、Weighted Quantile Sketch
陈天奇提出并从概率角度证明了一种带权重的分布式的Quantile Sketch。

4 xgboost的改进点总结
- 目标函数通过二阶泰勒展开式做近似
- 定义了树的复杂度,并应用到目标函数中
- 分裂结点处通过结构打分和分割损失动态生长
- 分裂结点的候选集合通过一种分布式Quantile Sketch得到
- 可以处理稀疏、缺失数据
- 可以通过特征的列采样防止过拟合
5 XGBoosting案例:金融反欺诈模型
信用卡盗刷一般发生在持卡人信息被不法分子窃取后复制卡片进行消费或信用卡被他人冒领后激活并消费等情况下。一旦发生信用卡盗刷,持卡人和银行都会遭受一定的经济损失。因此,通过大数据技术搭建金融反欺诈模型对银行来说尤为重要。
5.1 模型搭建
XGBoost算法既能做分类分析,又能做回归分析,对应的模型分别为XGBoost分类模型(XGBClassifier)和XGBoost回归模型(XGBRegressor)。
这里以分类模型为例简单演示使用。
5.1.1 读取数据
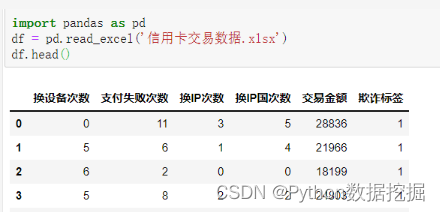
通过如下代码读取1000条客户信用卡的交易数据。
特征变量有客户换设备次数、在本次交易前的支付失败次数、换IP的次数、换IP国的次数及本次交易的金额。
目标变量是本次交易是否存在欺诈,若是盗刷信用卡产生的交易则标记为1,代表欺诈,正常交易则标记为0。
其中有400个欺诈样本,600个非欺诈样本。
5.1.2 特征变量与目标变量提取、划分数据集与测试集
X = df.drop(columns='欺诈标签')
y = df['欺诈标签']
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,y,test_size=0.2,random_state=123)
5.1.3 模型搭建及训练
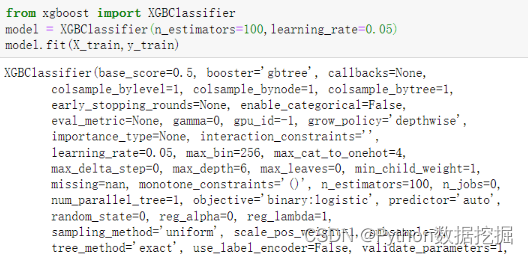
第2行代码将XGBClassifier()赋给变量model,并设置弱学习器的最大迭代次数,或者说弱学习器的个数n_estimators参数为100,以及弱学习器的权重缩减系数learning_rate为0.05,其余参数都使用默认值。
5.2 模型预测及评估
模型搭建完毕后,通过如下代码对测试集数据进行预测。
通过如下代码可以汇总预测值和实际值,以便进行对比。
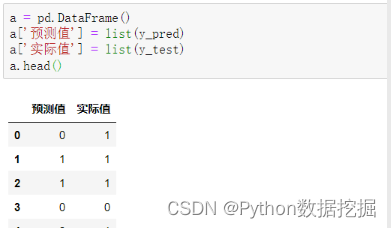
可以看到,前5项的预测准确度为60%。通过如下代码可以查看所有测试集数据的预测准确度。
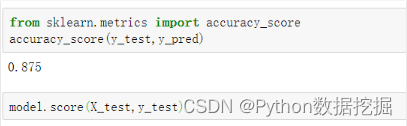
XGBoost分类模型在本质上预测的并不是准确的0或1的分类,而是预测样本属于某一分类的概率,可以用predict_proba()函数查看预测属于各个分类的概率,代码如下。
y_pred_proba = model.predict_proba(X_test)
y_pred_proba[:,1]
获得的y_pred_proba是一个二维数组,其中第1列为分类为0(即非欺诈)的概率,第2列为分类为1(即欺诈)的概率,如上是查看欺诈(分类为1)的概率。
下面通过绘制ROC曲线来评估模型的预测效果,代码如下。
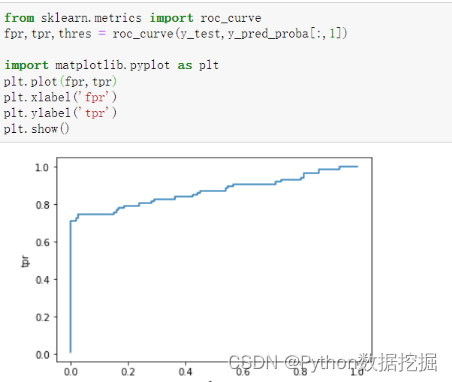
通过如下代码计算模型的AUC值。

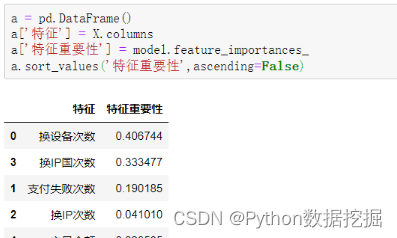
通过如下代码可以查看各个特征变量的特征重要性,以便筛选出信用卡欺诈行为判断中最重要的特征变量。
5.3 模型参数调优
使用GridSearch网格搜索进行参数调优。
from sklearn.model_selection import GridSearchCV
parameters = {
'max_depth':[1,3,5],'n_estimators':[50,100,150],'learning_rate':[0.01,0.05,0.1,0.2]}
model = XGBClassifier()
grid_search = GridSearchCV(model,parameters,scoring='roc_auc',cv=5)
grid_search.fit(X_train,y_train)
grid_search.best_params_
# 输出最佳参数
# {'learning_rate': 0.05, 'max_depth': 1, 'n_estimators': 100}
从上述结果可以看出,针对本案例的数据,弱学习器决策树的最大深度限制为1,弱学习器的最大迭代次数设置为100,弱学习器的权重缩减系数设置为0.05时,模型的预测效果最佳。